Коллектив исследователей из МФТИ и Сколтеха показал, что квантовый «рекуррентный» алгоритм можно не только придумать на бумаге и проверить в симуляторе, но и реализовать на реальном сверхпроводниковом процессоре — на интегральной схеме с искусственными атомами-трансмонами.
Ученые построили и обучили квантовую рекуррентную нейросеть прогнозированию числовых последовательностей и добились качества предсказания, сопоставимого с компактными классическими архитектурами на типовой задаче машинного обучения. Результаты опубликованы в JETP Letters.
С виду задача звучит почти буднично: есть ряд чисел, которые меняются во времени, и нужно угадать, каким будет следующий шаг. Так устроены и давление в атмосфере, и нагрузка в электросети, и температура, и бесчисленные «сигналы» в физике, биологии, экономике. Однако за этой простотой скрывается ключевой вызов современной обработке данных.
Классические рекуррентные нейросети научились извлекать закономерности, которые не видны при поверхностном взгляде. Вопрос последних лет состоит в том, может ли квантовый процессор предложить для таких задач что-то практически работающее уже сейчас, в эпоху так называемых NISQ-устройств, «шумных» квантовых машин промежуточного масштаба.
В сверхпроводниковом квантовом компьютере информация хранится в состояниях искусственных атомов, которые представляют собой электрический контур из сверхпроводящего материала с джозефсоновскими переходами, рисунок которого задается на кремниевой подложке методами литографии.
Информация может быть искажена: окружающая среда, взаимодействующая с информационными состояниями, несовершенство управляющих импульсов, ошибки считывания — все это постепенно пагубно влияет на квантовую память.
Отсюда рождается необходимость тонкой настройки: сделать схему достаточно сложной, чтобы она умела выражать нужные зависимости, и одновременно достаточно простой, чтобы квантовые состояния не распадались до того, как из них извлекут информацию.
В качестве квантового аналога рекуррентной сети исследователи выбрали архитектуру QRNN — квантовую рекуррентную нейросеть. Логика здесь похожа на классическую: модель получает на вход отрезок временного ряда и на его основе предсказывает следующий элемент.
Но способ «запоминания» и «переваривания» информации совсем другой. Вместо привычных матриц весов и нелинейностей используют параметризованные квантовые схемы — цепочки квантовых операций, в которых часть углов поворотов и параметры запутывающих элементов подбираются обучением.
Авторы исследования решили выяснить, насколько обучаемой оказывается QRNN на реальном сверхпроводниковом чипе, какие настройки действительно улучшают качество предсказания, и где проходит граница, за которой усложнение схемы перестает приносить выигрыш. Для этого они построили полный «конвейер» — от подготовки данных и симуляции на классическом компьютере до переноса оптимальных гиперпараметров на квантовое оборудование и обучения уже на микросхеме.
Входной ряд сначала привели к удобному масштабу: значения масштабируются в диапазон от –1 до 1, чтобы их было проще кодировать в квантовые состояния. Затем из последовательности вырезали обучающие примеры: фрагмент из T последовательных точек и «ответ» — следующий элемент, который модель должна предсказать. Но напрямую скормить квантовому процессору длинный временной отрезок трудно: чем больше шагов нужно «пропустить» через схему, тем длиннее становятся цепочки квантовых операций и тем сильнее накапливаются ошибки.
Поэтому исследователи использовали классический прием из обработки сигналов — свертку. Из исходного отрезка длиной T сформировали более короткую последовательность признаков длиной τ методом скользящего окна; эти значения затем по одному, последовательно, подавались на вход квантовой схемы.
