Всем привет, сегодня мы снова решаем задачи на LeetCode. На этот раз у нас вот такая задача, в двумерной матрице нужно найти значение. Казалось бы, всё так просто, но почему это эта задача помечена, как средняя по уровню сложности?
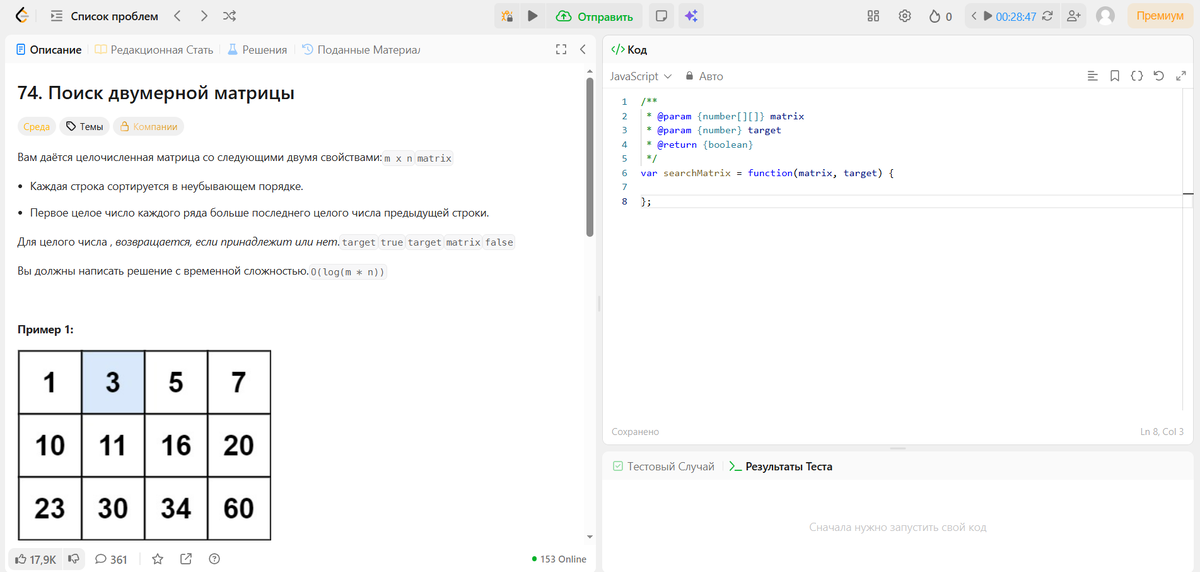
Внизу написано, что эту задачу решили 53.7% пользователей. А также, если внимательно прочитать условия, можно увидеть ограничения по времени. Странные, но ограничения. Похоже эта задачка не так проста, как кажется...
Сегодня мы попробуем её решить и понять, что же в ней такого сложного?
Начинаем решать
И так, давайте напишем код с обычным циклом, который тупо перебирает все значения. Как бы это не выглядело наивно, всё равно попробуем.
Запускаем... И всё работает
Но это подозрительно просто, помните о низком проценте решаемости этой задачи.
На LeetCode нужно ещё нажать на эту кнопочку, чтобы ваш код протестировался на разных данных в разных условиях
И конечно же я решил эту задачку. Никаких ограничений, но перед нами появляется довольно обидный рейтинг. Я оказался в самом хвосте, а хотелось бы решить эту задачу быстрее всех.
У нас есть два параметра, скорость и память, нужно постараться оптимизировать эту задачу
Начинаем оптимизировать
Если присмотреться к тому, с чем мы имеем дело, можно увидеть, что наш двумерный массив отсортирован в порядке возрастания.
Не обязательно строго проходиться по всему массиву с начала и до конца. Можно просто выбрать значение по середине массива и сравнить его с искомым, после чего, в зависимости от того, больше оно или меньше, пойти искать его в нужную сторону. Потом мы в новой части массива выбираем число по середине, и так далее, пока не найдём нужное значение.
Но это не так просто. Мы работаем с двумерным массивом, чтобы найти эту половину от половины, нужно выполнить некоторые операции, а это время и ресурсы. Мы же пытаемся этот процесс оптимизировать, а не сделать ещё более затратным. Нужно немного изменить этот процесс.
Сначала будем работать со строками. Мы выбираем строку по середине и смотрим на её первое значение. Это первое значение мы сравниваем с нашим искомым значением. Если искомое значение меньше, мы переходим на предыдущие строки, если больше, переходим на следующие строки. Мы берём строку, которая является половиной от половины, и смотрим также её первый элемент и сравниваем, после чего двигаемся в нужную сторону.
После нахождения исходной строки, просто её перебираем
Но мне кажется, что делить и искать строки по процентам тоже будет немного затратно, особенно, если нам будут попадаться только маленькие матрицы. Такой способ будет эффективнее использовать в больших матрицах. Почему бы для начала не попробовать написать что-то более простое, сделать код, который не ищет проценты, а от средней строки переходит вверх или вниз всего лишь на одну строчку в нужном направлении.
