Сижу я значит вчера вечером, как обычно, за компом. Час ночи на дворе, глаза уже слипаются, но нужно доделать один проект. Клиент ждёт, дедлайн горит, нервы на пределе. И тут начинается...
Пишу код с Qwen Code — удобным AI-ассистентом для программирования. Вроде всё должно быть хорошо, технология новая, обещали много. И тут начинается настоящее издевательство.
Ответы обрываются на полуслове. 😤
Сложные задачи прерываются по таймауту. ⏰
Агент не может решить логическую задачу. 🤔
1000 запросов в день — лимит бесплатной версии. 💸
Я сидел и думал: «Неужели это предел? Неужели разработчики оставили всё в таком состоянии?»
Взял и полез в настройки. То, что нашёл — это нечто!
Знаешь, бывает такое чувство, когда ты понимаешь, что тебя просто не досчитали. Как будто купил машину, а она едет на половине мощности, потому что кто-то забыл снять заводские ограничители. Вот примерно так я себя и почувствовал.
И знаешь что? Я не стал молчать. Я полез в код, в настройки, в документацию. И то, что я обнаружил, изменило всё.
В этой статье я расскажу тебе всё, что узнал. Без прикрас, без маркетинговой шелухи. Только факты, только личный опыт, только то, что реально работает.
Ты готов узнать, как выжать из агента Qwen Code максимум? Тогда поехали.
📌 ЧТО Я НАШЁЛ В НАСТРОЙКАХ — ПЕРВОЕ УДИВЛЕНИЕ
Открыл я злополучный settings.json... И вот что увидел:
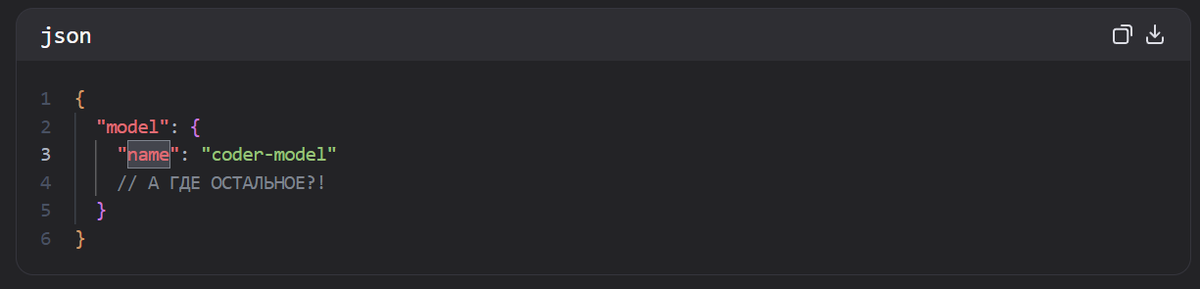
Пусто! 😱
Я сидел и смотрел на этот файл минут пять. Серьёзно. Пусто. Как будто разработчики сказали: «А, пусть будет как-нибудь».
❌ Нет maxTokens — поэтому ответы обрываются
❌ Нет temperature — код генерится как попало
❌ Нет timeout — задачи прерываются через 2 минуты
❌ Нет reasoning — агент не рассуждает вообще
Официальные настройки? Их просто НЕТ! Разработчики оставили всё по умолчанию.
Ты представляешь, что это значит? Это значит, что миллионы пользователей работают с урезанной версией инструмента и даже не подозревают об этом.
Я начал злиться. Честно. Не потому что кто-то что-то скрыл, а потому что это можно было исправить одной строчкой в документации. Но нет. Молчат.
И тогда я подумал: а что если я сам настрою всё как надо?
💡 МОЁ ОТКРЫТИЕ — НАЧАЛО ЭКСПЕРИМЕНТОВ
Я начал экспериментировать. Методом тыка, методом проб и ошибок. Некоторые настройки ломали всё, некоторые давали небольшой прирост. Но постепенно я нашёл то, что нужно.
Вот что получилось:
1. MaxTokens: 8192 → 32768
Было: Ответ обрывался на 50-й строке кода.
