Многие до сих пор считают, что ChatGPT «думает». На самом деле, перед нами — самая совершенная в истории человечества статистическая машина. Буква «Т» в аббревиатуре GPT означает Transformer. Эта архитектура была представлена в 2017 году в легендарной статье «Attention is All You Need». С тех пор мир изменился навсегда.
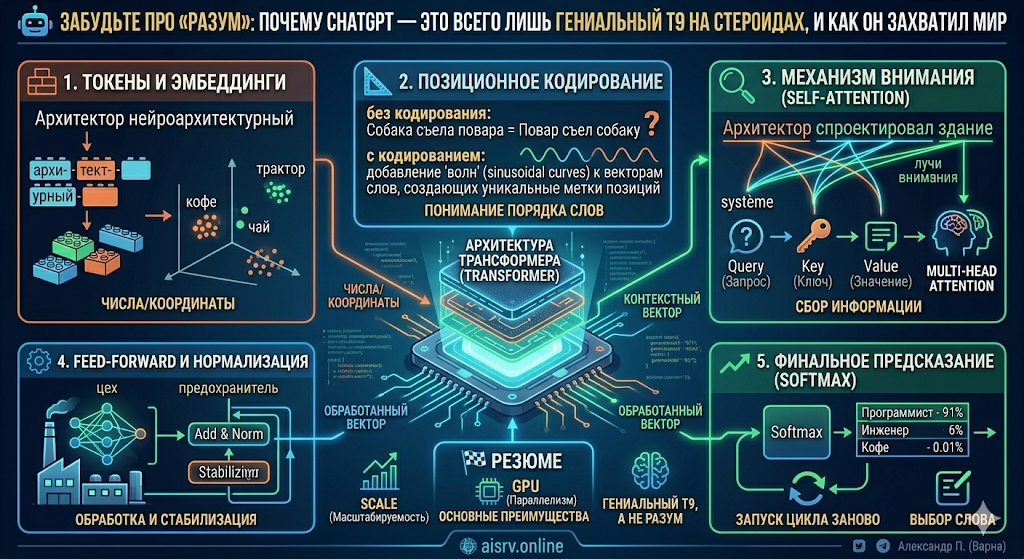
Давайте разберем этот механизм по слоям: от «входа» сырых данных до «выхода» гениальных ответов.
🧱 Модуль 1. Токенизация и Эмбеддинги: Алхимия перевода смыслов в числа
Нейросеть — это чистая математика. Она не видит букв, она видит тензоры (многомерные массивы чисел). Первый этап — превращение текста в данные, с которыми можно проводить вычисления.
🧩 Токенизация: Почему «кирпичики» лучше «слов»
Если бы мы учили модель по целым словам, словарь был бы бесконечным (склонения, спряжения, новые сленгизмы). Вместо этого используется алгоритм Byte Pair Encoding (BPE).
- Программа разбивает текст на токены. Токен — это не слово, а статистически повторяющийся фрагмент.
- Слово «трансформация» может быть разбито на транс-, форм- и -ация.
- Это позволяет модели понимать слова, которых она никогда не видела, просто анализируя их составные части. В 2026 году современные LLM оперируют словарями в 100 000 – 256 000 таких «кирпичиков».
📍 Эмбеддинги: Библиотека смыслов в 4096 измерениях
После того как мы получили ID токена (например, число 4512), нам нужно наделить его смыслом. Здесь вступают в дело эмбеддинги.
Каждый токен превращается в вектор — список из нескольких тысяч чисел (например, 4096 для моделей уровня Llama 3).
- Это координаты в гигантском гиперпространстве.
- В этом пространстве «Кошка» находится рядом с «Котенком» и «Мурлыканьем», но очень далеко от «Бетономешалки».
- Архитектурный инсайт: Самое поразительное, что модель сама вычисляет эти координаты во время обучения. Она находит математические закономерности между понятиями, которые мы, люди, называем «смыслом».
📐 Модуль 2. Positional Encoding: Как вдохнуть время в параллельную систему
Трансформеры — это рай для параллельных вычислений. Они «проглатывают» весь текст сразу. Но из-за этого они теряют понимание порядка слов. Без костылей нейросеть не отличит «Собака съела повара» от «Повар съел собаку».
