
Введение
Современные системы искусственного интеллекта сталкиваются с
тремя фундаментальными проблемами, которые ограничивают их развитие. Катастрофическое забывание заставляет нейросети стирать старые знания при обучении новым классам. Отсутствие доверия связано с тем, что модели не умеют говорить «я не знаю» — они всегда выдают ответ, даже если он случаен. Статичность векторных представлений
мешает адаптации: векторные базы данных (FAISS, Milvus) хранят
неизменные эмбеддинги, и любое обновление требует глобального пересчёта.
В поисках решения я разработал принципиально новый подход — Нейровесовые Поля (Neural Weight Fields, NWF).
Идея родилась из синтеза байесовского вывода, теории поля и имплицитных
нейронных представлений. Вместо хранения данных в виде пассивных битов,
NWF представляет каждый объект как заряд — небольшой
«сгусток» информации, обладающий координатами в семантическом
пространстве и собственной мерой неопределённости. Множество зарядов
создают семантическое поле, подобное электрическому или гравитационному. Поиск и классификация выполняются путём движения в этом поле к ближайшим зарядам.
В этой статье я впервые представляю полную картину: что такое
Нейровесовые Поля, как они работают, какие преимущества дают, и где они
уступают существующим подходам. Я проведу честное сравнение с
сильнейшими базовыми методами: FAISS (векторный поиск), HDC (hyperdimensional computing), EWC, Fine-tuning и iCaRL (continual learning). Результаты вас удивят.
Код, эксперименты и инструкции по воспроизведению доступны в репозитории: nwf-research.
1. Теория Нейровесовых Полей (NWF)
1.1. Идея: данные как модель
В классической архитектуре фон Неймана данные пассивны, а
программа активна. В мозге же память и вычисления неразрывны.
Нейровесовые Поля предлагают парадигму, в которой каждый объект данных сам является моделью. Каждый факт, каждое изображение, каждое слово превращается в заряд — небольшой «сгусток» информации, обладающий не только координатами в семантическом пространстве, но и собственной мерой неопределённости. Эти заряды создают вокруг себя потенциалы, а множество зарядов формируют семантическое поле.
Запрос, попадая в это поле, движется к ближайшим зарядам под действием
градиента потенциала, и на основе их «мнения» принимается решение.
Математически это оформляется через систему аксиом, где каждому ядру zi ставится в соответствие гауссов потенциал φi(r) = exp(−½ (r−zi)ᵀ Σi−1(r−zi)), а результирующее поле есть суперпозиция с весами αi.
Веса позволяют управлять важностью разных объектов — например,
проверенные данные могут иметь больший вес, чем экспериментальные. Это
даёт гибкость при построении семантических хранилищ.
1.2. Суперпозиция и веса: как знания накапливаются, а не перезаписываются
В классических системах, когда вы добавляете новый объект в базу
знаний, вы либо перестраиваете весь индекс, либо просто кладёте его
рядом, но он не влияет на уже существующие представления. В NWF же
работает принцип суперпозиции полей: каждый новый заряд
добавляет свой потенциал к общему полю, изменяя его конфигурацию. При
этом старые заряды остаются нетронутыми — мы не перезаписываем их, а
просто добавляем новые. Более того, мы можем назначать каждому заряду вес αi.
Это позволяет, например, придавать больший вес экспертным данным,
снижать влияние устаревшей информации или даже динамически
корректировать вклад каждого объекта в процессе работы системы. Таким
образом, NWF реализует идею непрерывного накопления знаний без потери старого опыта — то, что в человеческом обучении называется «жизненным опытом».
1.3. Ключевые следствия
- Семантическое сходство двух объектов измеряется расстоянием Махаланобиса, учитывающим неопределённость: dM² = (zi−zj)ᵀ (Σi+Σj)−1(zi−zj). Это исправляет ошибку ранних версий, где использовалась только ковариация запроса.
- Поиск по запросу Q: кодируем запрос в (zq, Σq), затем ищем заряды с минимальным dM. Результаты взвешиваются по значению потенциала в точке запроса.
- Добавление новых знаний — просто добавляем новый заряд в хранилище. Никакого переобучения модели не требуется.
- Неопределённость ковариации позволяет системе выражать уверенность в своих ответах, что критически важно для доверенного ИИ.
Более подробно математический аппарат изложен в препринте. Здесь же мы сосредоточимся на практической реализации и результатах.
2. Методология экспериментов
Все эксперименты проведены на датасете MNIST (рукописные цифры, 60k тренировочных, 10k тестовых). Для инкрементального обучения использован Split-MNIST с разбиением на три задачи: классы (0,1,2), затем (3,4,5), затем (6,7,8,9). Для OOD-детекции взят датасет Fashion-MNIST.
Для получения семантических ядер обучен вариационный автокодировщик
(VAE) с 64‑мерным латентным пространством, который даёт для каждого
изображения пару (z, Σ).
