
Представь: ты три месяца пишешь дипломную. Сам. Сидишь по ночам, перечитываешь источники, переписываешь аргументы. Сдаёшь на проверку — и система говорит: 50% написано ИИ. Ты виновен.
Именно это случилось с Сяобин, студенткой немецкой литературы из Северо-Восточного Китая. Она написала 16-страничный диплом своими руками, использовала ChatGPT максимум для шлифовки пары абзацев — и в итоге первая же проверка отправила её работу в мусор. «Я чувствую себя невиновной, которую ведут на виселицу», — сказала она в интервью.
Это не исключение. Это норма.
Как Китай решил «проблему ИИ» — и что из этого вышло
В 2024–2025 годах десятки китайских университетов — Фучжоу, Сычуань, Цзянсу и другие — ввели лимиты на ИИ-контент в дипломных работах. Допустимый порог разнится: где-то 15%, где-то 40%. Но итог один: превысил — до свидания. Отчисление или задержка диплома.
Цель понятна. Академическая честность, всё дела.
Только вот одна деталь: детекторы, которые университеты используют для проверки, работают… мягко скажем, не очень. Студентка Яньцзы из Шаньдуна написала всё сама — CNKI (главная академическая база данных Китая) показала 30% ИИ. Она переписала работу строчка за строчкой. Снова не прошла. Потратила на это четыре дня — потом купила за 16 юаней (~200 рублей) ИИ-инструмент для «очистки текста» и сдала работу.
Ирония в том, что она не использовала ИИ с самого начала. Запрет ИИ заставил её использовать ИИ.
Главный абсурд: те, кто проверяют — те же, кто продают лазейку
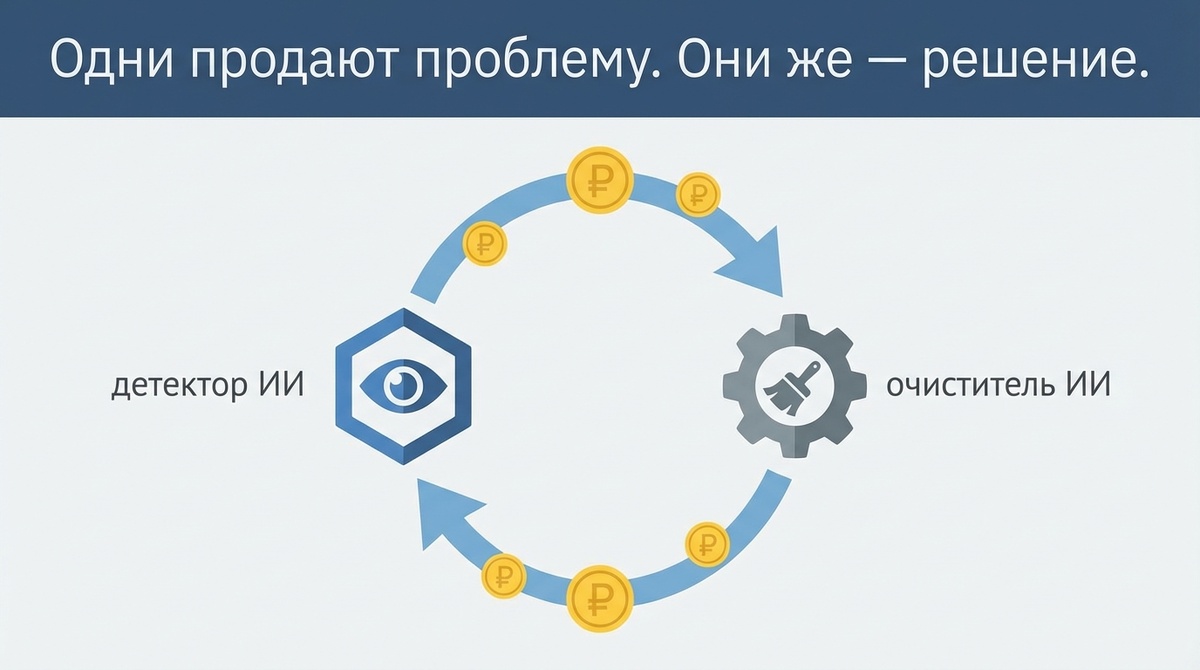
Вот где начинается что-то по-настоящему странное.