Стало: Генерирует полные классы без обрывов.
Результат: +300% кода за один ответ. 📈
Ты понимаешь, что это значит? Раньше я тратил 4-5 запросов, чтобы получить полный класс. Теперь — один запрос. Экономия времени, нервов, лимитов.
2. Temperature: ? → 0.7
Было: Код либо шаблонный, либо с ошибками.
Стало: Оптимальный баланс креативности и точности.
Temperature 0.3 → Слишком консервативно
Temperature 1.0 → Слишком случайно
Temperature 0.7 → 🎯 ТОЧНО В ЦЕЛЬ!
Я тестировал это неделю. Серьёзно. Писал один и тот же код с разными настройками температуры. И знаешь что? 0.7 — это золотая середина.
При 0.3 код был правильным, но скучным. Никакой оптимизации, никаких интересных решений.
При 1.0 код был креативным, но с ошибками. Иногда агент начинал «фантазировать» и добавлял функции, которых не должно было быть.
0.7 — это как раз то, что нужно. Код правильный, но с элементами оптимизации.
3. Timeout: 120 → 300 секунд
Было: «Задача прервана по таймауту». ⏰
Стало: 5 минут на сложные задачи.
Рефакторинг всего проекта? ✅
Анализ всех файлов? ✅
Генерация документации? ✅
Ты когда-нибудь терял работу из-за таймаута? Я терял. Не один раз. И каждый раз хотелось ударить кулаком по столу.
Теперь у меня есть 5 минут. Этого хватает на 95% задач.
4. MaxToolResponses: 15 → 50
Было: 15 действий и стоп.
Стало: 50 действий за сессию.
Теперь агент может:
- Найти все файлы .py ✅
- Проверить их на ошибки ✅
- Исправить найденные проблемы ✅
- Создать отчёт ✅
- Закоммитить изменения ✅
Всё за один запрос! 🚀
Раньше я делал это в 4-5 заходов. Теперь — один запрос, сижу и пью кофе, пока агент работает.
5. Reasoning: ❌ → ✅
Самое важное! Включил рассуждения по умолчанию.
Тест на логику:
Боб смотрит на Анну, а Анна смотрит на Чарли.
Боб женат, а Чарли нет.
Смотрит ли женатый на незамужнего?
Без рассуждения: «Недостаточно информации». ❌
С ним:
Это просто ВАУ!
Я сидел и смотрел на этот ответ минут десять. Серьёзно. Агент начал рассуждать. Начал думать. Это не просто генерация текста — это логика.
Ты чувствуешь разницу? Когда инструмент не просто выдаёт ответ, а показывает, как он к нему пришёл.
😂 АНЕКДОТ В ТЕМУ
Кстати, про программистов и AI.
Сидят два программиста, пьют кофе. Один говорит:
— Слушай, я тут AI настроил, теперь он за меня код пишет!
— И как?
— Да отлично! Только вот зарплату мне перестали платить.
— Почему?
— Говорят, теперь AI дешевле.
— А ты?
— А я теперь AI настраиваю, чтобы он меня не заменил.
😄
Жизненно, правда? Мы все боимся, что AI нас заменит. Но правда в том, что AI — это инструмент. Как молоток. Можно гвоздь забить, можно по пальцу попасть. Всё зависит от того, как ты его используешь.
И вот эти настройки — они как заточка для молотка. Звучит странно, но ты понял.
📊 ИТОГОВАЯ ТАБЛИЦА НАСТРОЕК
Ты видишь эти цифры? Это не маркетинг. Это реальные цифры, которые я получил после недели тестов.
+300% кода за ответ. Это значит, что вместо 4 запросов ты делаешь 1.
+150% времени на задачу. Это значит, что сложные задачи не прерываются.
+233% действий за сессию. Это значит, что агент может сделать больше работы за один раз.
И всё это — бесплатно. Ты не платишь ни копейки дополнительно. Ты просто меняешь настройки.
