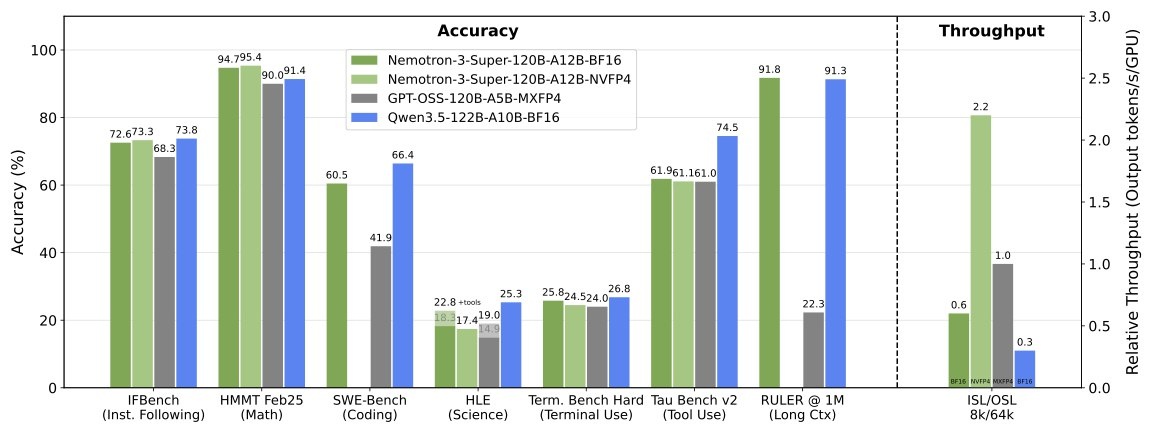
Nvidia представила новую языковую модель — без громких заявлений, тихо и по делу. Упор сделали на эффективность и локальный запуск, а не на рекорды в бенчмарках. Что внутри: Работает на обычных RTX — никаких серверов, домашняя видеокарта справляется без проблем Заточена под RAG — анализирует корпоративные базы, таблицы и большие внутренние документы Генерирует синтетические данные — создаёт датасеты для обучения других, более мелких моделей Nvidia методично забирает всю цепочку: железо, софт, теперь ещё и модели под конкретные задачи. Для компаний это выгодно — данные остаются локально, никаких сторонних API и утечек. 🔒 Полезные нейронки 4 способа оплатить нейронки
🟢 Nvidia выкатила Nemotron-3 Super
Nvidia представила новую языковую модель — без громких заявлений, тихо и по делу. Упор сделали на эффективность и локальный запуск, а не на рекорды в бенчмарках.
Что внутри:
Работает на обычных RTX — никаких серверов, домашняя видеокарта справляется без проблем
Заточена под RAG — анализирует корпоративные базы, таблицы и большие внутренние документы
Генерирует синтетические данные — создаёт датасеты для обучения других, более мелких моделей
Nvidia методично забирает всю цепочку: железо, софт, теперь ещё и модели под конкретные задачи. Для компаний это выгодно — данные остаются локально, никаких сторонних API и утечек. 🔒