Новая работа из MIT ставит под сомнение привычное представление о том, что «экспертные» модели нужно долго и аккуратно дообучать. Авторы показывают, что достаточно одного шага — добавить гауссов шум в веса предобученной модели, повторить это много раз и скомбинировать ответы — чтобы получить эффективность, сопоставимую с профессиональными методами тонкой настройки вроде GRPO/PPO.
Главная идея — «Neural Thickets» (нейронные заросли)
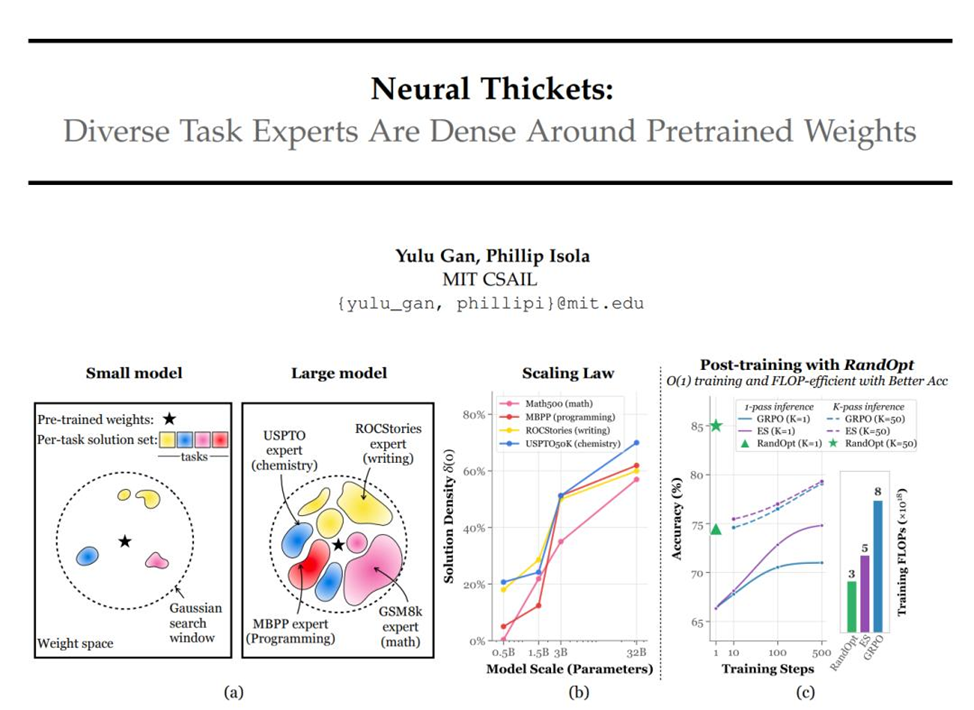
Авторы вводят интуитивно контр-интуитивную картину: вокруг веса предобученной модели в пространстве параметров «растут» сотни и тысячи локальных «специалистов» — моделей, каждая из которых сильна в каком-то конкретном подзадаче. Это явление они называют «Neural Thickets» — нейронные заросли.
Ключевые наблюдения:
- Если слегка (но случайно) потрясти веса предобученной модели, то часто встречаются варианты, которые заметно улучшают поведение на какой‑то конкретной задаче.
- Чем больше модель, тем плотнее и обширнее эти «высокоэффективные» области вокруг исходных весов: у больших моделей случайные возмущения чаще приводят к улучшениям.
- Такие случайные модификации, как правило, создают «узкоспециализированных» экспертов: один вариант лучше в математике, но хуже в кодировании; другой — превосходен в химии, но плохо пишет рассказы.
Чтобы понять источник эффекта, авторы рассмотрели простую 1D саморегрессионную модель (простейшая архитектура и задача). Они сравнили три сценария:
- без предобучения — вокруг весов нет улучшений при случайных возмущениях;
- предобучение на одной задаче — модель сильна в этой задаче, но вокруг неё нет разнообразных улучшений;
- мультизадачное предобучение — вокруг весов появляется множество направлений, каждое из которых открывает специализированную способность.
Вывод: «нейронные заросли» рождаются благодаря масштабному мультизадачному предобучению — большое количество задач в предобучении «запасает» в весах множество нишевых решений.
Алгоритм RandOpt — «шум, отбор, голосование»
На базе этих идей авторы предложили простой алгоритм RandOpt:
- Сгенерировать N версий модели, добавив к весам случайный гауссов шум (разных амплитуд — small/medium/large sigma).
- На небольшом валидационном наборе отобрать K лучших моделей.
- На этапе вывода (inference) запустить эти K моделей параллельно и объединить их ответы правилом большинства (voting).
Особенности:
- Процесс одноступенчатый: нет итеративного обучения, нет градиентов, не нужен LR.
- Хорошо распараллеливается (K моделей на нескольких GPU).
- Чем больше N и чем больше K, тем сильнее эффект (но растут затраты на инференс).
Результаты и где RandOpt работает лучше
Авторы экспериментировали с Qwen2.5 (диапазон 0.5B—32B параметров) и рядом других архитектур. Основные наблюдения:
- При проекции 1000 случайных возмущений в 2D видно: у больших моделей вокруг места исходных весов много «красных» (улучшающих) областей, у малых — преобладают области падения качества.
- На задачах математического рассуждения, программирования, письма, химии RandOpt показал точность, сравнимую или превосходящую GRPO/PPO/ES в ряде бенчмарков.
- Для визуально‑языковых моделей эффект особенно заметен: точность выросла например с 56.6% до 69.0% в одном из измерений.
- Аналогичные эффекты обнаружены и для диффузионных моделей: определённые области параметров склонны генерировать изображения с характерным тоном/стилем.
Ограничения и предостережения
Авторы честно перечисляют слабые стороны подхода:
- Требуется качественное многозадачное предобучение — без него «зарослей» нет.
- RandOpt не позволяет модели «научиться» совершенно новой способности, которую не содержит предобучение.
- Для стабильного выигрыша нужно запускать K моделей при выводе — это дороже по ресурсам. Дистилляция может помочь, но не всегда применима (особенно для генеративных задач).
- Подход лучше подходит для задач с чётким правильным ответом; для творческих/структурных генеративных задач потребуются более сложные схемы агрегации.
Авторы и ссылки
Работу выполнили Yulu Gan (PhD‑студент MIT, ранее магистр Пекинского университета) и его научный руководитель Phillip Isola (MIT, известный по работам в компьютерном зрении и автору таких работ, как pix2pix и LPIPS).
Оригинальные материалы:
- Статья (arXiv): https://arxiv.org/pdf/2603.12228
- Репозиторий с кодом: https://github.com/sunrainyg/RandOpt
- Проектная страница: https://thickets.mit.edu/
Хотите создать уникальный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/