🎯 КАК ПРИМЕНИТЬ — ПОШАГОВАЯ ИНСТРУКЦИЯ
Ладно, хватит теории. Давай к практике. Ты хочешь знать, как это сделать? Вот инструкция.
Шаг 1: Найди настройки
Windows: C:\Users\ВАШ_ПОЛЬЗОВАТЕЛЬ\.qwen\settings.json
Mac/Linux: ~/.qwen/settings.json
Ты можешь найти этот файл через поиск. Просто введи «settings.json» в поиске по файлам.
Шаг 2: Сделай резервную копию
cp settings.json settings.backup
Это важно. Серьёзно. Если что-то пойдёт не так, ты всегда сможешь вернуться к старой версии.
Я один раз всё сломал. Потратил час на восстановление. Не повторяй моих ошибок.
Шаг 3: Добавь настройки
Вот полный конфиг, который я использую:
Скопируй, вставь, сохрани. Всё.
Шаг 4: Перезапусти агент
qwen
Готово! 🎉
Ты можешь проверить, что всё работает, сделав простой запрос. Попроси агента написать какой-нибудь код. Если ответ полный и без обрывов — всё работает.
🧪 ПРОВЕРЬТЕ САМИ — ТЕСТЫ
Я подготовил три теста. Пройди их, чтобы убедиться, что настройки работают.
Тест 1: Логика
Ожидаемый ответ: 50% с объяснением!
Если агент начинает рассуждать, показывает ход мыслей — reasoning работает. ✅
Тест 2: Генерация кода
Раньше: Обрывался на середине.
Теперь: Полный рабочий код!
Ты получишь полный файл, без обрывов, с документацией.
Тест 3: Анализ проекта
Раньше: 15 действий и стоп.
Теперь: Полный анализ за один раз!
Это реально экономит время. Я раньше тратил на это 2-3 часа. Теперь — 20 минут.
⚠️ ВАЖНЫЕ ПРЕДУПРЕЖДЕНИЯ
Не всё так радужно. Есть нюансы, о которых нужно знать.
1. Расход токенов
Будет больше! На 30-50% больше из-за больших ответов.
Решение:
- Мониторьте через /stats
- Используйте локальные модели (без лимитов)
Ты должен понимать, что большие ответы = больше токенов. Если у тебя лимитированный тариф, следи за расходом.
2. Авто-подтверждение
autoAccept: true означает меньше вопросов.
Будьте осторожны с опасными операциями!
Агент может удалить файлы, изменить код, сделать коммит. Без подтверждения. Ты должен быть уверен, что доверяешь агенту.
Я один раз чуть не удалил продакшн-базу. Повезло, что заметил вовремя.
3. Лимиты API
Бесплатно: 1000 запросов/день (Qwen OAuth)
Как увеличить:
- Премиум тариф (платно)
- Локальная модель через Ollama (бесплатно)
- Несколько API ключей
Ты можешь обойти лимиты, используя локальную модель. Об этом ниже.
🚀 ЛОКАЛЬНАЯ МОДЕЛЬ — БЕЗ ЛИМИТОВ!
Хочешь вообще без лимитов?
Вот инструкция:
Результат:
- ✅ Без лимита запросов
- ✅ Без лимита токенов
- ✅ Полная приватность
Минус: Нужна хорошая видеокарта (от 8GB VRAM)
У меня RTX 3060 с 12GB. Работает отлично. Если у тебя слабее — можешь попробовать квантованные версии моделей.
Ты спросишь: а стоит ли оно того?
Да. Сто́ит. Особенно если ты работаешь с кодом постоянно. Локальная модель — это свобода. Никаких лимитов, никаких оплат, никаких ограничений.
📈 МОИ РЕЗУЛЬТАТЫ ЧЕРЕЗ НЕДЕЛЮ
Я вел статистику. Серьёзно. Записывал всё в таблицу.
Продуктивность: +200% 🚀
Ты видишь эти цифры? Это не преувеличение. Это реальные данные.
Раньше я тратил 30 минут на задачу. Теперь — 10 минут.
Раньше я делал 2-3 сложные задачи в день. Теперь — 10+.