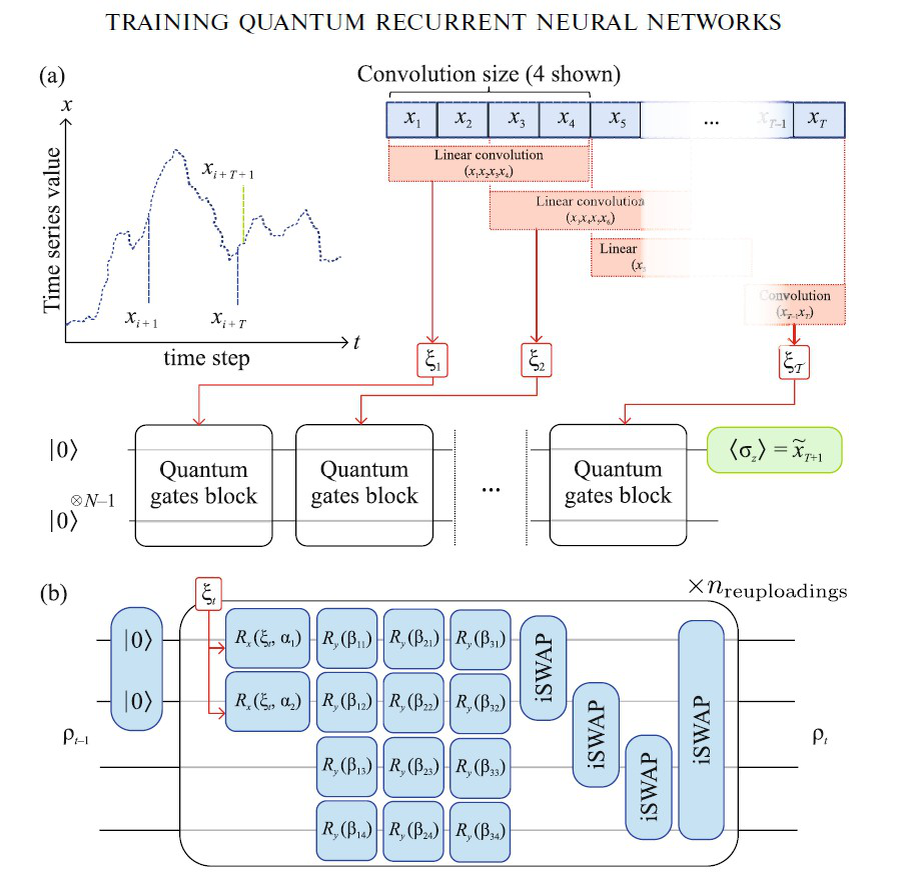
Сама квантовая часть устроена как повторяющийся блок операций. Половина кубитов играет роль «регистра»: туда непосредственно записываются текущие входные значения, а затем эти кубиты можно возвращать в базовое состояние, чтобы снова использовать для записи.
Другая половина работает как память: будучи запутанной с регистром, она несет в себе след прошедших входов. Кодирование данных происходит через вращения кубита, в которых угол поворота зависит от входного числа и пары обучаемых коэффициентов.
После кодирования идут параметризованные однокубитные вращения вокруг разных осей — квантовый аналог набора «весов», который меняет внутреннее состояние системы.
Затем применяется запутывание — серия двухкубитных операций, организованных в циклическую «лестницу», чтобы кубиты обменивались возбуждением и коррелировали друг с другом.
Отдельный прием, на который авторы делают ставку, называется data reuploading — повторная «перезагрузка» одних и тех же входных данных в схему несколько раз. Это делается для того, чтобы построить более богатые представления входного сигнала, не увеличивая число кубитов.
Авторам исследования удалось показать в своей работе, что reuploading действительно снижает ошибку предсказания, а в некоторых режимах настройки параметров можно уменьшить ее даже на порядок.
Чтобы обучить сеть, исследователи использовали стандартный для регрессии критерий — среднеквадратичную ошибку, и оптимизацию по градиенту. Для вычисления градиента для каждого обучаемого угла выполнили измерения при двух значениях, сдвинутых на ±π/2, и по разности восстановили производную.
Прежде чем ставить эксперимент на чипе, команда тщательно исследовала модель в симуляторе, перебирая ключевые гиперпараметры: число кубитов, длину входного окна T, параметры свертки до τ элементов и число повторных загрузок данных. Результаты симуляции позволили сразу понять общие закономерности.
Увеличение числа кубитов улучшало качество обучения и снижало ошибку на тестовом сегменте временного ряда, но после шести кубитов проявлялось насыщение: выигрыш становился минимальным, а стоимость усложнения — ощутимой.
При слишком маленьком T модель не превосходила наивный прогноз «завтра будет как сегодня», потому что входной фрагмент был слишком короток и не нес информации о динамике.
При слишком большом T время выполнения схемы росло, а качество обучения либо не улучшалось, либо обучение становилось медленнее. Оптимальным оказалось окно T = 10 с последующей сверткой до τ = 4 признака.
