Нейросети научились писать тексты, анализировать изображения и помогать в работе — но за этим внешним «интеллектом» скрывается куда более прозаичный механизм. Они не понимают смысл так, как человек, и не размышляют в привычном смысле слова. Их сила — в обработке огромных массивов данных и поиске закономерностей.
Именно поэтому сегодня главный вопрос звучит иначе: не «что умеет ИИ», а «на чем он учится». И здесь возникает проблема, о которой еще пару лет назад почти не говорили — данных становится недостаточно. Причем не в количестве, а в качестве. Это меняет сам подход к обучению нейросетей и влияет на будущее всей индустрии.

Как на самом деле работают нейросети
Вопреки популярному представлению, нейросеть не ищет готовый ответ и не «думает». Она действует как продвинутая система прогнозирования: на основе предыдущего опыта выбирает наиболее вероятное продолжение запроса.
Это похоже на автодополнение в мессенджере, доведенное до предела. Модель получает текст, сопоставляет его с миллионами примеров из обучения и выдает результат, который статистически выглядит наиболее уместным.
Большинство современных систем относятся к классу больших языковых моделей. Они не выполняют действия сами по себе — их задача в генерации: текста, кода, описаний, аналитики. И именно здесь проходит граница между «создает ответ» и «понимает смысл».
Чем лучше обучающие данные — тем выше точность. Но если в обучении был шум, ошибки или перекос, модель будет воспроизводить их с полной уверенностью.
Этапы обучения: от сырого массива до «умной» модели
Обучение нейросети — это не магия и не один процесс. Это длинная цепочка, где каждая стадия влияет на итоговое качество.
Сначала собираются данные. Это могут быть тексты, изображения, код, аудио — все, что можно структурировать и использовать как пример. Важно не только количество, но и разнообразие: чем шире охват, тем универсальнее модель.
Затем идет очистка. Удаляются дубликаты, ошибки, бессмысленные фрагменты. Если этого не сделать, нейросеть начнет «учиться на шуме» — и это одна из частых причин странных ответов.
После этого запускается само обучение: модель выстраивает связи между входом и выходом. Далее — дообучение, где добавляются реальные сценарии, ограничения и корректировки поведения.
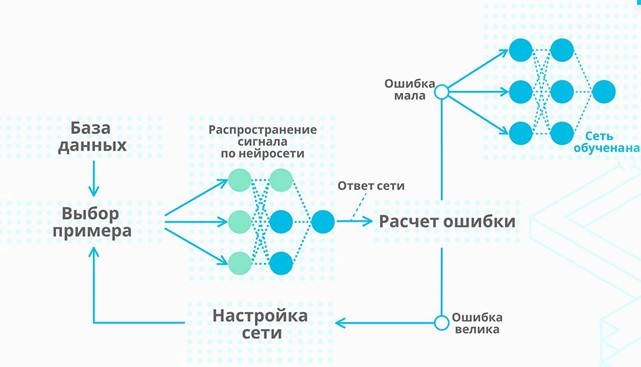
И наконец — проверка. Люди оценивают ответы, корректируют ошибки и фактически «доводят» модель до рабочего состояния.
Важно понимать: обучение не заканчивается. Без обновления данных любая модель постепенно теряет актуальность — как карта, которую перестали обновлять.
На чем обучаются нейросети сегодня
Современные модели используют сразу несколько типов данных. Это тексты, изображения, видео, аудио и программный код. Такой подход делает их мультимодальными — способными работать сразу с разными форматами информации.
Но ключевой момент — не объем, а качество. Один тщательно размеченный набор данных может дать больше пользы, чем тысячи случайных страниц из интернета.
Особую роль играют специализированные датасеты: медицина, право, финансы. Именно они позволяют моделям давать более точные и прикладные ответы, а не общие формулировки.
Подробно о том, как меняются подходы к обучению и какие технологии выходят на первый план, регулярно разбирается на сайте — там удобно отслеживать реальные сдвиги, а не маркетинговый шум.
