В современном мире для нас уже привычно общение с нейронными сетями в самых разных сферах. Мы пишем промпт (текст запроса в нейросеть) и получаем ответ. Но вам никогда не было интересно как именно нейронные сети понимают наш “естественный язык”?
Очевидно, компьютер не может понять наш язык, так же как и любой другой, кроме цифрового. Таким образом, чтобы достичь “взаимопонимания” с ЭВМ, первым делом необходимо преобразовать текст в численный вид.
Токенизация
Первый этап работы с текстом — токенизация. Токенизация преобразует строку из букв и пробелов в последовательность токенов — базовых единиц текста. Стоит заметить, что токен — минимальная единица текста, которую модель может обработать; он не атомарен и часто состоит из подтокенов.
Проще всего организовать токенизацию с помощью словаря, где каждому слову соответствует уникальное число — индекс.
Однако, перед тем как разбить текст на токены токенизатор выполняет нормализацию.
Предположим, мы токенизируем предложение “The cat loves cats”. Без нормализатора токенизатор воспримет слова “cat” и “cats” как отдельные токены, что не будет верным. А благодаря нормализатору, мы приводим слова в их начальные формы, удаляем ненужные пробельные символы и понижаем регистр.
Кроме того, в текст часто добавляют специальные токены — например, чтобы отметить начало или конец предложения, выделить вопрос или обозначить пропуски. Эти маркеры помогают модели лучше понять структуру и смысл текста.
Итак, мы с вами получили список токенов. Следующий шаг — преобразовать в численный формат — векторизовать. Под вектором будем подразумевать упорядоченную строку чисел (одномерный массив)
Векторизация
Рассмотрим несколько наиболее популярных методов векторизации: One-hot encoding, Bag of words, TF-IDF
Ссылка на используемое изображение
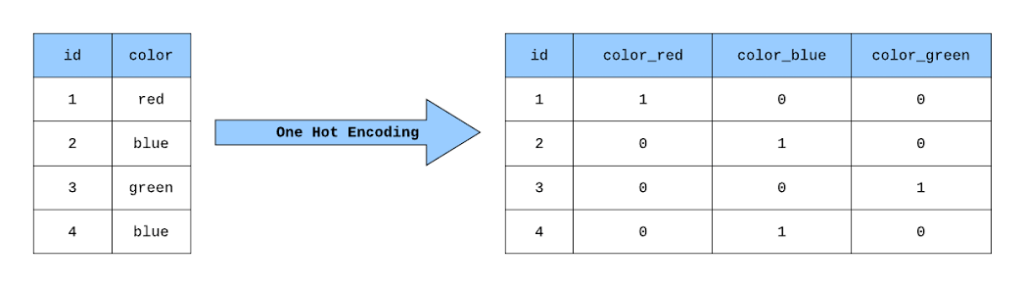
One-hot encoding — самый просто и примитивный метод, результатом которого является матрица с единицами и нулями внутри. 1 говорит о том, что какой-то текстовый элемент встречается в предложении (или документе). 0 говорит о том, что элемент не встречается в предложении. Однако, этот метод имеет существенный минус — при большом количестве токенов (сотни или тысячи), это приведёт к так называемому «проклятию размерности» — резкому увеличению числа признаков, что может значительно ухудшить качество модели
Bag of Words (мешок слов) формирует вектор на основе частоты вхождения слов в текст. Каждому слову из словаря соответствует значение — количество появлений данного слова в документе или предложении. BoW учитывает только частоту слов, но не порядок и контекст, поэтому данный метод и называется “мешок слов”
Наиболее продвинутый метод для анализа — TF-IDF. TF отражает частоту слова в одном документе, а IDF уменьшает вес часто встречающихся слов, чтобы выделить более значимые и редкие слова. Этот метод помогает модели лучше различать ключевые слова в тексте.
Векторизация и токенизация служат для преобразования слов и текстов в численные векторы, которые нейронные сети могут обрабатывать.В нейронных сетях этот метод используется для предобработки текста перед его передаче нейронной сети, в частности, например архитектуре RNN, в которой подробно говорится в следующей статье
Источники:
- Объяснение для новичков // dmt.ru URL: https://www.dmt.ru/publications/vektorizatsiya-zaprosov-obyasnenie-dlya-novichkov/
- Текст в NLP: от слов к числам // blog.skillfactory.ru URL: https://blog.skillfactory.ru/vektorizatsiya-teksta-v-nlp-ot-slov-k-chislam/
- Векторизация // fadeevlecturer.github.io URL: https://fadeevlecturer.github.io/python_lectures/notebooks/numpy/vectorization.html
Информация и произведении:
Автор: Вероника Алексеенко-Недышилова
Редакторы: Сабуров Даниил и Марк Ершов
Условия использования: свободное некоммерческое использование при условии указания автора и ссылки на первоисточник.
Для коммерческого использования — обращаться на почту: buildxxvek@gmail.com