Для работы на сверхпроводниковом квантовом процессоре авторы выбрали задачу прогнозирования атмосферного давления, реальный набор данных из тестового пула. Они взяли конфигурацию, показавшую себя оптимальной в эмуляции: четыре кубита, свертка из T = 10 в τ = 4 и троекратный reuploading.
В таком режиме квантовая схема содержала 71 обучаемый параметр и глубину 99 слоев операций. На уровне аппаратуры это означало тщательно выстроенную последовательность микроволновых импульсов, которые последовательно реализовывали вращения и запутывающие iSWAP на выбранных трансмонах.
Сам чип представлял собой массив трансмонов с квазидвумерной топологией связей: на кристалле разведены линии управления, резонаторы для дисперсионного считывания и элементы обвязки.
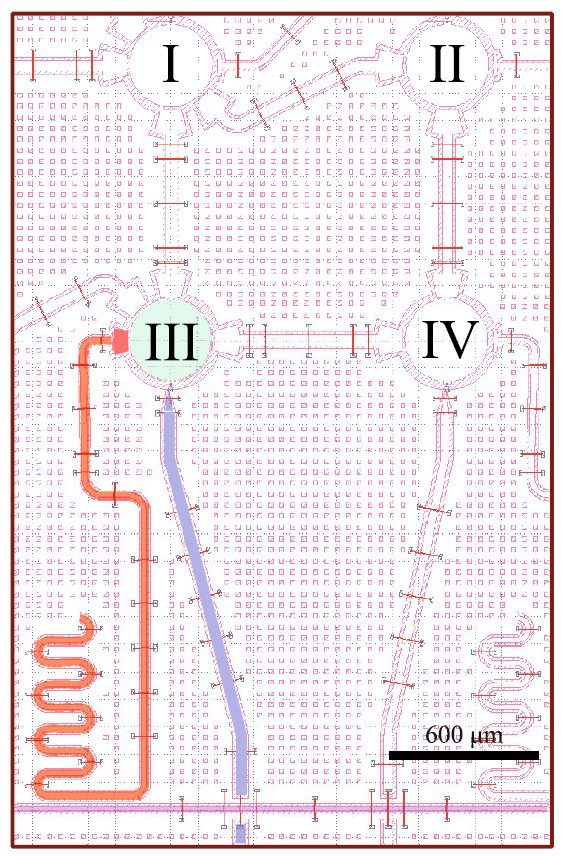
Выбранные четыре кубита имели частоты перехода порядка нескольких гигагерц и времена релаксации и дефазировки в диапазоне от нескольких до десятков микросекунд, что задавало тот самый «дедлайн», в который нужно было уложить вычисление.
Один прогон параметризованной схемы занял около 5 микросекунд, считывание — около 0,5 микросекунды, а затем системе потребовалось порядка 100 микросекунд, чтобы вернуться в основное состояние. Чтобы оценить один выход сети при фиксированных параметрах, измерение повторили тысячу раз и усреднили.
А чтобы посчитать градиент по правилу сдвига параметра, пришлось выполнять сотни таких измерений для разных углов (авторы указали среднее число 343). При изменении угла однокубитного вращения нужно порядка 100 микросекунд, и именно это существенно увеличило полное время на один элемент обучающей последовательности.
В статье приводится оценка: на обработку одного элемента обучающей последовательности уходит примерно 71 секунда, а одна эпоха обучения занимает около пяти часов. За 25 эпох суммарное время экспериментального обучения превышает 100 часов, и это при том что отдельные квантовые операции выполняются за десятки наносекунд.
Тем не менее главное в этой истории не скорость, а то, что обучение на реальном процессоре вообще сохраняет «смысл». Авторы показывают, что на чипе кривая обучения становится более шумной и смещается по сравнению с эмуляцией из-за конечной когерентности и ошибок операций, однако общий тренд остается нисходящим: модель учится.
Ученые сравнили ход обучения на симуляторе и на квантовом железе, и показали, что даже в условиях аппаратных ограничений обучение не разваливается в хаос, а сохраняет направленность к меньшей ошибке.
Сергей Самарин, инженер лаборатории искусственных квантовых систем МФТИ, прокомментировал: «В эпоху шумных квантовых процессоров времена когерентности кубитов могут оказаться сопоставимыми со временем, необходимым для выполнения квантовых операций в цепочке, поэтому приходится балансировать между глубиной алгоритма и сохранностью квантового состояния».
