
Вы покупаете ссылки, пишите лонгриды, шаманите с перелинковкой, но трафик стоит на месте. Или, что еще хуже, позиции скачут: сегодня по запросу ранжируется категория, завтра – карточка товара, а послезавтра сайт вообще вылетает за топ-30.
В 90% случаев проблема не в алгоритмах Google или «шторме» Яндекса. Ваш сайт поедает сам себя. Страницы борются друг с другом за одни и те же запросы, размывая ссылочный вес и запутывая поисковых роботов.
Дальше – сухая инструкция: как диагностировать проблему за 15 минут, чем отличается каннибализация запросов от технических дублей и жесткий алгоритм действий – что удалять, что клеить, а что спасать.
Разница между техническими дублями и каннибализацией
Смешивать эти понятия – главная ошибка новичков. Лекарство для одного убьет другое.
Технические дубли – это полные клоны одной и той же страницы, доступные по разным адресам. Они возникают из-за кривой настройки CMS или хостинга. Контент на них идентичен на 100%.
Примеры технических дублей:
- site.ru/page и site.ru/page/ (со слешем и без).
- http://site.ru и https://site.ru.
- site.ru/index.php и site.ru.
- UTM-метки в URL, которые индексируются (?utm_source=...).
Каннибализация – это наличие двух и более разных страниц, которые оптимизированы под один и тот же интент (намерение) и ключевые слова. У них разный URL, разный текст, но для поисковика они отвечают на один и тот же вопрос пользователя.
Последствия катастрофичны в обоих случаях:
- Потеря позиций. Поисковик не понимает, какую страницу показать, и часто понижает обе.
- Размытие веса. Внешние ссылки ведут на разные URL, сила домена распыляется.
- Слив ресурсов. Краулинговый бюджет расходуется впустую. Робот тратит лимиты на сканирование мусора вместо индексации новых важных статей.
Симптомы проблемы: как понять, что сайт «болен»
Диагностика занимает пару минут, если знать куда смотреть.
1. Мигание релевантной страницы (URL Flipping)
Это самый явный признак. Вы проверяете позиции в топвизоре или другой системе съема, и видите, что по запросу «купить слона» сегодня показывается /category/slon, а вчера была /product/slon-rozoviy. Google или Яндекс не могут выбрать лидера и постоянно меняют URL в выдаче.
2. Стагнация на 10–20 позициях
У вас есть две сильные статьи про «выбор слонов». Обе качественные. Но ни одна не заходит в топ-3. Они делят релевантность пополам, и конкуренты с одной четкой страницей легко обходят вас.
3. Ошибки в панелях вебмастеров
Яндекс Вебмастер / Google Search Console прямо сигнализируют о проблеме.
- В Яндексе: статус «Дубль» или «Недостаточно качественная страница» в разделе «Страницы в поиске».
- В Google: статус «Страница просканирована, но пока не проиндексирована» или «Копия, Google выбрал другую страницу как каноническую».
Как найти дубли страниц: инструменты и методы
Не нужно гадать – используйте софт.
1. Ручной поиск (операторы поиска)
Самый быстрый способ проверить конкретный кластер. Введите в поисковую строку Google или Яндекса:
site:vash-site.ru "основной ключевой запрос"
Если выдача показывает 5–10 страниц на один узкий запрос – у вас каннибализация.
2. Сканирование сайта (Screaming Frog SEO Spider / Netpeak Checker)
Запустите полный парсинг сайта. После завершения отсортируйте результаты:
- По Title: Одинаковые заголовки на разных URL – это дубликаты страниц сайта в чистом виде.
- По H1: Часто Title уникализируют скриптом, а H1 остается одинаковым. Это тоже сигнал бедствия.
3. Панели вебмастеров
- Google Search Console: Раздел «Покрытие» (или «Индексация страниц»). Ищите вкладку «Исключено» с пометкой «Дубликат».
- Яндекс Вебмастер: Раздел «Индексирование» -> «Страницы в поиске» -> «Исключенные». Фильтруйте по статусу «Дубль».
4. Профессиональные сервисы
Для больших проектов (E-commerce, агрегаторы) ручной поиск не подходит.
- Rush Analytics / Topvisor: Есть модули проверки каннибализации. Они подсвечивают запросы, по которым в выдаче меняется релевантная страница.
- Инструменты Арсенкина: Выгрузка ТОП-10 по запросу. Если там две ваши страницы – вы конкурируете сами с собой.
