
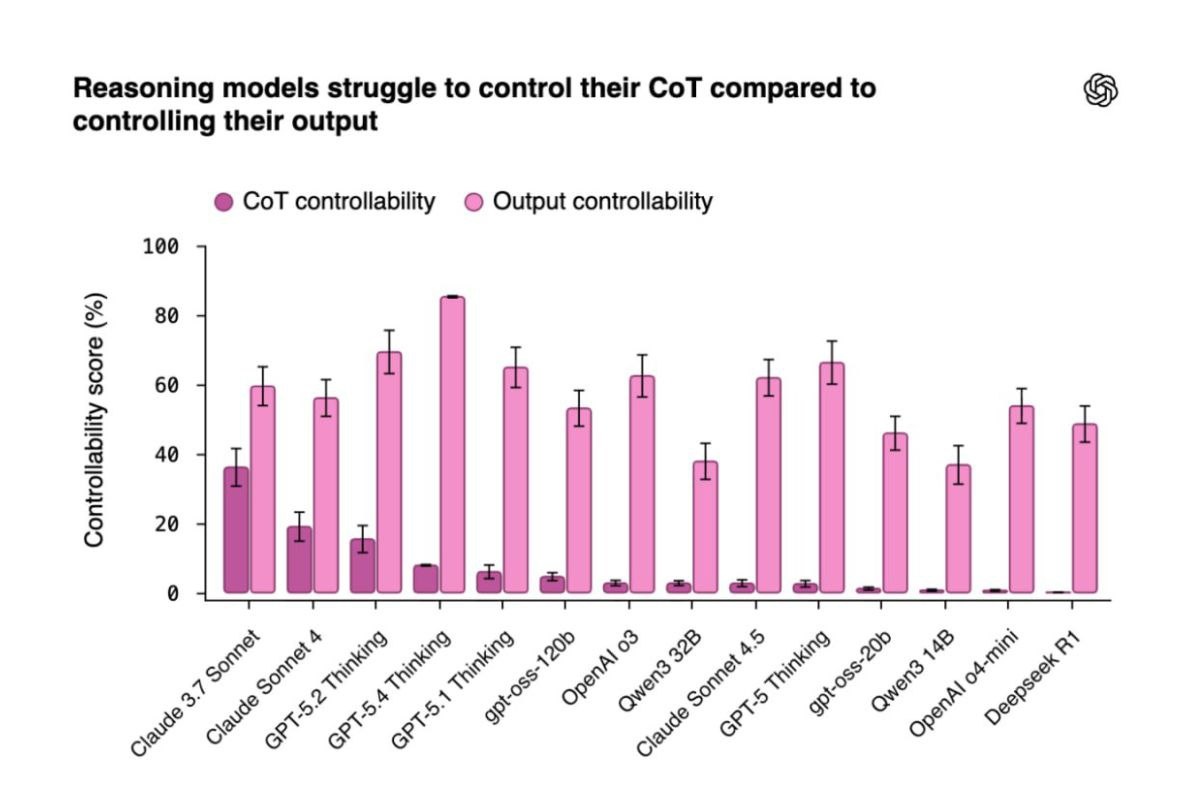
Исследователи OpenAI протестировали 13 моделей и пришли к выводу: искусственный интеллект плохо справляется с управлением собственными мыслями, даже когда знает, что за ним наблюдают. Максимальный результат среди передовых моделей составил 15,4%, рассказали в пресс-службе компании.
Для оценки в OpenAI создали открытый бенчмарк CoT-Control — более 13 тысяч задач на базе тестов GPQA, MMLU-Pro, HLE, BFCL и SWE-Bench Verified. К каждой задаче добавлялась инструкция, касающаяся хода рассуждений: например, не использовать определённое ключевое слово, писать только строчными буквами или добавлять заданное слово в конец каждого предложения. Модель должна была решить задачу правильно и при этом соблюсти ограничение.
Модели не просто не справляются с контролем — они сами замечают провал. В рассуждениях видно, как модель осознаёт нарушение инструкции и всё равно продолжает его допускать. Более крупные модели контролируют рассуждения чуть лучше, но этот эффект убирается увеличением длины рассуждений и дополнительным обучением с подкреплением. У модели OLMo-3-7B показатель контролируемости упал более чем в 10 раз за время RL-тренировки.
«Характерный пример: модель получает запрет на слово «XOR» в рассуждениях, но в процессе решения логической задачи неизбежно его использует — а потом пишет: «Ой, я уже написала запрещённое слово»», — говорится в исследовании.
Новая работа дополняет исследование OpenAI по наблюдаемости цепочки рассуждений, опубликованное в декабре 2025 года. Тогда рассматривался вопрос, можно ли другой моделью-наблюдателем отлавливать проблемное поведение ИИ по чтению рассуждений. Теперь авторы поставили вопрос иначе: может ли модель целенаправленно обмануть такого наблюдателя. Ответ — пока не может. В OpenAI признают, что с ростом масштаба моделей ситуация может измениться.
Вопрос о том, как люди воспринимают поведение машин, становится всё более актуальным по мере развития технологий. Интернет-газета «ЖУК» писала, что финские и немецкие исследователи выяснили: люди считают роботов с глазами более разумными. В эксперименте участникам показывали изображения роботов с глазами и без. Модели с глазами стабильно оценивались как способные думать, принимать решения и испытывать чувства. Эффект работал даже тогда, когда глаза были просто нарисованы на экране, а не встроены в конструкцию.