Олег Астафьев, заведующий лабораторией искусственных квантовых систем МФТИ, добавил: «Мы показали, что свертка при кодировании и многократная перезагрузка данных повышают эффективность обучения, а дальнейшее ускорение возможно, если сократить время релаксации системы за счет безусловного сброса кубитов».
Чтобы понять, насколько хорошо работает квантовая модель, исследователи сравнили лучшие достигнутые значения ошибки с классическими рекуррентными архитектурами RNN, LSTM и GRU, причем число параметров в сравниваемых моделях не превышало сотни.
На одних рядах QRNN проигрывает лучшим классическим вариантам, на других оказывается сопоставимым, а на некоторых даже показывает лучший результат среди компактных моделей.
Исследователям удалось свести воедино три трудносочетаемые вещи: рекуррентную обработку временных рядов, вариационные квантовые схемы и реальные аппаратные ограничения сверхпроводникового процессора.
Во многих работах квантовое машинное обучение остается лишь на уровне симуляций. Здесь же архитектура подстроена под набор реально реализуемых вентилей, а анализ «обучаемости» проведен с прицелом на то, что модель должна переноситься на чип.
Важной частью исследования стала разработка методики по сочетанию классической свертки и квантовой обработки: свертка уплотняет информацию и сокращает глубину квантовой части, что помогает бороться с декогеренцией. Систематическое исследование reuploading показало, что эффективность обработки временного ряда можно наращивать, не увеличивая число кубитов, а всего лишь повторно вводя данные в схему.
Прогнозирование временных рядов — универсальная подзадача в инженерии: от мониторинга состояния оборудования и предиктивного обслуживания до оценки нагрузки в энергосетях и фильтрации шумных измерений в экспериментальной физике.
Если квантовые устройства научатся выполнять такие задачи хотя бы на уровне компактных классических моделей, это откроет путь к гибридным системам, где часть вычислений делается квантовым модулем, а часть — классическим, и выигрыш будет определяться разумной архитектурой всего конвейера.
Кроме того, исследование дает фундаментальный вклад в понимание того, как именно учатся параметризованные квантовые схемы на реальном железе: где наступает насыщение от добавления кубитов, как выбирать длину входа, чем платить за глубину.
Перспективы дальнейших исследований здесь растут из тех же ограничений, которые сейчас тормозят прогресс. Авторы указывают очевидный следующий шаг: радикально ускорить обучение за счет сокращения времени релаксации системы, например применяя безусловный сброс кубитов, который может уменьшить паузу ожидания до микросекунды.
Это изменит экономику эксперимента: если не нужно ждать сотни микросекунд между прогонами, число эпох и объем данных, доступных для обучения на железе, резко возрастут.
Другой путь — расширение выходного пространства модели: нынешняя схема предсказывает один признак, считывая один кубит, но при мультиплексированном считывании нескольких кубитов можно увеличить размерность выходного вектора и перейти к более сложным прогнозам.
Наконец, остается большой пласт вопросов о том, какие схемы кодирования данных лучше подходят для сверхпроводниковых платформ, как оптимально сочетать классическую предобработку и квантовую часть и где проходит граница, после которой квантовая рекуррентная архитектура начнет выигрывать не только «по качеству при малом числе параметров», но и по эффективности на реальных прикладных задачах.
📖 Результаты опубликованы в JETP Letters.
___________________________________
Научная статья: S. S. Samarin, A. E. Tolstobrov, S. V. Sanduleanu, G. P. Fedorov, A. A. Ryabov, V. V. Vanovskiy, D. A. Kalacheva, A. N. Bolgar, V. B. Lubsanov, Sh. V. Kadyrmetov, A. M. Muraviev, E. S. Alekseeva, P. Yu. Shlykov, A. M. Yeremeyev, A. V. Vasenin, A. Yu. Dmitriev, O. V. Astafiev; Training Quantum Recurrent Neural Networks on a Josephson Integrated Circuit; JETP Letters, 2025, Vol. 122, No. 11, pp. 782–789, https://doi.org/10.1134/S0021364025609649.
Автор: Игорь Воронцов
#новостиЗАнауку