Почему интернет перестал быть бесконечным источником
Еще недавно казалось, что интернета хватит навсегда. Но на практике оказалось иначе.
Во-первых, большая часть качественного контента уже использована в обучении крупных моделей. Во-вторых, интернет переполнен дубликатами и слабыми текстами, которые не добавляют ценности.
Но главный фактор — рост AI-контента. Все больше материалов создаются самими нейросетями. В результате модели начинают учиться на собственных же ответах, постепенно ухудшая качество — эффект «информационного эха».
Добавляются и юридические ограничения: далеко не все данные можно использовать свободно.
В итоге обучение становится дороже, сложнее и требует гораздо более точной работы с источниками.
Почему нейросети ошибаются — и это нормально
Ошибки нейросетей часто воспринимаются как сбой, но на деле это логичное следствие их природы.
Модель не знает, что она ошиблась. Она просто выбирает наиболее вероятный вариант ответа. Если в обучении был пробел или противоречие — ошибка неизбежна.
Причины могут быть разными: нехватка данных, перекос в обучающей выборке, устаревшая информация или просто статистическая «догадка».
Именно поэтому ответы иногда звучат уверенно, но оказываются неточными. Уверенность — это не показатель истинности, а лишь результат вычислений.
Люди в обучении ИИ: скрытый фактор качества
За любым сильным ИИ стоят люди. Специалисты формируют примеры, проверяют ответы, задают стиль и корректируют поведение модели.
Это особенно важно в сложных областях, где цена ошибки высока. Без участия экспертов нейросеть выдает усредненные ответы, которые выглядят убедительно, но могут вводить в заблуждение.
По сути, ИИ масштабирует человеческий опыт. Но если исходный опыт слабый — масштабирование только усиливает проблему.
Кстати, разборы таких нюансов регулярно появляются в Telegram. Там удобно следить за тем, как меняется реальный ИИ, без лишнего шума и громких обещаний.
Локальные данные: почему язык имеет значение
Одна из недооцененных проблем — нехватка качественных данных на русском языке. Большая часть интернета англоязычная, и это напрямую влияет на качество моделей.
В результате появляются ошибки в терминологии, слабая адаптация к локальному контексту и общее снижение точности.
Чтобы нейросеть действительно хорошо работала в конкретной стране, ей нужны не переводы, а оригинальные данные — с учетом культуры, языка и практики.
Именно это становится конкурентным преимуществом в новой гонке ИИ.
Будущее: от количества к качеству
Индустрия уже прошла этап, когда побеждал тот, у кого больше данных. Теперь ситуация меняется.
Фокус смещается на качество, структуру и происхождение информации. Разрабатываются синтетические данные, усиливается роль экспертов, растет значение узкоспециализированных наборов.
Параллельно появляются новые типы систем — не только генерирующие текст, но и выполняющие действия. Это следующий шаг: от ответа к реальному результату.
И в этой новой реальности выигрывают не самые большие модели, а самые точные.
Практика: как правильно использовать нейросети
Чтобы получать качественные ответы, важно учитывать особенности работы ИИ.
Во-первых, формулировать запросы максимально конкретно. Чем точнее вопрос — тем выше шанс получить полезный результат.
Во-вторых, проверять информацию. Нейросеть может ошибаться, особенно в деталях.
В-третьих, использовать ее как инструмент, а не как источник истины. Это помощник, а не эксперт.
И главное — понимать ограничения. Тогда ИИ становится усилителем мышления, а не его заменой.
Вывод
Нейросети — это не «цифровой разум», а сложные статистические системы, зависящие от данных. И сегодня главный вызов — не алгоритмы, а качество информации, на которой они обучаются.
Интернет перестал быть идеальным источником. На смену приходит новая модель: меньше данных, но больше точности, контроля и экспертизы.
Именно это определит, какими будут нейросети в ближайшие годы — поверхностными генераторами или по-настоящему полезными инструментами.
Больше таких разборов, без шума и лозунгов — в Telegram-канале