Базовые методы для сравнения: FAISS_L2 (статический эмбеддинг, 256 байт), HDC (гиперразмерные вычисления, 250 байт), EWC, Fine-tuning и iCaRL. NWF тестировался в вариантах: Euclidean (только z), Mahalanobis (асимметричный), Symmetric (симметричный Махаланобис), PQ (сжатие до 16 байт) и HNSW (ускоренный поиск).
3. Эксперимент 1: сжатие и точность поиска
Цель: выяснить, может ли NWF конкурировать с
FAISS по точности поиска при сопоставимом или лучшем сжатии.
Индексировалось 10 112 изображений, для 2 048 тестовых находили 10
ближайших соседей (Precision@10).
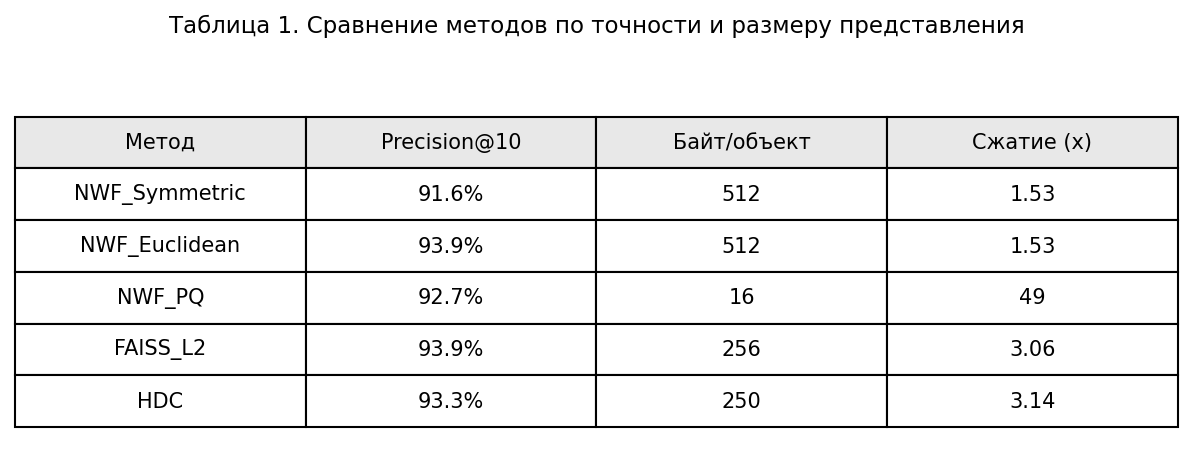
Анализ: NWF_Euclidean даёт ту же точность, что и
FAISS (93,9%), но занимает 512 байт из-за хранения ковариации.
NWF_Symmetric достигает 91,6% (всего на 2,3% ниже FAISS). NWF_PQ —
прорыв: сжатие 49 раз (с 512 до 16 байт) при потере точности всего 1%
(92,7% против 93,9%). Это делает NWF идеальным для встраиваемых систем и
мобильных приложений. HDC показывает хорошую точность (93,3%), но
сжатие хуже (3,1×).
4. Эксперимент 2: устойчивость к шуму
Цель: проверить, помогает ли учёт ковариации при
зашумлённых запросах. К тестовым изображениям добавлялся гауссов шум с
разными σ, затем выполнялась классификация (kNN с k=10).
Вывод: HDC устойчивее всех при умеренном шуме
(благодаря сверхвысокой размерности). Учёт ковариации (симметричный)
пока не даёт преимущества над евклидовой метрикой в шумных условиях, но
при очень сильном шуме NWF_Euclidean и FAISS держатся лучше HDC.
5. Эксперимент 3: инкрементальное обучение (без забывания)
Цель: проверить главное преимущество NWF —
добавление новых классов без доступа к старым данным и без
катастрофического забывания. Split-MNIST: три задачи по 1500 примеров.
NWF просто добавлял заряды новых примеров в хранилище; конкуренты
обучались последовательно.
Анализ: Матрица забывания (график 4) показывает,
что NWF сохраняет высокую точность на старых классах (классы 0,1 почти
100%, остальные 60–70%), тогда как EWC и Fine-tuning теряют целые
классы, а iCaRL даёт лишь 54% после трёх задач.
Вывод: NWF радикально превосходит существующие подходы в инкрементальном обучении. Это его главное уникальное преимущество.
6. Эксперимент 4: OOD-детекция
Цель: проверить, можно ли использовать ковариацию для обнаружения примеров, не принадлежащих распределению обучающей выборки.
AUC ROC: NWF_Mahalanobis 0,84–0,89, NWF_Potential 0,82–0,89, FAISS_L2 0,86–0,90.
Вывод: NWF пригоден для OOD-детекции — важное свойство для доверенного ИИ.