Инженеры решили это элегантно: к каждому вектору слова добавляется Позиционное кодирование.
- Это специальная математическая «волна» (функции синуса и косинуса с разной частотой).
- На каждом месте в предложении эта волна имеет свое уникальное значение.
- Модель «накладывает» эту волну на вектор смысла, и вуаля — у каждого слова появляется «метка времени». Теперь оно знает, стоит оно в начале мысли или в конце.
🔍 Модуль 3. Self-Attention: Истинный интеллект через систему Query, Key и Value
Это «секретный соус», который сделал Трансформеры непобедимыми. Механизм Self-Attention (Само-внимание) позволяет модели понимать контекст.
Представьте, что вы ищете видео на YouTube.
- Query (Запрос): Вы вводите поисковый запрос (Слово спрашивает: «Что мне нужно для смысла?»).
- Key (Ключ): Названия всех видео на сервере (Все остальные слова в тексте говорят: «Вот мои характеристики»).
- Value (Значение): Само содержание видео (Слова передают свой смысл тому, кто их «запросил»).
🔦 Пример с контекстом: «Он взял ключ от замка»
Слово «ключ» отправляет запрос (Query) ко всем словам в предложении. Слово «замок» отвечает своим ключом (Key), который идеально подходит к запросу. В итоге слово «ключ» получает порцию «значения» (Value) именно от «замка», а не от «гаечного набора».
🎭 Multi-Head Attention: 32 взгляда на одну проблему
В современных моделях таких «голов» внимания десятки. Одна голова следит за подлежащими и сказуемыми, вторая — за временем, третья — за эмоциональным окрасом, четвертая — за техническими терминами. Это позволяет модели анализировать текст с 32-96 разных точек зрения одновременно.
⚙️ Модуль 4. Feed-Forward и Residual Connections: Магистрали данных
После того как механизм внимания собрал контекст, данные нужно обработать.
- Feed-Forward Networks (FFN): Это «цеха» переработки. Здесь каждый токен проходит через классическую нейросеть, которая окончательно решает, как контекст изменил его значение.
- Residual Connections (Остаточные связи): Это архитектурные «шоссе». Они позволяют исходным данным проходить сквозь слои, не теряясь. Если какой-то слой решит «галлюцинировать», исходная информация с предыдущего уровня всё равно дойдет до конца. Это решило проблему «затухания градиента» и позволило строить модели из сотен слоев.
📈 Модуль 5. Softmax и Генерация: Вероятностный финал
Пройдя через 80-100 таких блоков (внимание + обработка), данные выходят на финишную прямую.
- Модель получает финальный вектор смысла для последнего слова.
- Она сравнивает его со всеми 100 000 токенами в своем словаре.
- Функция Softmax превращает эти сравнения в проценты вероятности.
«Программист» — 92%
«Кофе» — 5%
«Динозавр» — 0.0001% - Модель выбирает слово с 92% вероятности, печатает его и... весь процесс начинается заново.
Важный момент: Каждый раз, когда модель печатает слово, она добавляет его в свой контекст. Она буквально «читает» сама себя, чтобы предсказать следующий шаг. Именно поэтому длинные ответы иногда «уплывают» в сторону — ошибка в одном слове копится как снежный ком.
🚀 Почему это захватило мир? (Вердикт архитектора)
Трансформер — это идеально масштабируемая архитектура.
- 🚄 Параллелизм: Мы можем тренировать эти модели на тысячах GPU одновременно, потому что слова не обрабатываются по цепочке.
- 📈 Scaling Laws: Инженеры заметили, что если просто давать Трансформеру больше данных и больше вычислительной мощности, он становится «умнее».
🏁 Резюме архитектора
Трансформер — это не «душа в машине». Это колоссальная библиотека человеческого опыта, сжатая в миллиарды коэффициентов (весов). Она не понимает истину, она понимает закономерность. И в 2026 году этой закономерности достаточно, чтобы автоматизировать 80% интеллектуального труда.
В следующей публикации мы разберем, как приземлить этих «гигантов» на ваши задачи с помощью технологии RAG, чтобы ИИ не фантазировал, а отвечал строго по вашим корпоративным базам данных.
🛒 Хотите увидеть архитектуру в действии? Попробуйте Claude Code, который использует эти принципы для написания кода в реальном времени: anthropic.com/claude-code