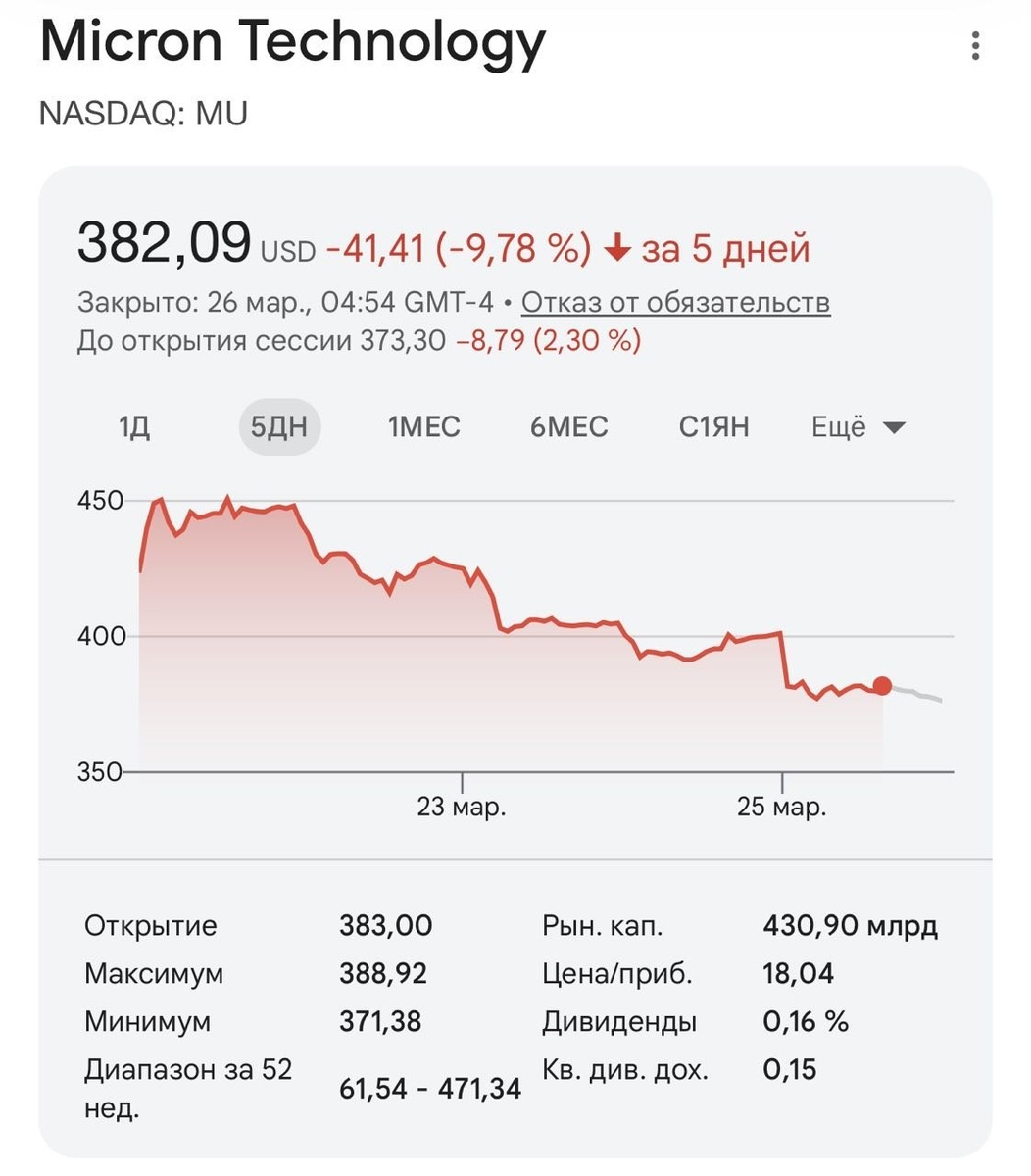
Google разработала алгоритм сжатия TurboQuant для LLM-моделей, который снижает требования к KV cache — памяти, необходимой нейросети для хранения предыдущих токенов при генерации текста. С новым алгоритмом: • требования к памяти уменьшаются в 6 раз; • скорость работы увеличивается в 8 раз; • точность модели не снижается. Новость повлияла на акции производителей памяти, таких как Micron и SK Hynix. https://dzen.ru/id/5c0e38ff46ef5c00aaa80527
Google представила алгоритм сжатия для LLM TurboQuant
Google разработала алгоритм сжатия TurboQuant для LLM-моделей, который снижает требования к KV cache — памяти, необходимой нейросети для хранения предыдущих токенов при генерации текста.
С новым алгоритмом:
• требования к памяти уменьшаются в 6 раз;
• скорость работы увеличивается в 8 раз;
• точность модели не снижается.
Новость повлияла на акции производителей памяти, таких как Micron и SK Hynix.
https://dzen.ru/id/5c0e38ff46ef5c00aaa80527