Твоя база данных может работать медленнее из-за одной настройки
В мире PostgreSQL уже почти 25 лет используется параметр random_page_cost со значением 4.0. Этот параметр определяет, насколько «дорогими» считаются случайные чтения по сравнению с последовательными при построении плана выполнения запросов.
Проблема в том, что это значение давно устарело. Эксперименты на современных SSD показывают, что реальная разница между случайным и последовательным вводом-выводом может достигать 25–35 раз, а не 4.
Это приводит к системной ошибке в планировщике запросов. Он недооценивает стоимость случайного доступа и чаще выбирает последовательное сканирование таблицы вместо использования индексов.
На практике это особенно заметно при выборках с селективностью от примерно 0.2 до 2.2 процента. В этих диапазонах система может принимать неоптимальные решения и выполнять более медленные операции.
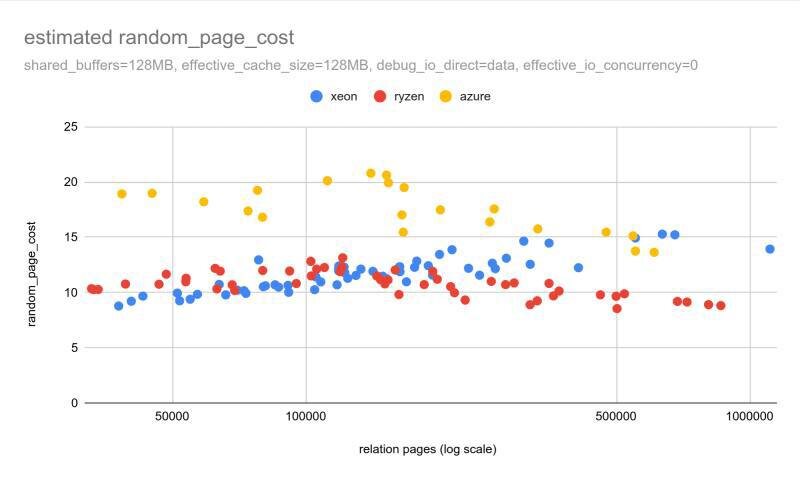
Если увеличить значение random_page_cost примерно до 30, оценки планировщика начинают гораздо лучше соответствовать реальному времени выполнения запросов.
Однако ситуация не такая однозначная. В OLTP-сценариях с высоким процентом попаданий в кэш снижение этого параметра всё ещё может быть оправдано. В таких условиях случайный доступ часто происходит из памяти, а не с диска, и становится быстрее полного сканирования таблицы.
Дополнительную сложность вносит механизм предварительной выборки данных, или prefetching. Он значительно ускоряет последовательные и bitmap-сканы, но практически не помогает индексным сканам.
При этом текущая модель стоимости в PostgreSQL вообще не учитывает влияние prefetching. Из-за этого планировщик ещё сильнее искажает реальную картину производительности.
Авторы предлагают несколько направлений улучшения. Разделить вычислительные и I/O-затраты, улучшить статистику кэша и добавить учёт prefetching в модель планирования.
Современные системы хранения изменились, а параметры оптимизации остались прежними. И это напрямую влияет на производительность запросов.
#PostgreSQL #базыданных #производительность