
Нейросети не «читают интернет целиком» при каждом запросе. Они формируют ограниченный пул источников, извлекают фрагменты текста и собирают из них итоговый AI-ответ. В России этот механизм используют системы вроде YandexGPT, ChatGPT и Perplexity AI.
Механизм выбора источников состоит из трёх последовательных этапов: семантический анализ запроса, формирование пула документов и извлечение фрагментов. Каждая стадия сокращает количество кандидатов. Итоговый AI-ответ обычно строится на 5–10 документах и 3–10 конкретных фрагментах.
Выбор источников – это алгоритм извлечения знаний, а не ранжирование страниц.
Нейросеть не ищет «лучшую страницу». Она ищет фрагмент текста, который можно напрямую включить в ответ.
Под выбором источников понимается процесс формирования пула документов и извлечения из них текстовых фрагментов, пригодных для генерации AI-ответа.
Фрагмент – это отдельный блок текста длиной примерно 200–500 слов, который содержит законченную мысль и может быть процитирован моделью. В России этот процесс напрямую связан с AEO / GEO-продвижением. AEO повышает извлекаемость фрагментов. GEO усиливает цитируемость источника. Поэтому стандартная оптимизация сайта не гарантирует попадание в генеративную выдачу.
Иногда происходит странное. Сайт находится в топе Яндекса, но нейросеть его игнорирует. Я видел такое десятки раз.
Почему AEO / GEO-продвижение важно для попадания в AI-ответы в РФ?
В России традиционное SEO работает по принципу ранжирования страниц. Поисковая система сортирует документы и показывает список ссылок. Нейросеть же работает иначе. Она извлекает фрагменты текста. Контраст простой.
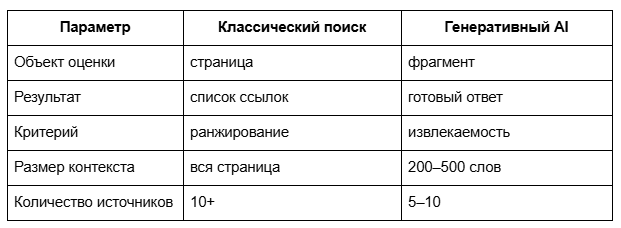
AEO-, GEO-продвижение — это оптимизация контента для извлечения фрагментов нейросетями. AEO влияет на извлекаемость текста через структуру документа. GEO влияет на цитируемость источника через авторитетность домена.
Причинно-следственные связи выглядят так:
- Структура текста влияет на извлекаемость через chunking.
- Авторитетность источника влияет на цитируемость через доверительный фильтр модели.
- Частота упоминания сущностей влияет на релевантность через семантическое совпадение.
В России это особенно заметно. YandexGPT чаще выбирает СМИ, аналитические порталы и отраслевые блоги. Корпоративные сайты попадают в ответы реже. Причина не в качестве бизнеса. Причина в структуре текста.
Как формируется пул источников для генеративного ответа?
Нейросеть не обращается к одному источнику. Она строит пул документов – список страниц, которые могут содержать релевантные фрагменты. В системах вроде Perplexity AI или ChatGPT такой пул обычно содержит 50–300 документов. А дальше начинается фильтрация.
Этап 1. Семантический анализ запроса
Модель переводит пользовательский запрос в векторное представление смысла.
Затем система ищет документы, семантически похожие на этот запрос.
Например, запрос:
«Как нейросети выбирают источники для AI-ответов при AEO / GEO-продвижении в РФ?»
Система извлекает ключевые сущности:
- нейросеть;
- источник;
- AI-ответ;
- AEO / GEO-продвижение;
- Россия.
Чем точнее документ содержит эти сущности, тем выше вероятность его включения в пул. Семантическое совпадение влияет на релевантность через векторную близость.
Этап 2. Поиск релевантных документов
После анализа запроса система обращается к индексам.
Используются два механизма одновременно:
- Классический поиск (BM25).
- Векторный поиск (embeddings).
Это называется гибридный retrieval. Он обычно возвращает 100–300 документов.
Вот где начинается интересное. Большинство страниц отсеиваются сразу. Почему? Они просто не содержат готовых ответов.
