Теперь локальные ИИ-модели могут напрямую использовать нейроускоритель и унифицированную память, что заметно ускоряет генерацию. Речь о связке с фреймворком MLX. За счёт этого снижается задержка до первого токена и растёт общая скорость работы моделей — особенно это заметно в задачах вроде локальных ассистентов и генерации кода. Но есть ограничения. Поддерживаются только M5, M5 Pro и M5 Max, а системе требуется минимум 32 ГБ общей памяти.
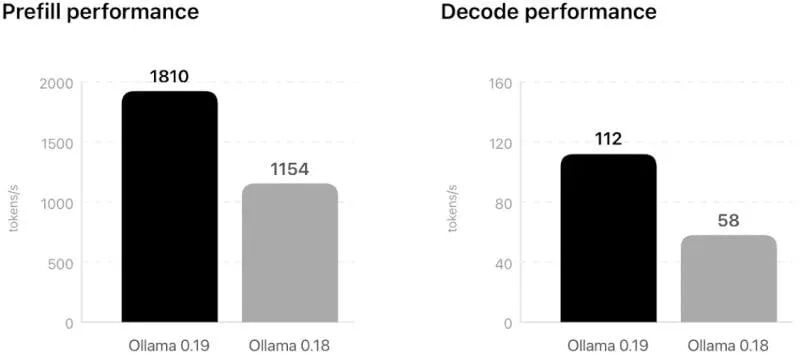
Ollama получила обновление 0.19 с поддержкой аппаратного ускорения на чипах Apple M5. Теперь локальные ИИ-модели могут напрямую использовать нейроускоритель и унифицированную память, что заметно ускоряет генерацию.
Речь о связке с фреймворком MLX. За счёт этого снижается задержка до первого токена и растёт общая скорость работы моделей — особенно это заметно в задачах вроде локальных ассистентов и генерации кода.
Но есть ограничения. Поддерживаются только M5, M5 Pro и M5 Max, а системе требуется минимум 32 ГБ общей памяти.