Пробуем
Создаём переменные, куда заранее записываем ширину и высоту матрицы, чтобы избежать повторных лишних вычислений в дальнейшем. Это мы и так уже сделали.
Создаём переменную run (отвечает за продолжение цикла), indexy (отвечает за выбранную строку), number (здесь будет храниться полученное число), row_check (можно ли от перебора строк переходить к их проверке) и direction (отслеживает направление нашей проверки, вверх или вниз, если поменялось направление, значит мы прошли строку с нашей целью).
Делаем цикл и создаём условия. Если наша row_check == false, то есть если мы находимся на этапе перебора строк, мы в переменную number записываем первое число выбранной строки.
Для оптимизации стоит это число записать в переменную и использовать в других местах кода, это эффективнее, чем каждый раз его получать через matrix[indexy][0].
Делаем условия, если число больше, меньше или равно цели. Если оно равно цели, можно сразу писать return true и останавливать цикл.
Смотрим дальше, что у нас есть...
Если наше число меньше искомого, переходим на строку вниз.
Дальше оно может оказаться по-прежнему меньше, и для проверки переходим опять на строку вниз
После этого мы сравниваем и понимаем, что 13 больше 10, и понимаем, что ответ был на предыдущей строке, туда и возвращаемся
Делаем в виде кода
Переменная direction будет иметь два направления (1 - вверх, 2 - вниз). Мы должны сделать проверку, если indexy находится на последней строчке, а число также больше, то делаем "row_check = true" и переходим к перебору самой строки.
Если же нет, перебираем строки. Если до этого мы двигались вверх, но теперь искомое число не меньше, а больше, получается, мы на правильной строке, нужно поменять направление и двигаться вперёд, но теперь нужно включить проверку строки.
Если же нет, то просто продолжаем двигаться вниз, задаём "direction = 2"
Условие "if (direction == 1)" относится к этой картинке (Если что, код для подъёма вверх мы пока не написали. Это код, если по условию нам надо двигаться вперёд, но до этого двигались назад).
В данном случае, нужно идти дальше по строке.
А его "else" относится к этой
Теперь работаем над условием, если число больше искомого, то есть надо двигаться вверх
Делаем проверку, если indexy > 0, то выполняются дальнейшие действия, если нет, но искомое по прежнему меньше, значит его просто не существует здесь, и выводим false.
Работаем над условиями дальше. Если направление 2, то есть мы до того, как наше искомое число стало меньше, двигались вниз, то это означает, что при проверке мы его пропустили. Возвращаемся вниз и включаем проверку строки.
Если же такого нет, то просто двигаемся вверх, вычитаем из indexY 1 и задаём direction 1
Условия для перебора строк мы прописали, теперь переходим к условиям для проверки самой строки
Если же мы на нужной строке, не придумываем ничего сложного, просто по обычному механизму перебираем
Запускаем код и смотрим. Небольшая оптимизация
Запускаем и смотрим, что же у нас получается...
Ой... Неужели я превзошёл 100% людей, которые решали эту задачу?? Ничего себе!! Вот такого я вообще не ожидал...
Тут возможно какая-то ошибка. Код выполнился слишком быстро, очень близко к 0 ms, возможно сайт не может сравнивать слишком малые значения, и поэтому показывает, что по скорости я превзошёл 100% программистов.
Но всё равно, это очень хорошие результаты
По затрачиваемой памяти здесь уже не всё так сказочно, но тоже хорошие результаты. Так, у меня появилась идея...
Мы всё равно переменную run не используем, а завершаем цикл через return. Почему бы её просто не удалить и не сделать бесконечный цикл.
Теперь память программы занимает 52 мб, что превосходит 98% программистов. Это странный сайт, каждый запуск выдаёт разные цифры, давайте попробуем ещё раз запустить его
Прикол...
А ещё раз
Ещё одно решение для оптимизации. Мы можем перенести переменную w из самого начала в место, где мы проходимся по самой строке. В некоторых случаях до перебора строки мы можем и не дойти, поэтому смысл объявлять эту переменную имеет смысл только здесь.
Да и в этом месте можно сократить и вынести одинаковый код за условия
Получается у нас всё равно вот так
Ну ладно, мы написали очень хороший код. Наш код выполняется за 0-1 миллисекунду (на сервере LeetCode) и занимает 52.2-54.4 МБ приблизительно, в зависимости от запуска. Очень хорошо.
Я попробовал не создавать слишком сложные алгоритмы, вот такого упрощённого алгоритма было достаточно.
Вот код
Надеюсь, вам понравилось. Если есть какие-то замечания и дополнения, пишите в комментариях. Подписывайтесь на канал и ставьте лайки 😄👍