Текст подготовил: Андрей Федорчук

Персонализация приложений в реальном времени - это подстройка контента и интерфейса под конкретного пользователя на основе его действий и явных ответов. Privacy-safe модели позволяют делать это прямо на устройстве и через анонимные сценарии, не сливая личные данные в облако.
Вы открываете супер-приложение, а оно снова пихает кредит, хотя вы пришли за кэшбеком на доставку еды. Это классическая мертвая персонализация: данные есть, доверия нет, сценарии жестко зашиты в код.
Сейчас выигрывают те, кто умеет крутить сценарии персонализации в реальном времени: подстроить главный экран под вечерний спрос, сменить логику пушей за один день и при этом не положить компанию под Роскомнадзор. Ниже - как собрать такую архитектуру на on-device AI и Make.com, какие шаги не пропустить и где обычно ломается практика.
7 шагов к real-time персонализации без утечки данных
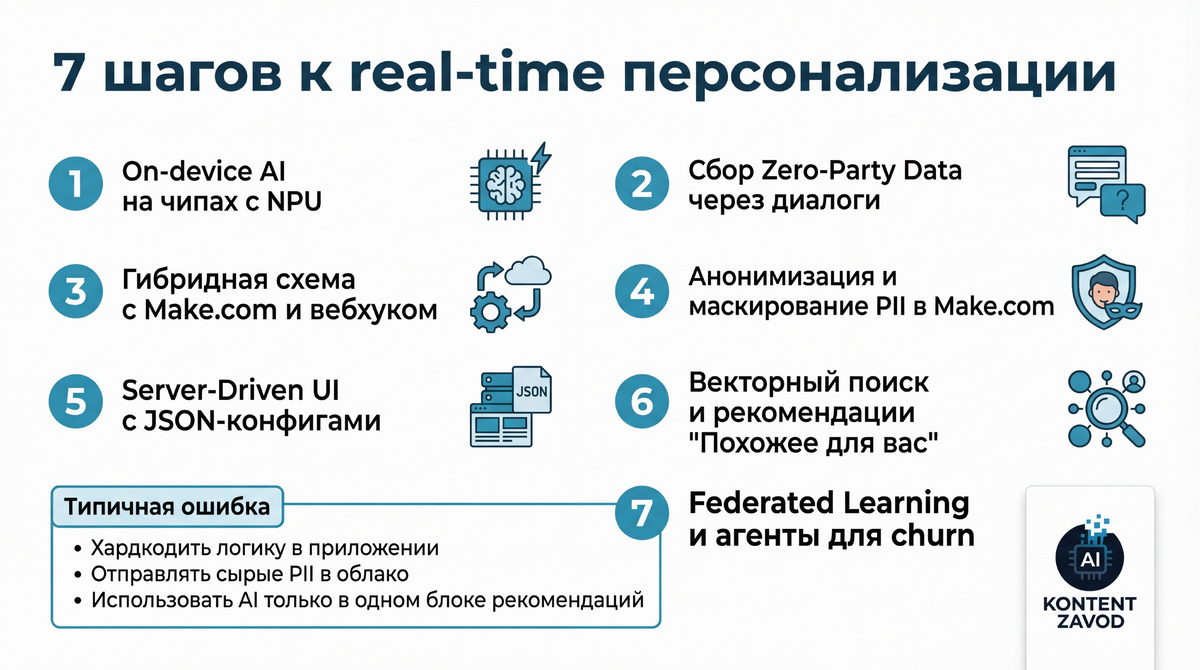
Шаг 1. Вынести чувствительные расчеты на устройство
Что делаем: закладываем в мобильное приложение поддержку on-device AI на чипах с NPU (Apple A-series, Snapdragon Gen 3+). Запускаем малые языковые модели вроде Phi-3 или Llama 3 8B прямо на телефоне.
Зачем: данные пользователя не покидают устройство, модель классифицирует намерения и контекст локально. Это сразу снижает риски по персональным данным и ускоряет отклик интерфейса на 40-60% по сравнению с чисто облачными запросами.
Типичная ошибка: пытаться решать все одной облачной LLM и везти туда сырой текст переписки, действия и геоданные. В итоге - задержки, вопросы безопасности и юристы, которые говорят «так нельзя».
Мини-пример РФ: финтех-приложение анализирует текстовые запросы в чате поддержки локальной SLM, чтобы понять, что клиент ищет кэшбек, а не вклад. На сервер уходит только обезличенный сигнал типа «интерес: кэшбек еда».
