Gemma 4
Обновили свои продвинутые reasoning модели, на базе gemini 3
Четыре размера
E2B | Eff. 2B | Смартфоны, IoT, Raspberry Pi
E4B | Eff. 4B | Мобильные устройства, NVIDIA Jetson
26B MoE | 26B (активно 3.8B) | пк, быстрый вывод
31B Dense | 31B | Рабочие станции
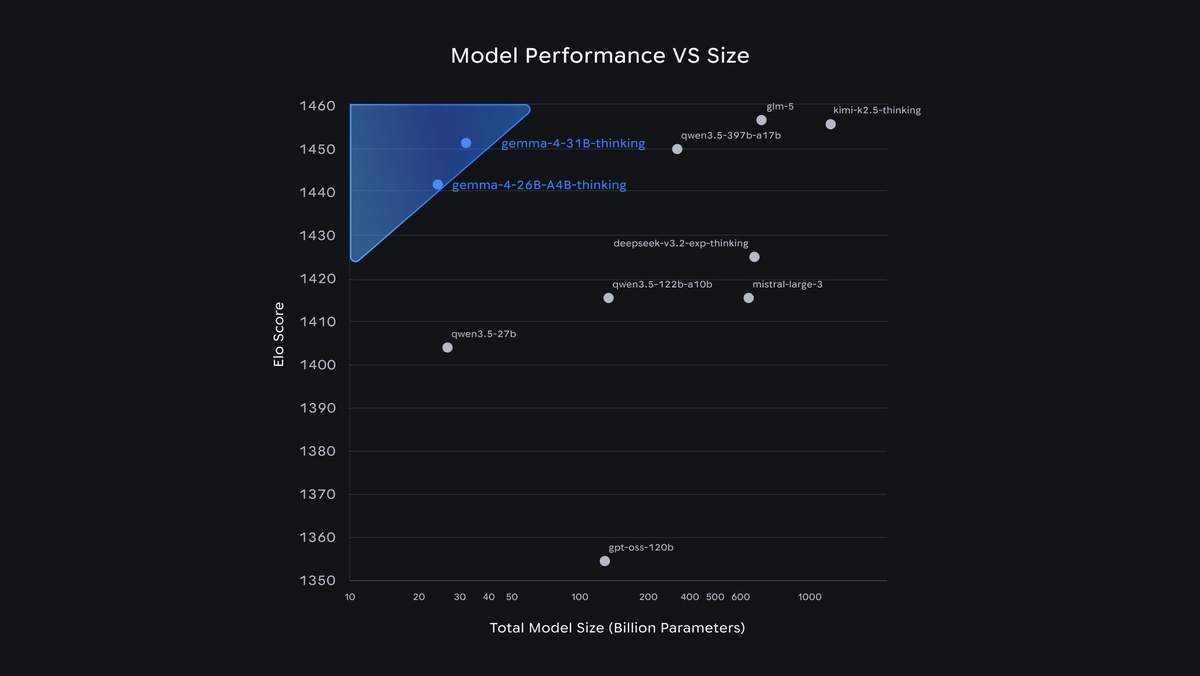
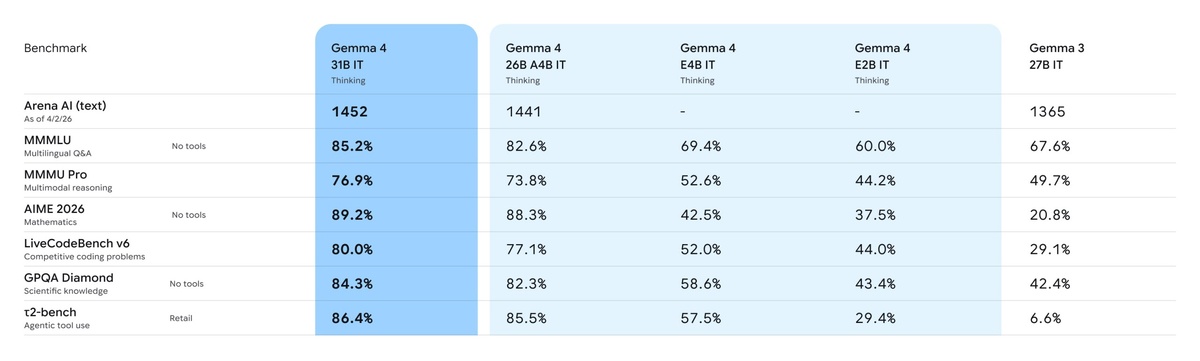
31B модель заняла #3 место среди опенсорсов в мире на Arena AI Leaderboard
26B MoE #6 место, при этом превосходя модели в 20 раз крупнее
Для агентов, кодинга и размышлений стоит попробовать, контекст до 128K токенов для edge-моделей и до 256K для больших моделей
Запускать можно уже через vLLM, llama.cpp, MLX, LM Studio, Unsloth, NVIDIA NIM, Docker
На Android можно начать тестить через AICore Developer Preview, получая совместимость с Gemini Nano 4 в будущем
🔘Про системные требования
инференс (данные только для загрузки весов, без учёта KV-кэша контекста)
Сначала про BF16 (16 бит), для моделей E2B/E4B/26B A4B/31B вам понадобится 9,6GB/15GB/48GB/58,3GB соотвественно
Для SFP8 (8-бит) надо 4,6/7,5/25/30,4gb также соответственно предыдущей версии
Для Q4_0 (4-бит) 3,2gb/5gb/15,6gb/17,4gb
26B MoE (ноутбуки и пк)
Для 4-бит GGUF вам хватит 16-18гб ОЗУ+VRAM, например RTX 3090/4090 на 24гб, при таком сетапе скорость будет примерно 30+ токенов/сек
Для 8 битной версии понадобится 28-30гб например RTX 4090x2/Mac M3 Max
31B Dense (разработческие станции и серверы)
4-бит GGUF: 17-20гб ОЗУ+VRAM, например RTX 4090 (24гб) или M3 Max/M4 Max
BF16: 58+гб ОЗУ+VRAM, там уже потребительское заканчивается, минимум нужен 1 NVIDIA H100 80 ГБ или M4 Ultra (192 ГБ)
Google AI Studio для 31B и 26B MoE
AI Edge Gallery для E4B и E2B