7. Эксперимент 5: калибровка уверенности
Цель: научиться получать из NWF хорошо калиброванные вероятности. Лучшая метрика — доля согласных соседей (agreement_ratio).
ECE до калибровки: agreement_ratio 0,14–0,21. ECE после Platt scaling: 0,03.
Вывод: после калибровки ECE снижается до 0,03 — уровень, приемлемый для практических приложений доверенного ИИ.
8. Эксперимент 6: скорость кодирования и поиска
VAE кодирует изображение за микросекунды (7e-6 сек), но даёт чуть худшую реконструкцию. Фильтр Калмана
(3 итерации) улучшает качество на 24% (MSE 0,0096 против 0,0126), но
работает на 4–5 порядков медленнее (0,21 сек). Выбор зависит от
сценария: для массовой индексации — VAE, для максимальной точности —
Kalman.
Поиск с HNSW ускоряется в 14–37 раз (с 0,46 мс
до 0,03 мс для 512 объектов, и с 1,93 мс до 0,05 мс для 2048 объектов),
что делает NWF масштабируемым до миллионов объектов.
9. Демонстрационные эксперименты
Семантическая интерполяция между зарядами цифр 3 и 5 даёт плавный переход смысла при декодировании промежуточных векторов.
Семантический ландшафт (t-SNE + контуры потенциала) показывает чёткие кластеры цифр, подтверждая, что поле действительно отражает семантику.
10. Итоги, перспективы и области применения
Подводя итог, можно сказать, что Нейровесовые Поля предлагают не просто очередной алгоритм, а новую философию работы с данными.
Вместо того чтобы хранить пассивные биты и потом тратить ресурсы на их
интерпретацию, мы сразу «заряжаем» данные смыслом и уверенностью. Это
даёт три ключевых преимущества: непрерывное обучение без забывания, встроенную оценку неопределённости и экстремальное сжатие.
Где это может пригодиться уже сегодня? Я вижу несколько направлений:
- Медицина: хранение медицинских изображений
- (МРТ, КТ) с возможностью добавлять новые диагнозы, не переобучая всю
- систему, и при этом получать не только результат, но и меру уверенности
- врача.
- Финансовый мониторинг: детекция аномалий и мошенничества в реальном времени — NWF легко адаптируется к новым схемам, не забывая старые.
- Робототехника и автономные системы: робот,
- работающий в меняющейся среде, должен постоянно учиться, но не терять
- ранее приобретённые навыки. NWF позволяет накапливать опыт, а не
- перезаписывать его.
- Видеонаблюдение и безопасность: сжатие видеопотоков до 16 байт на ключевой кадр с сохранением семантики — это радикальное сокращение хранилищ при сохранении возможности поиска по событиям.
- Персональные ассистенты: система, которая
- запоминает предпочтения пользователя и может обновлять их без полного
- переобучения, а также честно говорит: «я не уверен, уточни».
Что касается будущих направлений, я уже начал работу над квантовыми нейровесовыми полями (Q-NWF), где суперпозиция полей будет выполняться на квантовых компьютерах, что потенциально даст экспоненциальное ускорение. Также в планах — интеграция NWF с онтологиями и графами знаний, чтобы объединить субсимволическую гибкость полей с логической строгостью символьных систем. И, конечно, автоматический подбор архитектуры гипотезы H под конкретный тип данных — чтобы пользователь вообще не думал о настройках, а система сама находила оптимальное семантическое пространство.
Я считаю, что NWF — это шаг к созданию живых семантических хранилищ,
которые не просто хранят информацию, а понимают её и могут разумно
взаимодействовать с человеком. Надеюсь, что сообщество подхватит эту
идею, и мы вместе сможем сделать следующий шаг в эволюции искусственного
интеллекта.
Ссылки:
1. Белоусов Р.С. Нейровесовые поля: теория семантического континуума. Препринт, 2025. DOI: 10.24108/preprints-3113697
2. Репозиторий: github.com/romero19912017-ui/nwf-research
3. Библиотеки NWF: nwf-core, nwf-vision, nwf-nlp, nwf-recsys (установка: pip install nwf-core nwf-vision nwf-nlp nwf-recsys)
Автор: Белоусов Роман Сергеевич, независимый исследователь.
Исследования выполнены при поддержке лаборатории Terek AI созданной Лом-Али Хачукаевым.
#НейровесовыеПоля #SemanticField #ДанныеКакМодель #БайесовскийВывод #Махаланобис #ФильтрКалмана #СуперпозицияПоля #ЭлектродинамикаВML #ИнкрементальноеОбучение #ПамятьИИ #СемантическийПоиск #ФизикаВМашинномОбучении #NeuralWeightFields #BayesianInference #Mahalanobis #KalmanFilter #SuperpositionPrinciple #AIArchitecture #DynamicMemory