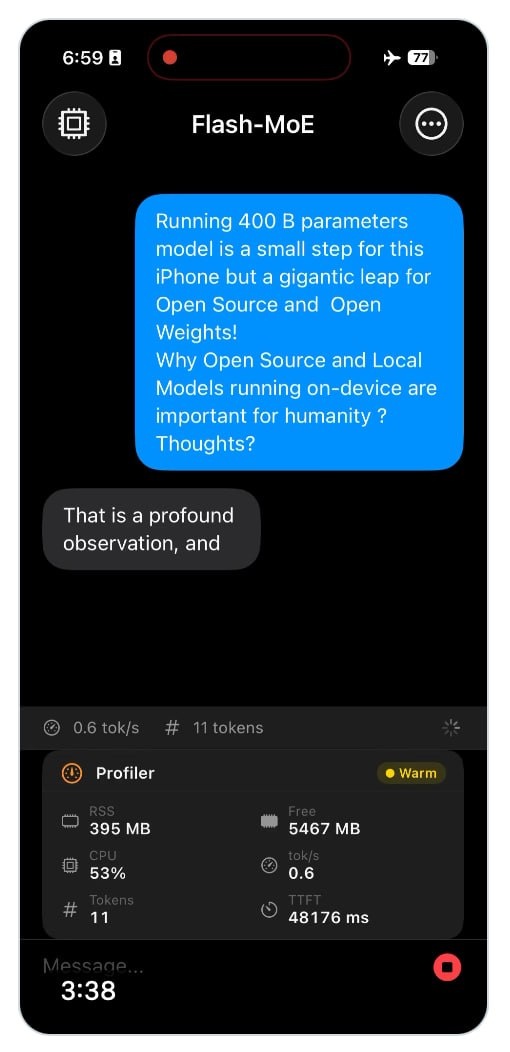
На iPhone смогли втиснуть гигантскую языковую модель ИИ на 400 миллиардов параметров
В сети X показывают работу большой языковой модели Qwen3.5-397B, которую пытливые энтузиасты смогли развернуть непосредственно на айфоне. Судя по видео, нейросеть функционирует локально через приложение LM Studio, обрабатывая запросы со скоростью около 0,6 токена в секунду — примерно одно слово каждые две секунды. Публикация вызвала бурную реакцию — от восторженных возгласов до откровенного недоверия. Впрочем, технические подробности из репозитория на GitHub подтверждают реальность эксперимента и раскрывают впечатляющие детали реализации.
Речь идет о запуске нейросети с 397 миллиардами параметров — и это очень много. Энтузиасты создали специализированный движок, который считывает данные напрямую с накопителя смартфона, поскольку уместить всю информацию в оперативной памяти физически невозможно. Чтобы хоть как-то втиснуть гиганта в iPhone, разработчики применили агрессивное сжатие — каждое число в нейросети закодировано всего тремя битами вместо стандартных 16 или 32. На настольном компьютере Mac Studio с топовым процессором M5 Max и 128 гигабайтами памяти система выдает почти 13 слов в секунду, что уже приближается к комфортной скорости чтения. На смартфоне же производительность проседает в 20 раз из-за необходимости постоянно подгружать данные с относительно медленного накопителя.
Разработчики измеряли качество работы через специальный показатель — перплексию, которая отражает способность нейросети угадывать следующее слово в тексте. Чем цифра ниже, тем умнее получаются ответы. Сжатая до трех бит версия показала результат 3,81 против 3,64 у менее агрессивного сжатия — разница небольшая, зато скорость выросла на треть. Еще более радикальное двухбитное сжатие ускоряет работу до 14,5 слов в секунду, но качество падает настолько, что нейросеть начинает откровенно нести чушь в сложных рассуждениях.
Комментаторы справедливо отмечают непрактичность затеи. Кто-то там метко сравнивает ситуацию с нюханием пиццы вместо ее поедания — технически возможно, но удовольствия никакого. При скорости 0,6 токена в секунду генерация ответа из 100 слов займет почти три минуты, что превращает диалог с искусственным интеллектом в мучительное ожидание.
Практическая ценность эксперимента сомнительна, но он наглядно демонстрирует возможности процессоров Apple для автономной работы с искусственным интеллектом. Система читает с накопителя около 1,3 гигабайта на каждое сгенерированное слово — примерно как скачивать фильм в высоком качестве каждую секунду. Неудивительно, что даже самые быстрые смартфонные накопители задыхаются под такой нагрузкой. Возможно, в будущем подобные технологии станут практичнее, но пока это скорее демонстрация того, что теоретически возможно выжать из железа Apple, а не руководство к действию для обычных пользователей.