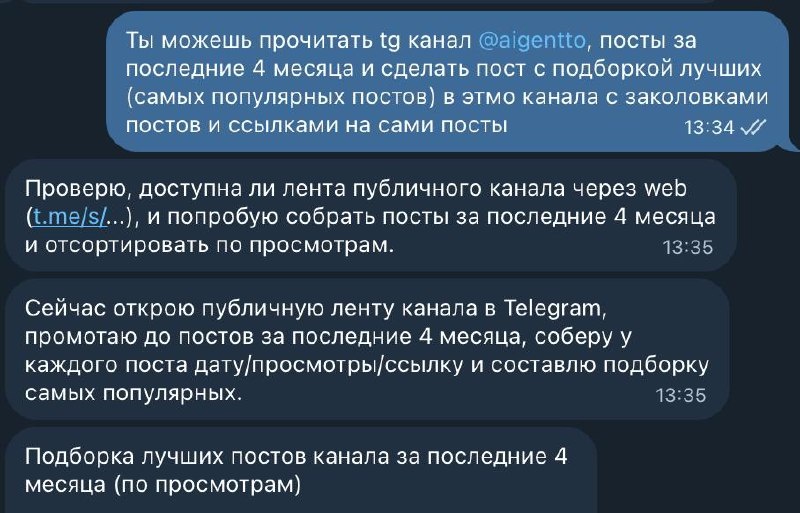
Сбор любой публичной статистики с DarwinClaw (ex OpenClaw)
Раньше я делал пост выше сам руками, теперь просто прошу DarwinClaw.
Раньше это занимало ~20 минут моего времени, сейчас - 4 минуты времени бота.
Под капотом бот не смог получить страницу через curl, затем получил ее через headless browser. Потом написал код на python с использованием beautiful soup для парсинга страницы.
Прочитать и распарсить любой сайт через обычную нейронку нельзя. Там простой curl запрос без браузера, и, например, Telegram таким запросам отказывает. А здесь реальный браузер запускается. Он жрет ресурсы памяти и CPU больше, чем curl, потому что страница реально рендерится со всеми js скриптами, НО зато делает все, как человек.
По токенам все это обошлось примерно в ~0.15 центов. Такие кейсы точно стоят этих 15 центов.
#КЕЙС
Подпишись 👉🏻 @Aigentto 🤖