Компании, которые строят серьезные AI системы, давно сталкиваются с одной и той же головной болью. Настройка окружения занимает дни, модели работают нестабильно, а требования к безопасности и воспроизводимости превращают каждый запуск в настоящий лабиринт. Теперь этот путь стал прямым и управляемым. Anaconda объявила о расширении своих GPU окружений для открытых моделей и полной интеграции семейства NVIDIA Nemotron. Результат получился именно таким, какого ждали предприятия. От первого запуска окружения до развертывания модели все происходит под строгим контролем, без лишних рисков и неожиданных сбоев.
Объявление на фоне конференции GTC 2026
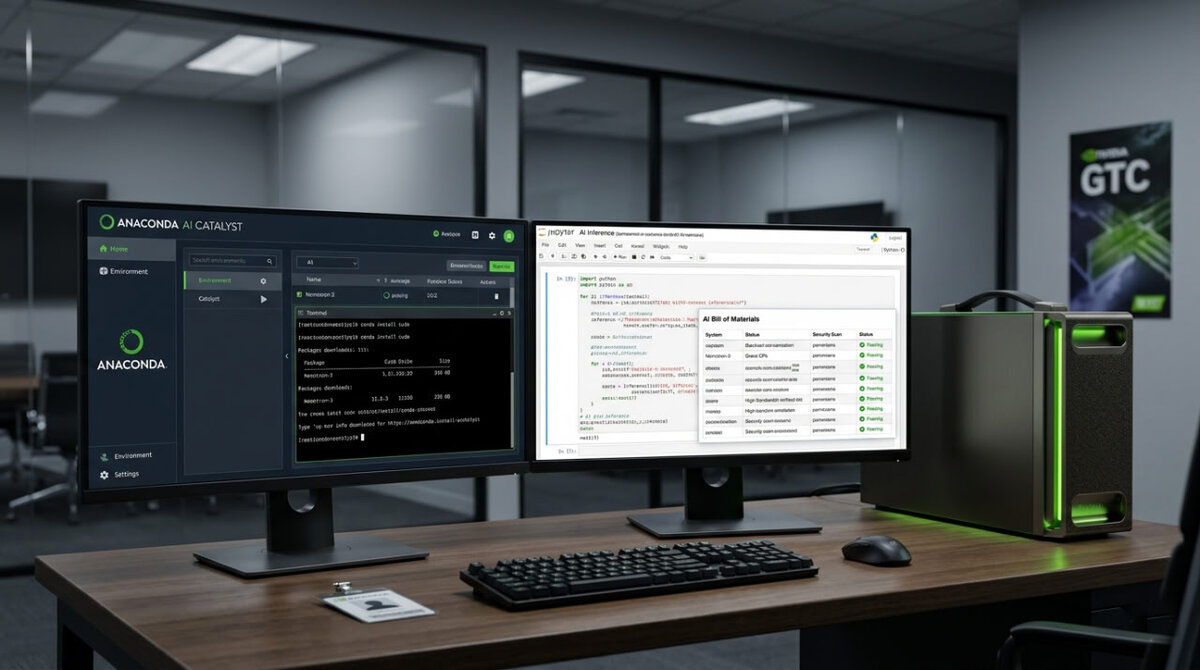
Конференция NVIDIA GTC 2026 только закончилась, а новость уже разошлась по всем командам разработчиков. Anaconda показала, как ее платформа AI Catalyst теперь охватывает полный enterprise AI стек. От ускоренных GPU окружений до готовых открытых моделей. Nemotron модели, оптимизированные для рассуждений и агентных задач, стали доступны прямо внутри экосистемы Anaconda. Это не просто добавление пары пакетов. Это переход к единому управляемому процессу, где каждая деталь проверена и воспроизводима. Раньше разработчики тратили недели на согласование версий CUDA и моделей. Сегодня достаточно нескольких команд, чтобы запустить безопасную среду и сразу перейти к работе.
Многие команды уже знают, как легко потерять контроль, когда модели живут отдельно от окружения. Здесь же все связано одной нитью. Nemotron 2 и Nemotron 3 с квантизацией интегрированы так, что их можно загружать, тестировать и развертывать без выхода из защищенной платформы. Это как получить надежный фундамент, на котором можно строить без опасений за трещины.
Автоматизация CUDA устраняет типичные проблемы настройки
Самая большая головная боль в GPU разработке всегда была в установке. Нужно вручную подбирать версии CUDA, cuBLAS, cuDNN и NCCL, следить за совместимостью драйверов и надеяться, что ничего не сломается при переходе на прод. Anaconda решила это радикально. Теперь conda автоматически определяет версию GPU драйвера и подбирает точный комплект зависимостей. Установка PyTorch или TensorFlow одним пакетом тянет за собой весь протестированный стек. Никаких ручных команд, никаких конфликтов.
Поддержка CUDA 12.8 уже в работе, а версии 13.1 появятся сразу после обновлений фреймворков. Платформа охватывает PyTorch с первой Windows CUDA версией в 2.7.0, TensorFlow, llama.cpp, ONNX Runtime и JAXlib. Скоро добавятся дополнительные пакеты для Windows и Linux на ARM64. Это особенно важно для новых устройств вроде NVIDIA DGX Spark. Разработчик просто запускает окружение и сразу получает готовую к работе среду. Время от первой команды до первого обучения сокращается с дней до минут.
