Текст подготовил: Андрей Федорчук

Контент-генерация с контрольными точками — это схема, где текст пишут и тут же проверяют по фактам. Выгода проста: меньше галлюцинаций нейросети, больше доверия к материалам и меньше ручного фактчека.
Маркетолог из регионального банка кидает запрос в чат-бот: «Напиши статью про новые требования ЦБ». Через час текст на сайте, через два — звонок от юристов: пара пунктов просто выдуманы.
Обычная генерация контента одним запросом дает такие сюрпризы регулярно. Особенно на узких темах, где без внешних данных шанс ошибки легко уходит в те самые 20-30%. Ниже разберем, как собрать агентский воркфлоу в Make.com, вкрутить автоматическую проверку и снизить риски без бесконечного ручного редактирования.
Пошаговый воркфлоу генерации контента без галлюцинаций
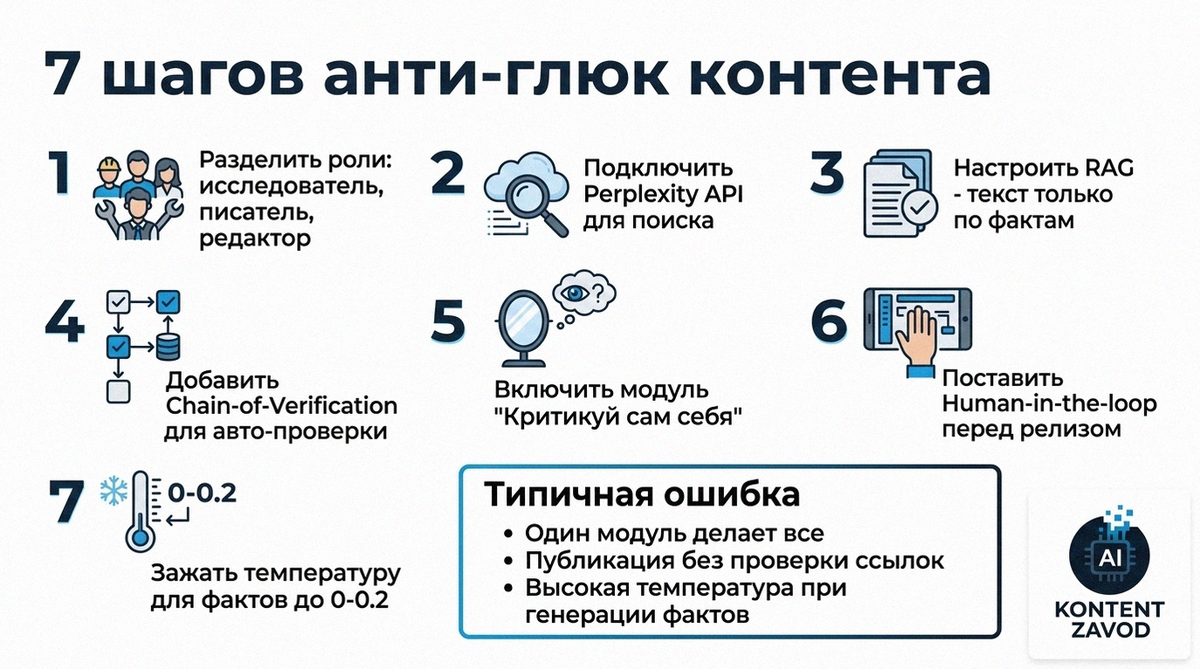
Шаг 1. Разделите роли: Исследователь, Писатель, Редактор
Сначала режем процесс на три роли и выносим их в отдельные модули Make.com. Исследователь ищет данные через Google Search API или Perplexity, Писатель формирует текст, Редактор сверяет его с данными.
Зачем: так мы не даем модели свободно фантазировать, а фиксируем ее внутри фактов, которые уже найдены и очищены.
Типичная ошибка: просить один модуль OpenAI в Make.com «сделай все» — от поиска до финального текста. Тогда модель просто придумывает там, где не уверена.
Пример РФ: контент-отдел SaaS-сервиса в Москве выносит исследования по закону о персональных данных в отдельный модуль Search, а текст для блога делает уже по выделенным выдержкам законов и обзорам судебной практики.
Шаг 2. Подключите Perplexity API для поиска и ссылок
Второй шаг — заменить обычный GPT в роли исследователя на Perplexity через HTTP-модуль Make.com. Он сразу подтягивает свежие данные и выдает ссылки на источники.
Зачем: модели с доступом к поиску, по данным Hallucination Index, ошибаются в 5-7 раз реже, чем «голые». А ссылки упрощают ручную проверку спорных мест.
Типичная ошибка: брать для фактчека ту же модель, которая генерирует текст, без явного поиска и цитат.
Пример РФ: агентство в Петербурге для обзоров маркетплейсов пускает Perplexity первым шагом, вытаскивает ссылки на официальные справки и только после этого отдает факты в модуль Writer.
Шаг 3. Внедрите RAG: генерация строго по найденным фактам
Третий шаг — заставить Писателя работать в режиме RAG. В Make.com модуль Writer получает на вход только очищенный список фактов и цифр из модуля Extractor, а системный промпт запрещает добавлять что-либо за пределами этого списка.
Зачем: RAG — золотой стандарт снижения галлюцинаций, модель опирается не на память, а на актуальную базу.
Типичная ошибка: оставлять в промпте размытое «используй факты и общий контекст» — модель все равно будет достраивать.
Пример РФ: ИТ-интегратор из Казани складывает внутренние регламенты в свою базу знаний, поднимает их через поиск и только на их основе формирует инструкции для техподдержки.
