Большое обновление от Сбера
Gigachat выпустили в опенсорс свои две новые модели, сразу по ним пройдемся
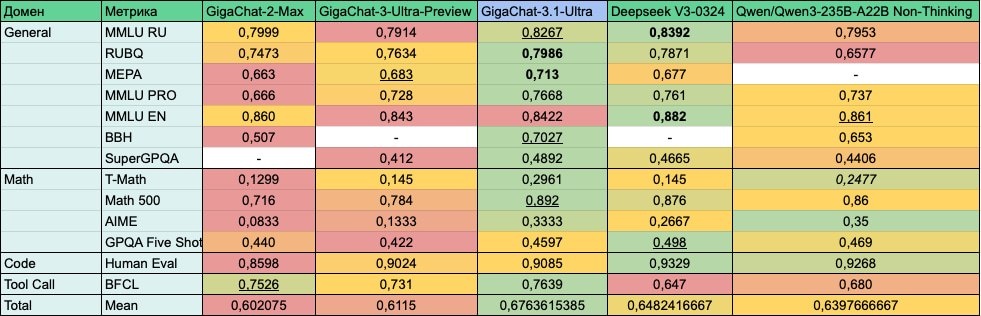
🔘GigaChat-3.1-Ultra (702B MoE)
- Обходит non-reasoning Qwen3-235B-A22B и DeepSeek-V3-0324 в математике и general reasoning
- На аренах обошел DeepSeek-V3-0324 и выходит на уровень Qwen3-235B-A22B-Non-Thinking
- Лидер среди non-reasoning моделей в Math, General Reasoning, Function Calling, Coding, Vision
🔘GigaChat-3.1-Lightning (10B MoE, 1.8 млрд активных параметров)
- Играет на уровне GPT-4o на аренах с судьёй GPT-4.1
- Превосходит конкурентов по скорости
- Output: 3 958 tps | Total: 8 054 tps в FP8 + MTP
Плюс много всяких дополнительных улучшений и ускорений
🔘В статье у себя рассказали как боролись с багами всякими и трудностями
При переходе от Dense к MoE-архитектуре модели стали зацикливаться, выдавая тексты вроде: "…Пальмы. Пальмы. Пальмы. И жара, жара, жара. И океан, океан, океан…"
Решили они это измерением циклов, если модель зациклилась, конец генерации хорошо сжимается (много повторяющихся паттернов). Если текст разнообразный сжимать нечего. Итоговая метрика отношение длины хвоста после BPE-подобного сжатия к исходной длине
🔘DPO в нативном FP8: качество выше BF16
Квантизация до FP8 сохраняла качество на простых бенчмарках (MMLU), но проигрывала BF16 на аренах с длинными генерациями, ошибки квантования накапливаются в residual stream
Нативно обучили DPO в FP8 и использованием DeepGemm от дипсиков и самописных cuda ядер и как итог качество выше BF16 при вдвое меньшем потребление памяти
В общем за четыре месяца после ноябрьского preview команда пересобрала весь пайплайн постобучения, победила циклы, улучшила результаты на аренах и бенчмарках, перевела DPO в FP8, автоматизировала замеры и нашла критичный баг в SGLang