Представьте, как раньше приходилось собирать пазл из десятков компонентов. Теперь все детали уже собраны и проверены производителем. Контраст огромный. Команды больше не тратят силы на отладку инфраструктуры. Они сосредотачиваются на моделях и задачах.
Nemotron модели получают полный контроль governance в AI Catalyst
Семейство Nemotron создано NVIDIA специально для эффективных и точных агентных систем. Теперь эти модели живут внутри AI Catalyst с теми же правилами, что и обычные Python пакеты. Полный AI bill of materials дает прозрачность каждого компонента. Сканирование уязвимостей, документация соответствия и контроль воспроизводимости распространяются и на модели. Открытая лицензия гарантирует коммерческое использование и полную защиту данных.
Разработчик может загрузить notebook, запустить inference на Nemotron и быть уверенным, что окружение останется идентичным на продакшене. CUDA стек проверяется на совместимость автоматически. Это значит, что модель работает ровно так, как ожидалось, независимо от того, где она запущена. Локально или в облачном VPC. Такой подход закрывает главную боль enterprise проектов. Теперь governance не требует отдельных инструментов и процессов. Все уже встроено и работает из коробки.
Можно задать себе вопрос. Почему раньше модели часто становились слабым звеном? Потому что они жили отдельно от окружения. Сегодня они часть одной системы. Это меняет правила игры для команд, где compliance не просто рекомендация, а обязательное условие.
Вот что именно получает каждая команда после интеграции:
- Полная прозрачность через AI bill of materials;
- Автоматическое сканирование уязвимостей для моделей;
- Гарантированная воспроизводимость от разработки до продакшена;
- Проверенная совместимость с GPU окружением.
Эти пункты не просто список. Они решают реальные проблемы, с которыми сталкивается каждый, кто строит крупные AI системы.
Поддержка DGX Spark открывает локальную работу без облака
NVIDIA DGX Spark стал настоящим прорывом для тех, кто хочет мощь суперкомпьютера на рабочем столе. 128 гигабайт единой CPU GPU памяти позволяют запускать большие Nemotron модели локально. Anaconda добавила официальную поддержку этого устройства. Теперь можно развернуть полностью изолированное окружение без зависимости от облака и без утечки данных.
Демонстрация на GTC 2026 в booth 3001 показала именно это. Полностью локальный AI coding assistant работает на DGX Spark. Модель, которая раньше требовала целую стойку серверов, помещается в компактный корпус размером с небольшой чемодан. Запуск окружения занимает минуты. Conda берет на себя все настройки CUDA. Разработчик сразу загружает notebook и запускает inference. Никаких облачных счетов, никаких рисков конфиденциальности.
Это особенно ценно для компаний с жесткими требованиями к данным. Теперь можно разрабатывать, тестировать и даже обучать модели прямо на рабочем месте. Переход в продакшен происходит без сюрпризов, потому что окружение остается тем же самым. Контраст с традиционными подходами разительный. Раньше локальные эксперименты часто расходились с облачными развертываниями. Сегодня они идентичны.
Преимущества для команд разработчиков и платформ
Data scientists наконец могут сосредоточиться на обучении и fine tuning вместо борьбы с версиями. ML инженеры получают окружения, которые работают одинаково на любом hardware. Platform teams доставляют GPU ускорение и модели с полным набором audit trails и security controls. Все это без компромиссов по стабильности.
Интеграция упрощает использование крупных моделей в сценариях, где governance стоит на первом месте. Безопасность данных, воспроизводимость процессов и прозрачность становятся встроенными свойствами, а не отдельными задачами. Команды тратят меньше времени на инфраструктуру и больше на создание ценности. Это особенно заметно в проектах с агентными системами, где Nemotron показывает свои сильные стороны в рассуждениях и сложных задачах.
Многие замечали, как раньше проекты тормозили на этапе настройки. Теперь этот барьер исчез. Разработка течет плавно от идеи до работающего решения. Это вдохновляет команды идти дальше и пробовать более амбициозные сценарии.
Что это дает предприятиям с высокими требованиями к безопасности
В итоге предприятия получают управляемый и воспроизводимый путь от сетапа до деплоя. GPU и крупные модели перестают быть источником рисков. Они становятся надежным инструментом под полным контролем. Данные остаются внутри компании, compliance соблюдается автоматически, а производительность растет без лишних затрат.
Такой подход открывает новые возможности для тех, кто строит AI на серьезном уровне. Nemotron модели в сочетании с автоматизированными GPU окружениями позволяют создавать системы, которые раньше казались слишком сложными для enterprise. Каждый шаг проверен, каждая зависимость учтена. Это не просто техническое улучшение. Это фундамент для следующего поколения AI приложений, где скорость и безопасность идут рука об руку.
Открытие этой интеграции показывает, как два лидера отрасли могут вместе решить то, что раньше останавливало многих. Теперь путь от идеи до работающей модели стал короче, безопаснее и предсказуемее. Команды, которые уже попробовали новый стек, отмечают, как меняется ритм работы. Проблемы, которые раньше отнимали недели, решаются за часы. А это значит, что настоящие прорывы в enterprise AI становятся ближе, чем когда либо. Дальше картина будет только яснее, и каждое новое обновление добавит еще больше уверенности в том, что крупные модели можно использовать по настоящему надежно и эффективно.