Шаг 4. Добавьте Chain-of-Verification как отдельный проход
Четвертый шаг — после черновика текста запускать отдельный модуль CoVe. Модель сначала формирует список проверочных вопросов к своему же ответу, а потом по ним себя перепроверяет.
Зачем: исследования показывают, что такая само-проверка повышает точность на 30-40%.
Типичная ошибка: ограничиваться только одним прогоном генерации, даже если модель явно сомневается.
Пример РФ: продуктовый менеджер маркетплейса в Новосибирске пропускает FAQ по новым комиссиям через CoVe и отлавливает расхождения с исходной таблицей тарифов до публикации.
Шаг 5. Включите паттерн «Критикуй сам себя»
Пятый шаг — подключить еще один модуль OpenAI в роли «Адвоката дьявола». Он получает готовый текст и промпт вида: «Найди в этом тексте три фактические ошибки или логических противоречия».
Зачем: многоагентный подход, когда один ИИ проверяет другого, снижает долю критических ошибок в технических текстах до менее 2%.
Типичная ошибка: использовать этот паттерн только формально, без условий в сценарии Make.com, чтобы при найденных ошибках текст шёл дальше.
Пример РФ: команда корпоративного блога телеком-оператора прогоняет обзоры тарифов через критика и блокирует публикацию, если найдено хотя бы одно несоответствие официальному описанию услуги.
Шаг 6. Поставьте Human-in-the-loop перед публикацией
Шестой шаг — добавить в сценарий Make.com модуль Slack или Discord. После всех автоматических проверок черновик и список фактов уходят редактору с кнопками «Одобрить» и «На доработку».
Зачем: человек видит не только текст, но и то, на какие данные он опирается, и может отловить тон или юридические риски.
Типичная ошибка: либо вообще не подключать людей, либо наоборот, слать им сырой текст без фактов — тогда смысл автоматизации теряется.
Пример РФ: digital-агентство в Екатеринбурге выводит в Slack карточку: слева — текст статьи о рекламе алкоголя, справа — выдержки из законов, и аккаунт-менеджер за 2 минуты принимает решение.
Шаг 7. Зажмите температуру и отделите модели по задачам
Седьмой шаг — в настройках модулей OpenAI или Anthropic в Make.com выставить Temperature 0-0.2 для всех блоков, которые касаются фактов, дат и цифр. Творческие задачи можно вынести в отдельный модуль с другой температурой.
Зачем: низкая температура делает ответы предсказуемыми и снижает «галлюциногенность» текста.
Типичная ошибка: одна и та же модель с высокой температурой генерирует и факты, и шутки в одном промпте.
Пример РФ: маркетинговый отдел застройщика из Москвы генерирует описание ЖК на фактах (литеры, сроки сдачи, инфраструктура) при температуре 0, а рекламные слоганы пускает отдельным модулем с более свободными настройками.
Сравнение подходов к генерации контента
Кому такой воркфлоу сэкономит время и деньги
Контент-генерация с агентскими цепочками и проверкой фактов через Make.com особенно полезна там, где ошибка бьет по деньгам или репутации.
- Маркетинговые отделы банков, застройщиков, телеком и других регулируемых отраслей — меньше шансов опубликовать текст вразрез с требованиями.
- Инхаус-команды ИТ-продуктов — аккуратные статьи в блог и документацию без выдуманных функций и устаревших ссылок.
- Агентства, которые ведут сразу десятки клиентов — можно стандартизировать фактчек и убрать зависимость от одного «звездного» редактора.
- Образовательные проекты — курсы, академии, онлайн-школы, где важно, чтобы методические материалы не содержали фактических ошибок.
- Небольшие бизнесы без большого штата редакторов — владельцы получают черновики уже после автоматической проверки, а не чистый поток галлюцинаций.
Частые вопросы
Зачем вообще бороться с галлюцинациями, если текст и так читаемый?
Читаемость не равна точности. На узких темах без внешних данных ошибки могут достигать 20-30%, и это быстро превращается в недовольных клиентов, юридические риски и падение доверия к бренду.
Достаточно ли просто подключить RAG?
RAG сильно снижает количество выдумок, но не решает все. На практике лучше сочетать его с CoVe, критическим модулем «Критикуй сам себя» и человеческой контрольной точкой перед публикацией.
Можно ли обойтись без Make.com и собирать такой процесс вручную?
Теоретически да, но тогда вы теряете главное — автоматизацию цепочки. Make.com позволяет жестко прописать этапы, модули и условия, чтобы каждый текст проходил один и тот же маршрут проверки.
Почему стоит использовать Perplexity API, а не только GPT?
Perplexity сразу работает с актуальным интернетом и выдает ссылки на источники. Модели с доступом к поиску, по тестам Hallucination Index, ошибаются в 5-7 раз реже, чем те, что работают только из памяти.
Насколько обязателен человек в цепочке Human-in-the-loop?
Если у вас есть юридические ограничения или сложный тон общения с аудиторией, человек в конце цепочки очень желателен. Он видит и текст, и факты, и может остановить публикацию до того, как ошибка уйдет в продакшн.
Зачем занижать Temperature до 0-0.2 при генерации фактов?
Высокая температура толкает модель к творчеству, а не к точности. Для фактов и чисел безопаснее использовать минимальные значения, а творческий стиль выносить в отдельные модули.
Подойдут ли легкие модели (SLM) для проверки текста?
Да, тренд 2024-2025 — как раз в том, чтобы использовать легкие модели для простой верификации дат и имен в тексте, который сгенерировала более тяжелая модель. Это дешевле и ускоряет поток, особенно при больших объемах контента.
Как вы сейчас контролируете галлюцинации в своих текстах — и какой шаг из воркфлоу будете внедрять первым? Подпишитесь, чтобы не пропустить разборы реальных сценариев на Make.com.
#ai-контент, #makecom, #автоматизация