Хватит говорить нейросетям, что они Senior-разработчики 🛑
Наверняка вы все используете одно из базовых правил промпт-инжиниринга: начинайте запрос с фразы типа «Представь, что ты Senior Python Developer сд 100 годами опыта в Google». Да, я тоже так делаю.
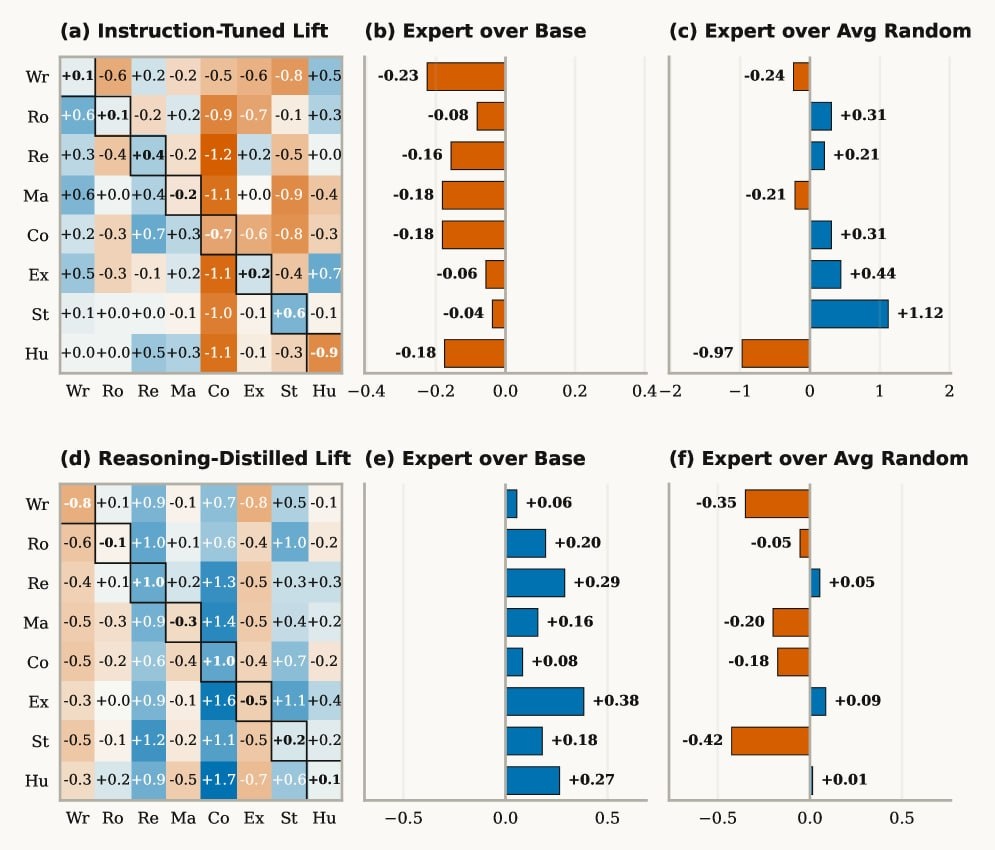
Так вот, выкатили свежее исследование от USC, которое доказывает, что такие фразы делают модель тупее в написании кода.
Почему так? 🧐
Сырые знания (факты, алгоритмы, логика) закладываются в модель на этапе pretraining. А вот умение отыгрывать роль, следовать формату и быть безопасной — это результат instruction-tuning (SFT/RLHF).
Когда вы пишете You are an expert..., вы переводите модель в режим жесткого следования инструкциям. Ее внутренние веса смещаются в сторону поддержания этой маски (alignment-задачи). Модель тратит «вычислительный ресурс» на то, чтобы звучать как эксперт, вместо того чтобы думать как эксперт. Происходит интерференция: instruction-following паттерны подавляют нейронные пути, отвечающие за извлечение чистых фактов из претрейна.
Цифры из пейпы: на бенчмарках вроде MMLU и задачах на кодинг/математику базовая модель с голым промптом стабильно обходит модель с навешанной персоной (68% против 71.6% accuracy). Нейронка буквально тупеет в логике, пытаясь генерировать уверенный в себе, красиво структурированный булшит. Особенно сильно этот эффект бьет по reasoning-моделям вроде DeepSeek-R1, ломая им цепочки рассуждений.
Значит ли это, что персоны вообще не нужны? Нет.
Исследование четко разделяет задачи:
1️⃣ Где персона вредит (Pretraining-dependent tasks):
Кодинг, математика, извлечение сырых фактов, логические загадки.
Как надо: Дайте голый контекст и четкую задачу. Никаких «ты эксперт».
2️⃣ Где персона работает (Alignment-dependent tasks):
Написание текстов, форматирование (собрать данные в JSON определенной структуры), тон общения и, как ни странно, safety (отказы писать эксплойты).
Как надо: Здесь Ты — строгий критик или Ты — технический писатель реально улучшит структуру ответа.
Для тех, кто хочет вкопаться глубже: исследователи даже собрали костыль PRISM — LoRA-адаптер с гейтом, который на лету включает персону для форматирования и вырубает её, когда дело доходит до хардкорного кодинга и фактов.
В общем, теперь знаем, что если вам нужен работающий код или решение сложной архитектурной задачи — перестаем уговаривать железяку, что она гений. Просто нормально пишем ТЗ.