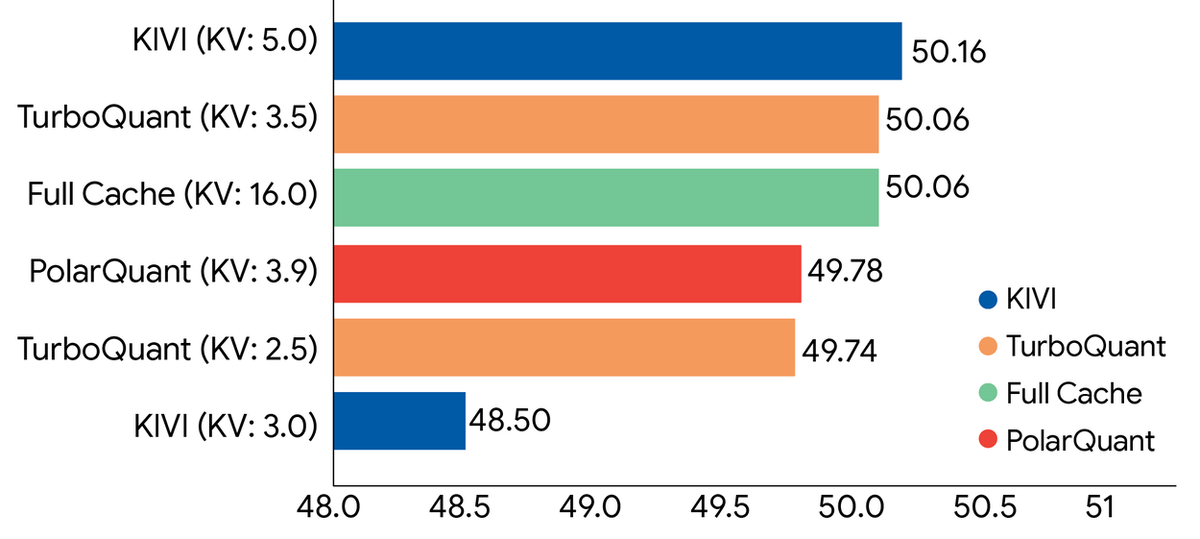
Исследователи из Google анонсировали набор новых алгоритмов для значительного сжатия больших языковых моделей и поисковых систем на основе векторов. Главным нововведением стал алгоритм TurboQuant, который решает проблему нехватки памяти при работе с искусственным интеллектом. Технология позволяет уменьшить объем кэша в 6 раз без потери точности.
Обычно векторы содержат сложные данные об изображениях или тексте, но они занимают слишком много места. Это приводит к задержкам в работе быстрой памяти. Традиционные методы сжатия создают дополнительную нагрузку на систему. В основе работы TurboQuant лежат 2 других алгоритма. Метод PolarQuant переводит векторы в полярную систему координат и применяет надежное квантование. Следом алгоритм QJL тратит ровно 1 бит на устранение скрытых ошибок и повышение точности.
Новые технологии прошли тестирование на популярных бенчмарках с моделями Gemma и Mistral. Результаты показали, что TurboQuant способен сжимать кэш до 3 битов без необходимости дополнительного обучения. При использовании формата на 4 бита скорость вычислений на ускорителях H100 возрастает до 8 раз по сравнению с несжатыми ключами на 32 бита. Разработка также показывает превосходные результаты в поиске по огромным базам данных.
Разработчики отмечают, что представленные методы имеют под собой строгую математическую базу. Внедрение TurboQuant поможет улучшить семантический поиск и работу крупных нейросетей уровня Gemini. Ожидается, что подробности будут представлены на конференциях ICLR 2026 и AISTATS 2026.