Алгоритм принятия решений
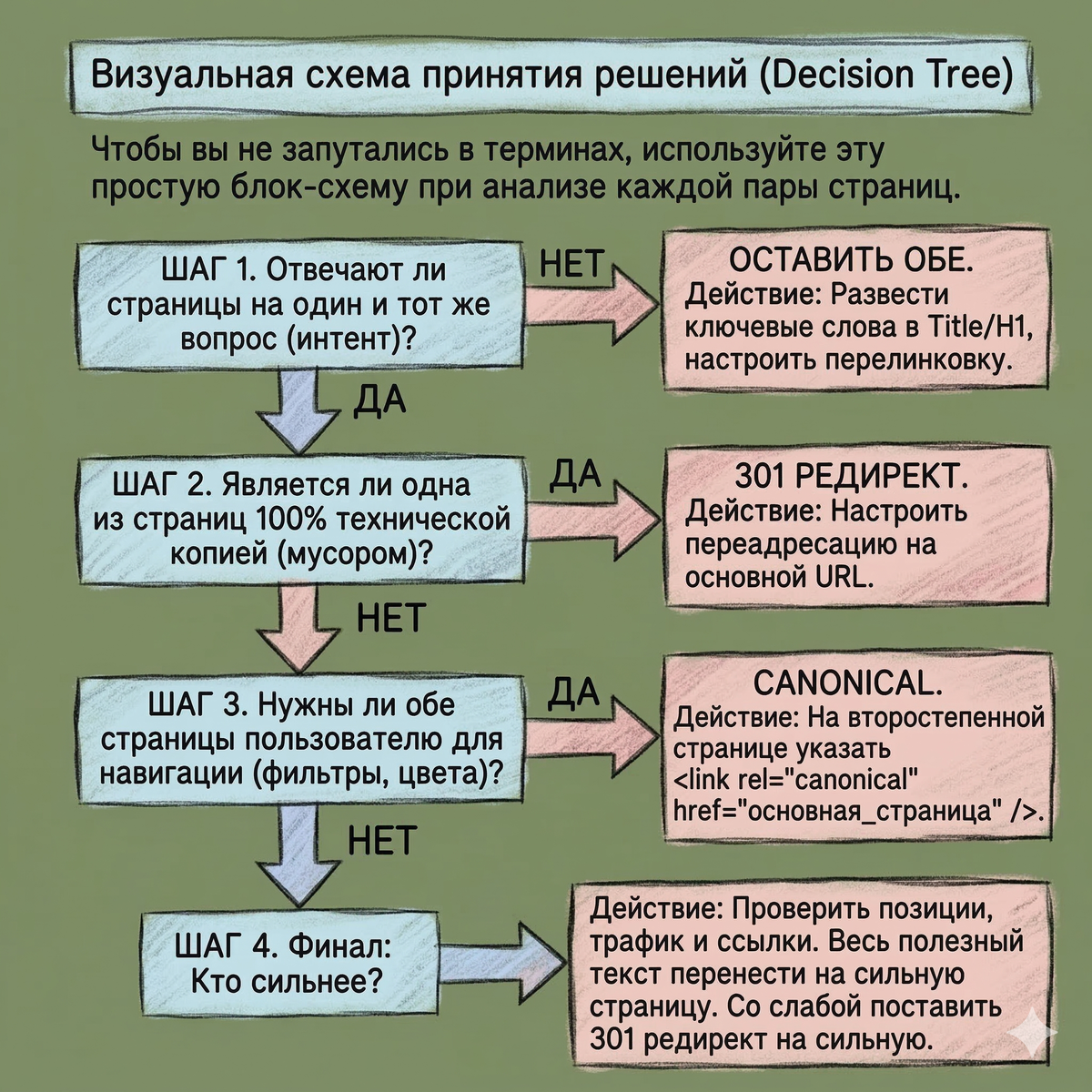
Вы нашли проблемные страницы. Что с ними делать? Используйте эту логику, чтобы не убить трафик.
Сценарий 1: Разный интент (ОСТАВЛЯТЬ)
У вас есть карточка «iPhone 13» (купить) и статья «Обзор iPhone 13» (инфо). Они могут пересекаться по ключам, но решают разные задачи.
- Решение:Жестко разведите семантику. На коммерческой странице уберите слова «обзор», «отзывы», «фото». В статье уберите «купить», «цена», «корзина».
Уникализируйте Title и H1.
Сделайте перелинковку: со статьи ссылку «Купить» на товар, с товара – «Читать обзор» на статью.
Сценарий 2: Одинаковый интент, одна тема (СЛИВАТЬ)
Две статьи: «Как выбрать кроссовки для бега» и «Советы по выбору беговой обуви».
- Решение:Выберите страницу с лучшими показателями (трафик, возраст, ссылки). Это донор-победитель.
Перенесите весь уникальный и полезный контент со второй страницы на первую. Сделайте ультимативный гайд.
Настройте 301 редирект со старой страницы на обновленную.
Склейка страниц передаст ссылочный вес и поведенческие факторы.
Сценарий 3: Технические дубли (РЕДИРЕКТИТЬ)
Здесь контент спасать не нужно – он идентичен.
- Решение: Ставьте 301 редирект с дубля на основной URL. Это единственный способ сказать поисковику: «Эта страница переехала навсегда, забудь старый адрес».
Сценарий 4: Страницы нужны пользователю, но не поиску (CANONICAL)
Пример: Карточка товара в красном цвете и такая же в синем. Или страницы сортировки каталога («по цене», «по популярности»). Удалять их нельзя – ими пользуются люди.
