В прошлой статье мы разобрали подкапотное устройство Трансформеров и поняли, что большие языковые модели (LLM) — это мощные, но все же статистические машины. У них есть один фундаментальный изъян: они знают только то, на чем их обучили в прошлом. Если вы спросите ChatGPT о квартальном отчете вашей компании за прошлый месяц или о нюансах вашего личного договора аренды, модель либо скажет, что не знает, либо (что гораздо хуже) начнет уверенно галлюцинировать и выдумывать факты.
Как же заставить ИИ работать с вашей персональной базой знаний? Для этого инженеры придумали связку из двух понятий: Контекстного окна и архитектуры RAG.
Чтобы понять решение, нужно сначала разобраться, как именно ИИ взаимодействует с вами прямо сейчас.
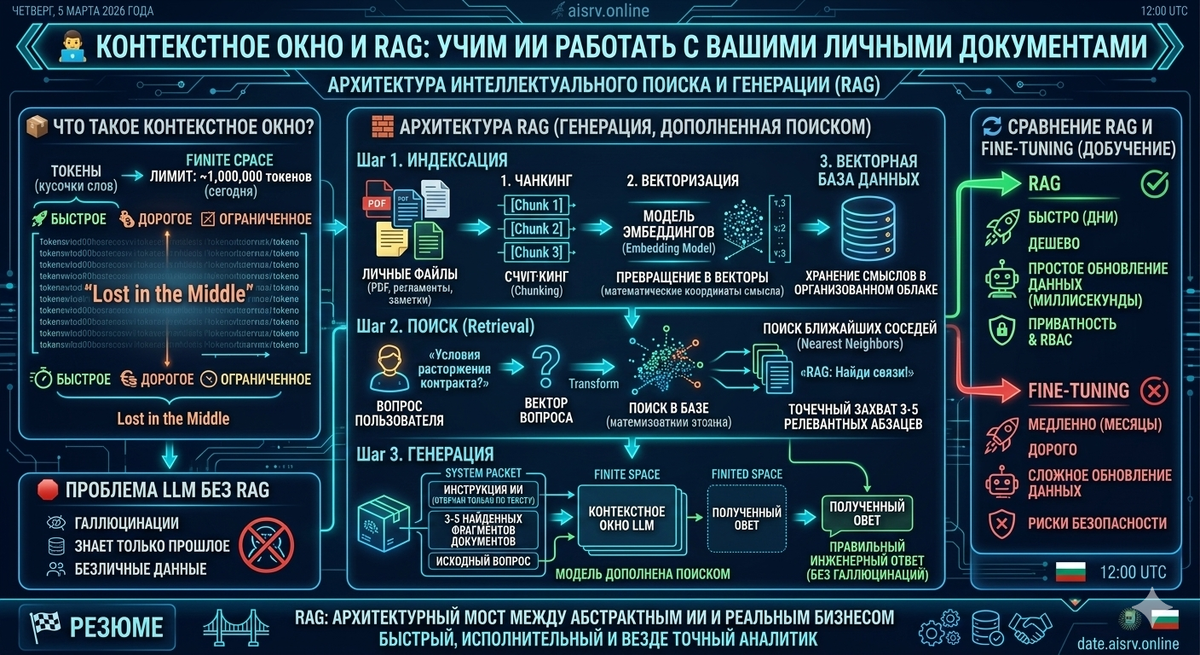
🧠 1. Контекстное окно: Краткосрочная память нейросети
Все, что вы пишете в чат-боту, и все, что бот вам отвечает, помещается в так называемое контекстное окно. Это оперативная память языковой модели на время вашей текущей сессии.
- 📏 Оно измеряется в токенах (кусочках слов). У каждой модели есть жесткий аппаратный лимит. Пару лет назад это было 4 000 токенов (около 10 страниц текста). Сегодня существуют модели с окном в 1 000 000 токенов (можно загрузить целую книгу).
- 💸 Возникает логичный вопрос: почему бы просто не загружать в это гигантское окно все ваши корпоративные документы каждый раз, когда вы задаете вопрос? Во-первых, это невероятно дорого — облачные провайдеры берут плату за каждый обработанный токен. Во-вторых, скорость ответа упадет до минут.