Шаг 2. Перейти от слежки к Zero-Party Data
Что делаем: внедряем внутри приложения AI-ассистента, который прямо спрашивает пользователя о целях и предпочтениях. Фиксируем ответы как Zero-Party Data - осознанно отданные данные, а не тайно собранные логи.
Зачем: пользователь понимает, зачем вы спрашиваете, и проще соглашается на персонализацию. Модель в реальном времени строит профиль предпочтений без передачи PII, вы работаете с категориями, а не с паспортными данными.
Типичная ошибка: прятать опросы глубоко в настройках или маскировать слежку под «анонимную аналитику», не объясняя выгоду. Тогда и конверсии нет, и доверие падает.
Мини-пример РФ: сервис доставки задает пользователю короткий диалоговый онбординг: любимая кухня, частота заказов, лимит по цене. Локальная модель превращает ответы в тегированный профиль, а дальше по этим тегам крутятся рекомендации блюд.
Шаг 3. Собрать гибридную архитектуру с Make.com
Что делаем: строим связку мобильное приложение - анонимизированный вебхук в Make.com - векторная база (Pinecone или Weaviate) - AI-модель через API с маскированием данных. В приложение возвращаем только решения: какие блоки показать, что рекомендовать.
Зачем: всю бизнес-логику персонализации выносите в no-code контуры. Можно за несколько минут изменить сценарий в Make.com и раздать новый JSON для интерфейса без перевыпуска приложения в сторах.
Типичная ошибка: хардкодить правила персонализации в коде приложения. Тогда любая гипотеза превращается в новый релиз и месяцы согласований.
Мини-пример РФ: маркетплейс моды держит в Make.com сценарии подбора блоков «Сейчас в тренде», «Для вас» и «Продолжить просмотр». Маркетинг меняет веса и фильтры в сценарии сам, не трогая мобильную команду.
Шаг 4. Маскировать данные через Make.com
Что делаем: используем Make.com как промежуточный слой для анонимизации. Перед тем как отправить что-то в OpenAI или Anthropic, подключаем модули с Data Masking или Regex и вычищаем почты, имена, точные координаты.
Зачем: внешним AI-сервисам уходят только токены и категории вроде «Пользователь_ID_123», «Категория: Спорт». Это снижает регуляторные риски и упрощает внутренние согласования по безопасности.
Типичная ошибка: сначала прототипировать «как есть», везти полные payload с PII, а маскирование добавлять потом. На этой стадии обычно включаются службы безопасности и стопорят проект.
Мини-пример РФ: мобильный банк, отправляющий в внешнюю модель только обезличенные описания операций и тег «зарплатный клиент», а не ФИО и номер карты. Make.com режет все лишнее регулярками на входе в сценарий.
Шаг 5. Внедрить динамический интерфейс (Server-Driven UI)
Что делаем: переносим конфигурацию экранов в JSON, который приложение запрашивает у серверной части. В Make.com на основе предиктивной аналитики AI собираем этот JSON под конкретного пользователя.
Зачем: можно мгновенно менять структуру главного экрана и карточек, не трогая само приложение. AI видит паттерн поведения, Make.com отдает другой набор блоков.
Типичная ошибка: использовать AI только в рекомендациях внутри одного блока, а сам UI держать статичным. Пользователь все равно видит старую витрину и не ощущает персонализации.
Мини-пример РФ: сервис доставки еды вечером автоматически выносит на главный экран быстрый повтор последних заказов, а днем — ланч-предложения рядом с офисом. Пересборка экрана идет через JSON-конфиги из Make.com.
Шаг 6. Подключить векторный поиск и real-time рекомендации
Что делаем: интегрируем Make.com с векторной базой данных. Каждое действие пользователя превращаем в эмбеддинг и сравниваем с базой контента, товаров или статей.
Зачем: рекомендации «Похожее для вас» обновляются на лету, за миллисекунды. Не нужно руками настраивать сложные правила, достаточно хорошей эмбеддинг-модели и грамотной фильтрации.
Типичная ошибка: хранить только классические события в аналитике и строить рекомендации по грубым сегментам (пол, возраст, город). Это быстро упирается в потолок по качеству.
Мини-пример РФ: медиа-приложение по финансовой грамотности кодирует каждую статью и действия пользователя в эмбеддинги. После прочтения материала о ипотеке сразу предлагает подборку из близких по смыслу разборов и калькуляторов.
