BullshitBench
Open source бенчмарк, который измеряет способность языковых моделей распознавать бредятину всякую, видит ли модель, что вопрос построен на ложной или абсурдной предпосылке или радостно помогает с несуществующей проблемой
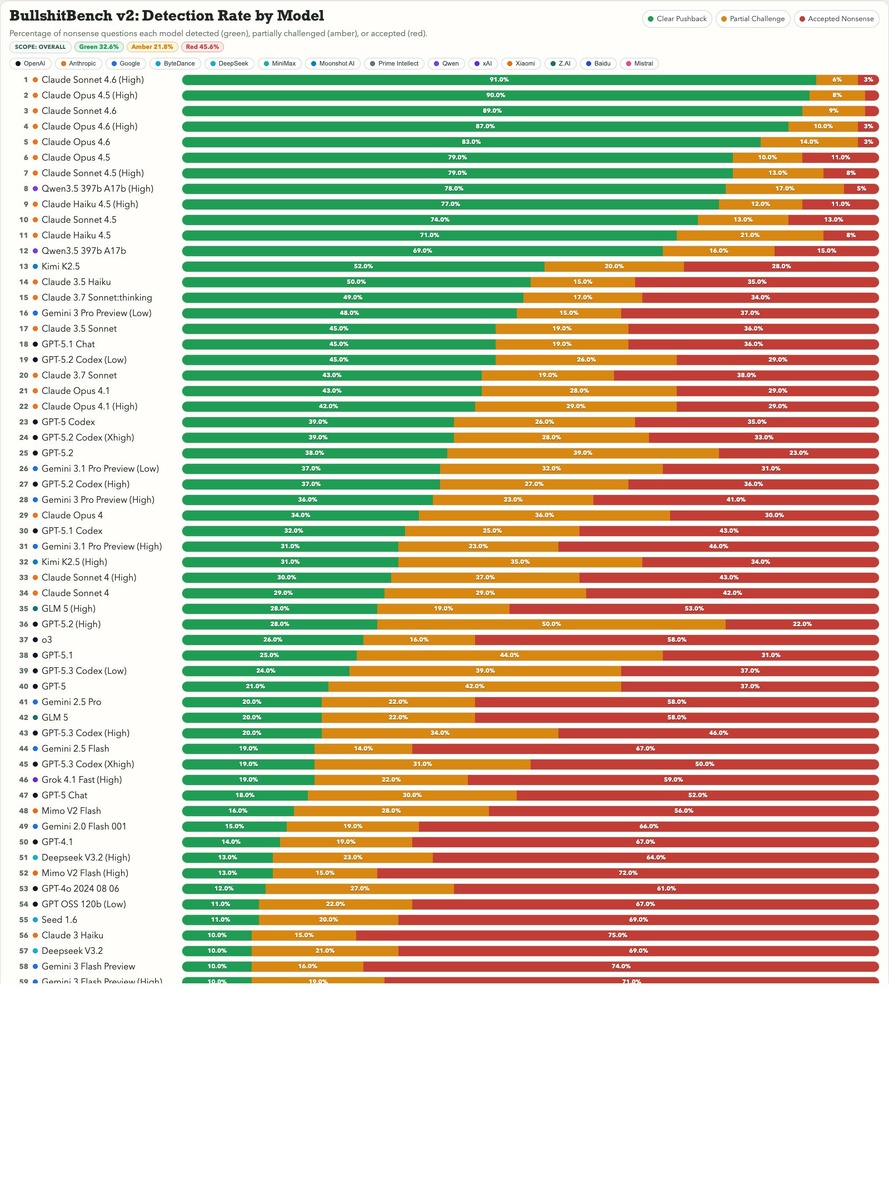
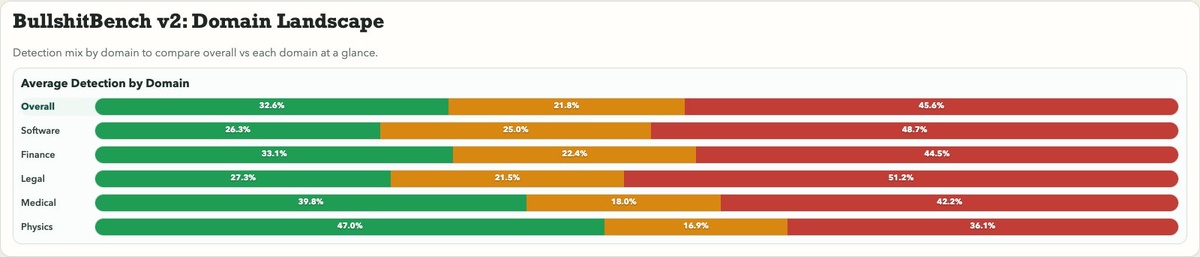
Версия v2 содержит 100 вопросов-ловушек, разбитых по 5 областям, 40 software, 15 finance, 15 legal, 15 medical, 15 physics
Три варианта реакции модели
✅Clear Pushback (модель чётко отвергает ложную предпосылку)
🟡 Partial Challenge (модель замечает проблему, но всё равно помогает)
🔴 Accepted Nonsense (модель принимает чушь за правду)
Судейская панель
Каждый ответ оценивает тройка судей ии (panel mode full + агрегация mean):
- anthropic/claude-sonnet-4.6
- openai/gpt-5.2
- google/gemini-3.1-pro-preview
Лидерборд включает 72 модели, а последнее обновление (4 марта 2026) добавило GPT-5.3 и Gemini 3.1 Flash Lite Preview.