- 📉 И в-третьих, существует архитектурная проблема «Lost in the Middle» (Потерянное в середине). Когда вы «скармливаете» нейросети гигантский объем текста за один раз, она отлично помнит начало документа и его конец, но катастрофически теряет и игнорирует критически важные данные из середины.
🏗️ 2. Встречайте RAG: Архитектура умного поиска
Чтобы не перегружать контекстное окно и заставить ИИ работать с вашими файлами без галлюцинаций, был создан паттерн Retrieval-Augmented Generation (Генерация, дополненная поиском). Или просто RAG.
Вместо того чтобы заставлять модель читать всю вашу базу данных каждый раз, мы даем ей инструмент для точечного поиска нужной информации. Процесс элегантно делится на три инженерных этапа.
✂️ Шаг 1. Индексация (Превращаем текст в математику)
Сначала мы должны подготовить ваши файлы (PDF-документы, регламенты, заметки) для машины.
- 🔪 Чанкинг (Chunking): Система разрезает ваши гигантские документы на небольшие логические абзацы (чанки).
- 🔢 Векторизация: Каждый чанк пропускается через специальную нейросеть (Embedding model), которая превращает этот кусочек текста в длинный список чисел — математические координаты смысла.
- 🗄️ Векторная база данных: Эти координаты сохраняются в специализированную базу. Теперь ваши документы — это не просто текст на диске, это облако смыслов в многомерном пространстве.
🔍 Шаг 2. Поиск (Retrieval)
Вы приходите к вашему настроенному боту и спрашиваете: «Какие условия расторжения контракта с компанией X?».
- 🎯 Система берет ваш вопрос и точно так же превращает его в вектор-координату.
- 🧭 Затем она обращается к векторной базе данных и ищет там те самые «чанки» (абзацы), чьи математические координаты физически находятся ближе всего к координатам вашего вопроса.
- 📎 Система мгновенно вытаскивает 3-5 самых релевантных кусков текста из ваших тысяч документов.
🤖 Шаг 3. Генерация (Augmented Generation)
Вот здесь происходит магия синтеза, ради которой все затевалось.
- 📦 Система формирует невидимый для вас системный пакет. В него кладется строгая инструкция, те самые 3-5 найденных абзацев из ваших документов и ваш исходный вопрос.
- 🧠 Весь этот небольшой, аккуратный и сверхточный пакет данных отправляется в контекстное окно большой языковой модели (LLM).
- 🛡️ Нейросети дается приказ: «Ответь на вопрос пользователя, используя ТОЛЬКО предоставленные фрагменты текста. Если ответа там нет, скажи, что информации недостаточно».
В итоге модель читает исключительно ваши реальные факты и блестяще формулирует связный, человеческий ответ, не придумывая ничего лишнего.
⚖️ Почему RAG победил классическое дообучение (Fine-tuning)?
Многие заказчики часто спрашивают меня: «Зачем строить сложный поиск? Давайте просто дообучим (fine-tune) саму языковую модель на наших документах?».
- 🕒 Скорость и цена: Дообучение модели требует колоссальных вычислительных мощностей, специалистов и времени. Качественный RAG можно развернуть за пару дней на стандартных серверах.
- 🔄 Обновление данных: Если в вашем регламенте изменилась одна цифра или абзац, дообученную модель придется долго переучивать. В архитектуре RAG вы просто удаляете старый вектор из базы и кладете туда новый. Это занимает миллисекунды.
- 🔒 Приватность и безопасность: В RAG мы можем настроить систему так, чтобы этап поиска (Retrieval) работал только в тех документах, к которым у конкретного сотрудника есть права доступа (RBAC). Модель никогда не выдаст финансовые секреты руководства рядовому менеджеру, потому что этот текст просто не попадет в ее контекстное окно.
🏁 Резюме архитектора
Технология RAG — это, без преувеличения, самый важный архитектурный мост между абстрактным искусственным интеллектом и реальным бизнесом. Она решает главную проблему нейросетей — отрыв от реальности.
Благодаря RAG, языковая модель превращается из непредсказуемого фантазера в исполнительного и невероятно быстрого аналитика. Аналитика, который перед тем как открыть рот, всегда сверяется с вашими официальными бумагами. Именно по этому принципу сегодня работают самые продвинутые персональные базы знаний и корпоративные ИИ-ассистенты во всем мире.