- Решение: Используйте тег rel="canonical". В коде страницы-дубля пропишите ссылку на основную страницу. Пользователь видит обе, робот индексирует только главную.
Шпаргалка: 301 редирект или canonical?
- Технический дубль
Инструмент: 301 Redirect
Пользователь переходит на главную страницу.
Робот склеивает ссылочный вес и удаляет дубликат из поискового индекса. - Старая статья дублирует новую
Инструмент: 301 Redirect
Пользователь попадает на актуальный материал.
Робот передает ссылочный вес старой новости новому адресу. - Сортировка, фильтры, UTM-метки
Инструмент: Canonical
Пользователь остается на текущей странице с выбранными параметрами.
Робот игнорирует адрес, ссылочный вес передается частично. - Пагинация
Инструмент: Canonical
Пользователь просматривает список товаров или постов.
Робот индексирует исключительно первую страницу.
Визуальная схема принятия решений (Decision Tree)
Специфика каннибализации в E-commerce
Интернет-магазины – главные жертвы каннибализации. Блоги страдают от похожих статей, а магазины – от умных фильтров.
Типичная ситуация: вы создали категорию «Красные кроссовки» (статический URL) для SEO. Но у вас есть умный фильтр, который при выборе цвета «Красный» в общей категории генерирует URL category/sneakers?color=red.
Итог: Две страницы с одинаковым набором товаров.
Что делать:
- Закрывать параметры. Параметрические страницы (?sort=, ?price_min=) нужно закрывать от индексации через Meta Robots noindex, follow или через robots.txt (менее надежно для Google).
- Генерировать ЧПУ только под спрос. Не создавайте статические страницы под пересечение 5 фильтров («Красные зимние кроссовки 45 размера дешево»). Под них нет частотности. Ограничьтесь генерацией ЧПУ для фильтров первого и второго уровня (Категория + Бренд или Категория + Тип).
- Тегирование. Если создаете страницы тегов (подборки товаров), следите, чтобы они не дублировали структуру каталога. Тег «Ноутбуки Asus» убьет категорию «Ноутбуки -> Бренд Asus». Используйте теги только для неочевидных свойств («Ноутбуки для дизайнера»).
Использование ИИ (ChatGPT/Claude) для поиска каннибалов
Ручной анализ Excel-таблиц на 10 000 строк сводит с ума. Делегируйте эту рутину нейросети. Этот метод экономит часы работы.
Инструкция:
- Выгрузите из Screaming Frog или любой CMS список всех URL и их Title.
- Сохраните в CSV или скопируйте столбцы.
- Загрузите файл в ChatGPT или Gemini с промптом:
«Ты – SEO-аналитик. У меня есть файл со списком URL и заголовков (Title). Твоя задача: найти семантические дубликаты. Не ищи полное совпадение текста, ищи совпадение по смыслу/интенту. Сгруппируй страницы в кластеры, которые конкурируют друг с другом, и предложи, какую страницу сделать основной (исходя из логичности URL). Результат выдай в виде таблицы».
ИИ отлично понимает, что «Ремонт стиральной машины» и «Починить стиралку» – это каннибализация, хотя слова разные.
Вывод
Каннибализация – это тихий убийца SEO. Вы можете бесконечно наращивать ссылочную массу, но если фундамент сайта сгнил от дублей, роста не будет.
Сделайте аудит прямо сейчас:
- Вбейте site:vash-site.ru "ключевой запрос" в поиске.
- Выгрузите отчет «Исключенные» в вебмастерах.
- Склейте 301 редиректом очевидные повторы.
Чистая структура – это быстрый краулинг, понятная релевантность и рост позиций без дополнительных бюджетов.
FAQ
Влияет ли canonical на краулинговый бюджет?
Частично. Робот все равно должен зайти на страницу, чтобы увидеть этот тег. Но он не будет тратить ресурсы на переобход дубля так часто, как на обычную страницу. Редирект 301 экономит бюджет эффективнее.
Можно ли просто удалить старую страницу каннибала (код 404)?
Только если на нее нет трафика и внешних ссылок. Если на страницу кто-то ссылался, удалив её, вы потеряете ссылочный вес. Лучше всегда делать 301 редирект на актуальный материал.
Как долго переклеиваются страницы в Яндексе и Google?
После настройки 301 редиректа Google реагирует за 1–3 недели. Яндекс более инертен – процесс склейки зеркал или переиндексации может занять от 2 до 5 недель по опыту. Ускорить процесс можно инструментом «Переобход страниц» в Яндекс Вебмастере и постингом ссылок в соцсетях.
Что делать, если Google игнорирует canonical и индексирует дубль?
Такое бывает, canonical – это рекомендация, а не приказ. Если Google упорствует, усильте сигнал: поставьте 301 редирект (если возможно) или уберите контент с дубля, оставив только ссылки, чтобы страница стала «тонкой» и неценной для поиска.