🔬⚡ Mamba3 + Gated Attention: экспериментальный гибрид на 190M параметров бросает вызов трансформерам
Пока индустрия масштабирует гигантов, энтузиасты проверяют эффективность Mamba3 — третьего поколения архитектуры SSM (State Space Models — модели, где вычислительная сложность растет линейно, а не квадратично от длины контекста). Модель Mamba3-Gated-Attention-190m объединяет сильные стороны селективного сканирования и механизмов внимания, пытаясь выжать максимум из крошечного веса.
Главная фишка этого гибрида — использование Gated Attention вместе с обновленным блоком Mamba3. Это позволяет модели лучше фокусироваться на релевантных частях контекста, сохраняя при этом сверхбыстрый инференс, характерный для SSM. Разработчик модифицировал стратегию инициализации и нормализации, а также оптимизировал работу с внутренним кэшем, что позволило устранить ошибки нестыковки длины последовательностей при чанковой обработке.
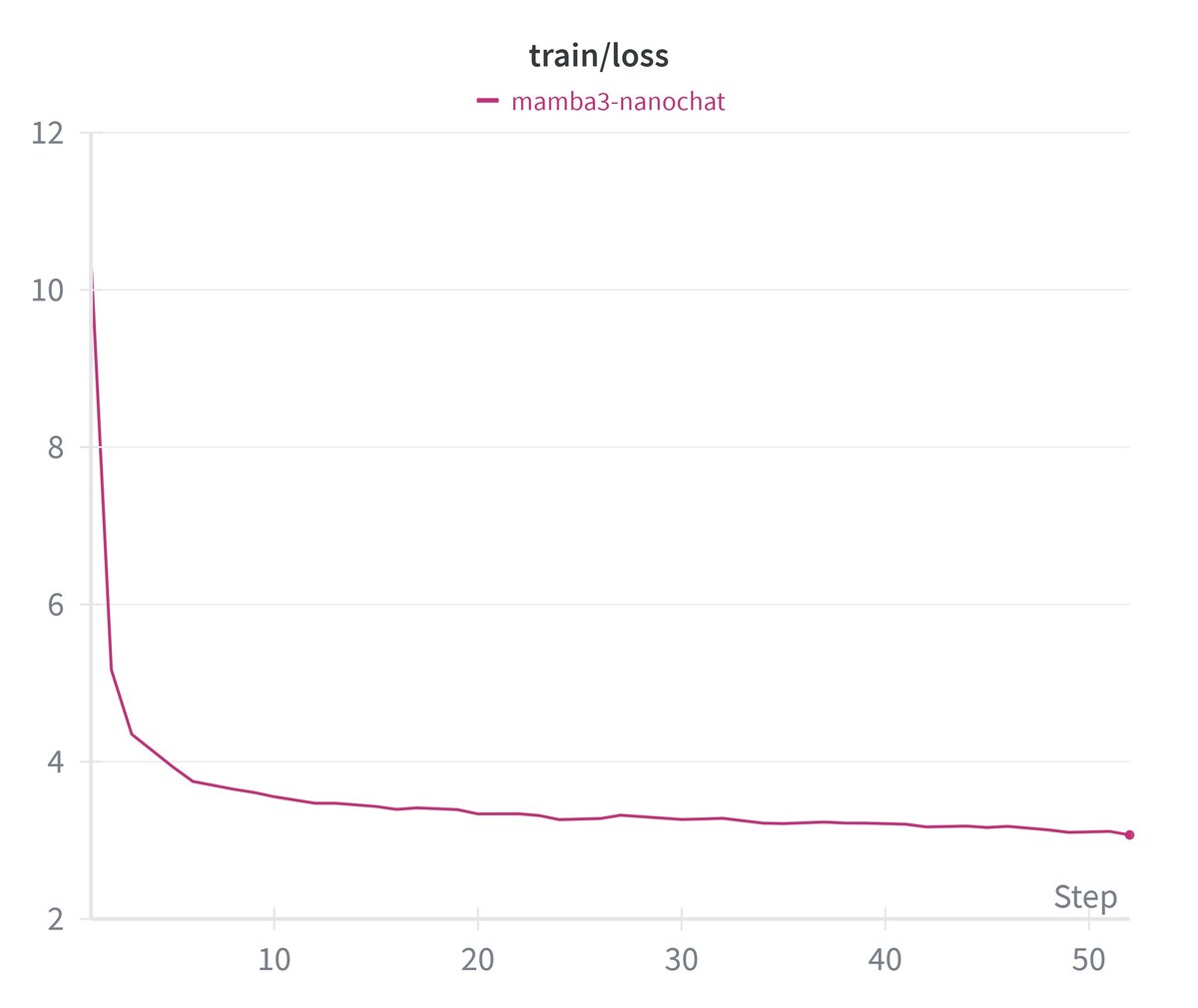
На тестах модель показывает 0.2662 на ARC-Challenge (сложные вопросы из школьной программы) и 0.2554 на MMLU (тест на общие знания в 57 областях). Для веса в 190M параметров, обученного всего за 137 минут, это достойный результат «карманного» уровня. Обучение проходило на датасетах FineWeb-Edu-100B и SmolTalk, что дало модели неплохие базовые навыки рассуждений для её размера.
Попробовать модель в деле можно через transformers:
model = AutoModelForCausalLM.from_pretrained("RikkaBotan/Mamba3-Gated-Attention-gpt2-hybrid-190m-instruct", trust_remote_code=True)
Такие эксперименты показывают, что будущее за гибридными архитектурами: они эффективнее чистых трансформеров на длинном контексте и при этом не теряют в качестве генерации.
#AI #Mamba3 #SSM #OpenSource #HuggingFace #MachineLearning
🔗 RikkaBotan/Mamba3-Gated-Attention-gpt2-hybrid-190m-instruct