Шаг 7. Добавить защищенное обучение и автономных агентов
Что делаем: используем федеративное обучение, чтобы глобальная модель персонализации училась на поведении тысяч пользователей без сбора сырых данных в одном месте. Параллельно поднимаем в Make.com автономных агентов, которые следят за поведением и сами решают, когда и кому слать пуши или предлагать скидки.
Зачем: качество персонализации растет, но данные остаются на устройствах или в зашифрованных «анклавах» (PPC). Агенты уменьшают ручную работу маркетинга и вовремя ловят риск оттока (churn).
Типичная ошибка: дообучать модели на реальных логах без анонимизации и без федеративного подхода. Это чревато утечками и токсичными датасетами, которые потом сложно вычистить.
Мини-пример РФ: подписочный сервис медитаций учит модель рекомендовать практики по агрегированным градиентам с устройств. Агент в Make.com отслеживает падение вовлеченности и аккуратно предлагает мягкий промо-тариф, а не сразу агрессивный скидочный спам.
Подходы к персонализации: что выбрать под ваши задачи
Кому эта архитектура реально экономит ресурсы
Персонализация в реальном времени на privacy-safe моделях особенно полезна тем, кто упирается в стоимость привлечения и требования к безопасности данных.
- Продуктовые и маркетинг-команды супер-приложений: можно тестировать десятки сценариев персонализации через Make.com без очереди к мобильным разработчикам.
- Финтех и страхование: on-device AI и анонимизация через Make.com снимают часть рисков по ПДн и ускоряют согласования с безопасностью и комплаенсом.
- E-commerce и маркетплейсы: гибридная персонализация повышает конверсию в покупку за счет точных рекомендаций и динамического UI без жесткой сегментации.
- B2B-сервисы с мобильными клиентами: векторный поиск и Zero-Party Data помогают тонко подстраивать контент под роли пользователей, не собирая лишних логов.
- Команды, которые хотят использовать Federated Learning и синтетические данные: можно доучивать модели персонализации, не накапливая реальные пользовательские логи в единой точке отказа.
Частые вопросы
Персонализация в реальном времени — это только про рекомендации?
Нет. Рекомендации - лишь часть. Real-time персонализация затрагивает главный экран, порядок блоков, тексты, пуши и поведение ассистента. On-device AI и сценарии в Make.com позволяют менять все это по сигналам здесь и сейчас.
Как убедить безопасность и юристов, что это не утечка данных?
Опора на on-device AI, анонимизацию через Make.com и технологии PPC - ваши главные аргументы. Данные остаются на устройстве или идут в зашифрованных анклевах, PII маскируется. Плюс вы опираетесь на Zero-Party Data вместо скрытого трекинга.
Где хостить векторную базу и модели, чтобы не было проблем по РФ?
Схема простая: приватные модели можно крутить в облаке, соответствующем требованиям вашей отрасли, а чувствительные вычисления - оставлять на устройстве. Make.com в этой картине выступает как оркестратор и слой анонимизации, а не как хранилище ПДн.
Без разработчиков вообще можно обойтись, если есть Make.com?
Нет. Нужны мобильные разработчики, чтобы встроить on-device модели и Server-Driven UI. Но после этого маркетинг и продукт могут сами быстро собирать и править сценарии персонализации в Make.com без постоянных релизов.
Что делать, если данных пока мало и персонализация «шумит»?
Хороший вариант - использовать синтетические данные для дообучения моделей и запускать федеративное обучение. Так вы улучшаете качество персонализации, не собирая сырые пользовательские логи в одном месте.
Как не «задушить» пользователя излишней персонализацией и пушами?
Помогают автономные агенты в Make.com, которые считают вероятность оттока и вовлеченность. Они решают, когда промолчать, а когда отправить пуш или дать скидку. Ключ - учитывать не только клики, но и паузы, отказ от уведомлений, тональность диалогов.
Можно ли потом переключиться с внешних моделей на свои?
Да. Если изначально закладывать анонимизацию и четкий интерфейс в Make.com, источник модели (OpenAI, Anthropic или свое приватное разворачивание SLM) легче поменять. Сценарии персонализации при этом останутся прежними.
Какой сценарий персонализации в вашем приложении сейчас самый слабый — главный экран, рекомендации или пуши? Напишите, что болит, и подпишитесь на канал, чтобы не пропустить разборы практических кейсов по Make.com и AI.
#персонализация, #mobile, #ai
AI kontent Zavod:
Связаться с Андреем
Email
Заказать Нейро-Завод
Нейросмех YouTube
Нейроновости ТГ
Нейрозвук ТГ
Нейрохолст ТГ