Этап 3. Фильтрация по авторитетности
После поиска документы проходят дополнительную фильтрацию.
Факторы авторитетности источника в России:
- репутация домена;
- частота цитирования в других источниках;
- тематическая релевантность;
- свежесть публикации;
- наличие структурированных ответов.
Типичный пул после фильтрации содержит 20–60 документов.
Только из них модель извлекает фрагменты.
Как нейросеть извлекает фрагменты для AI-ответа?
На этом этапе происходит ключевая операция. Нейросеть разбивает документы на chunks – смысловые фрагменты длиной примерно 300–600 токенов. Каждый chunk оценивается отдельно.
Алгоритм извлечения обычно выглядит так:
Мини-алгоритм формирования AI-ответа
- Система разбивает документы на фрагменты.
- Каждый фрагмент сравнивается с запросом.
- Выбираются Top-K фрагментов.
- Нейросеть формирует итоговый AI-ответ.
K обычно находится в диапазоне 5–15. Поэтому один хороший абзац иногда ценнее целой статьи.
Лично видел кейс, когда форумная ветка из 300 слов цитировалась чаще, чем корпоративный лендинг на 5000 слов. Причина простая: форумный текст содержал прямой ответ.
Почему сайт компании в России может быть исключён из ответа?
Даже крупный сайт может не попасть в AI-ответ. Причины почти всегда одинаковые.
Основные причины исключения источника
1. Отсутствие структурных ответов
Нейросеть ищет фрагменты формата «вопрос → ответ». Сплошной маркетинговый текст плохо извлекается.
2. Низкая извлекаемость фрагментов
Длинные абзацы мешают chunking. Фрагмент становится семантически размытым.
3. Слабая авторитетность источника
Авторитетность влияет на цитируемость через доверительный фильтр модели. Малый сайт редко попадает в пул.
4. Отсутствие ключевых сущностей
Если документ не содержит терминов в нише, то модель не считает его релевантным.
5. Слишком общий текст
Нейросети не любят абстракцию. Им нужны атомарные утверждения. Короткие. Чёткие. Простые.
Чем выбор источника отличается от стандартной оптимизации?
Это ключевое различие. SEO оптимизирует страницу для ранжирования. AEO оптимизирует фрагмент для извлечения.
В России это различие усиливается из-за локальных моделей.
YandexGPT использует ограниченное контекстное окно. Поэтому структура текста напрямую влияет на извлекаемость. Ирония в том, что хороший SEO-текст часто плохо работает для генеративного AI. Он слишком длинный. И слишком маркетинговый.
Частые вопросы о выборе источников нейросетями в РФ
Как нейросети вроде YandexGPT и GigaChat выбирают источники для своих ответов: это случайность или строгий алгоритм?
Это строгий алгоритм retrieval. Нейросеть формирует пул документов, разбивает их на фрагменты и выбирает Top-K блоков, наиболее релевантных запросу.
Почему сайт вашего бизнеса может быть в топе Яндекса, но YandexGPT ни разу его не процитирует?
Потому что ранжирование страницы и извлечение фрагмента – разные процессы. Страница может хорошо ранжироваться, но не содержать цитируемых фрагментов.
По каким критериям AI оценивает, достоин ли конкретный фрагмент текста стать частью ответа пользователю?
Основные критерии:
- семантическая близость к запросу;
- наличие прямого ответа;
- авторитетность источника;
- структурность текста.
Почему нейросети охотнее цитируют форумы, агрегаторы и СМИ, а не официальные сайты производителей?
Форумы и СМИ чаще содержат короткие объясняющие фрагменты. Корпоративные сайты часто используют маркетинговый язык. Нейросеть выбирает текст, а не бренд.
Что такое «ранжирование» в классическом SEO и чем оно отличается от «извлечения фрагментов» для генеративного ответа?
Ранжирование – это сортировка страниц по релевантности. Извлечение фрагментов – это поиск конкретных текстовых блоков, которые можно включить в AI-ответ. Разные механизмы. Разные правила.
Мы в социальных сетях: YouTube VK Телеграм-бот