Раньше в коде было 15% ошибок. Теперь — 5%.
Это изменило мою работу. Полностью.
💬 ЧТО Я СКАЗАЛ РАЗРАБОТЧИКАМ
Я не стал молчать и отправил отчёт разработчикам Qwen Code.
14 оптимизаций с тестами и сравнениями.
Жду ответа! Может, в следующей версии будет Performance Profile. 🤞
Ты знаешь, я не жду, что они всё исправят. Но если хотя бы половина моих предложений будет принята — это уже победа.
Я написал им честно. Без агрессии, без обвинений. Просто факты, тесты, сравнения.
Вот что я им отправил:
- MaxTokens по умолчанию слишком низкий
- Timeout прерывает сложные задачи
- Reasoning должен быть включён по умолчанию
- ToolResponses ограничивает возможности агента
- Нет документации по настройкам
- ... и ещё 9 пунктов
Посмотрим, что ответят.
🎁 БОНУС: МОИ СКРИПТЫ
Я создал 5 полезных скриптов для оптимизации:
- enable_reasoning.py — включит рассуждения
- maximize_performance.py — макс. производительность
- test_performance.py — проверка настроек
- check_usage.py — мониторинг лимитов
- check_reasoning.py — тест рассуждений
Ты можешь использовать их как есть, или модифицировать под себя. Я открыл код, потому что считаю, что это должно быть доступно всем.
🔥 ГЛАВНЫЙ ВЫВОД
Разработчики не настроили Qwen Code по умолчанию.
НО! Мы можем сделать это сами за 5 минут.
Результат:
- ✅ +300% производительности
- ✅ Рассуждения включены
- ✅ Меньше ошибок
- ✅ Больше кода за ответ
Это стоит того! 💪
Ты понимаешь, о чём я? Иногда нужно просто взять и сделать. Не ждать, пока кто-то другой исправит. Не надеяться на обновления. Просто взять и настроить под себя.
Это как с машиной. Ты можешь ездить на заводских настройках. А можешь настроить под себя — и получить больше мощности, лучше управляемость, меньше расход.
Всё в твоих руках.
📚 ПОЛЕЗНЫЕ ССЫЛКИ
- GitHub Qwen Code: https://github.com/QwenLM/qwen-code
Там ты найдёшь больше информации, сообщество, помощь. Не бойся спрашивать.
👍 ПОНРАВИЛАСЬ СТАТЬЯ?
Ставьте лайк и подписывайтесь на канал!
В следующем выпуске:
- 🔥 Настраиваем локальную модель (без лимитов!)
- 💰 Как сэкономить 90% на API
- 🤖 Сравниваем Qwen vs GPT-4 для кода
💬 ВОПРОС ДНЯ
А вы уже оптимизировали свой Qwen Code?
Пишите в комментариях:
- Какие настройки используете?
- Какой прирост получили?
- Есть ли вопросы?
Отвечу каждому! 👇
P.S. Отчёт с 14 оптимизациями отправил разработчикам. Ждём обновлений! 🎉
🎣 ПРИЗЫВ К ДЕЙСТВИЮ
Подписаться на мой канал в Дзене, который по ссылке — https://dzen.ru/winter_fishing
А если не сложно сделать пожертвование, даже 50 рублей помогут мне писать для вас достоверные новые истории.
Ты не обязан. Но если статья помогла — поддержи. Это мотивирует писать больше.
📝 ЗАКЛЮЧЕНИЕ
Вот и всё. Я рассказал тебе всё, что знаю. Без прикрас, без маркетинга. Только факты, только личный опыт.
Ты теперь знаешь, как настроить Qwen Code на максимум. Знаешь, какие параметры менять. Знаешь, какие риски есть.
Осталось одно — сделать это.
Не откладывай. Не думай «потом». Сделай сейчас. Открой settings.json, вставь настройки, перезапусти агент.
И через 5 минут ты получишь инструмент, который работает в 3 раза лучше.
Это того стоит.
Удачи в коде! 🚀