Китайские университеты в основном используют детекторы от трёх компаний: CNKI, Wanfang Data и Chongqing VIP. Это старые игроки рынка — они давно продают инструменты для проверки на плагиат. Теперь добавили ИИ-детекцию.
Но. Две из этих компаний — Chongqing VIP и PaperPass — параллельно предлагают услуги по снижению ИИ-рейтинга. То есть буквально: один отдел продаёт детектор вузу, второй продаёт студенту инструмент, чтобы этот детектор обмануть.
Profit loop в чистом виде. Проблема и решение — из одних рук.
Сам CNKI на сайте скромно пишет: «результаты проверки могут содержать ошибки». На запросы журналистов не отвечает. А на Taobao уже вовсю торгуют «очистителями» — от дешёвых ботов за пару юаней до «ручного редактирования аспирантами» за 500–700 юаней (~7000–9000 рублей).
Рынок есть. Спрос огромный. Проблема никуда не делась.
Кстати, если у тебя сейчас висят свои учебные долги — рефераты, курсовые, НИР — есть сервис Openmaker (https://open-maker.ru/), который генерирует работы под российские ГОСТы с оплатой за конкретную штуку, без подписки. Пока китайские студенты воюют с детекторами, у нас хотя бы с этим попроще.
Что реально происходит с точностью детекторов
Выясним по-честному. Исследования 2024 года показывают: лучшие ИИ-детекторы (GPTZero, Turnitin AI, Originality.ai) дают ложные срабатывания в 15–25% случаев на человеческих текстах. Каждый четвёртый или пятый оригинальный текст может быть помечен как машинный.
Отдельная история — с нейтивностью языка. Академические исследования Стэнфорда зафиксировали: детекторы чаще ошибаются на текстах неносителей языка. У людей с более формальным стилем письма — тоже выше риск ложного срабатывания. Чем лучше пишешь — тем подозрительнее выглядишь.
Сяобин это прочувствовала лично. Она месяцами переписывала, меняла аргументы, переставляла слова — счётчик CNKI стоял на 50%+. Потом она нашла лайфхак: заменила точки на запятые. Предложения стали длинными и корявыми. Счётчик упал на 20% сразу.
Она сдала диплом с результатом 2% ИИ-контента. Закончила университет.
Цена: работа, которой она была горда, стала нечитаемой.
«Такое ощущение, что тебя наказывают за то, что ты пишешь слишком хорошо», — сказала она.
«Полупроводник» превратился в «0,5 проводника»
Отдельная история — с платными «очистителями». Студент из провинции Фуцзянь заплатил 500 юаней за «ручное редактирование». Редактор снизил ИИ-рейтинг — но в тексте традиционное украшение «три ножа» превратилось в «инструменты с тремя лезвиями», а «полупроводник» — в «0,5 проводника».
Технический термин буквально перевели как математическое выражение. Потому что ИИ-очиститель не понимает контекст — он просто меняет слова, чтобы сбить статистические паттерны. Обмануть детектор. Смысл работы при этом рассыпается.
Аналогия из жизни: это как взять хорошую картину, закрасить половину белым и сказать «ну, теперь точно оригинал».
Что интереснее всего — в разных системах один и тот же текст может показывать принципиально разные результаты. Студенты в социальных сетях пишут, что разброс показаний двух платформ для одной работы может достигать 50%. Одна говорит «0% ИИ», другая — «50% ИИ».
Это не инструмент измерения. Это рулетка.
Что говорят те, кто понимает в алгоритмах
Исследователь из Института автоматики Китайской академии наук объяснил просто: ИИ-детекторы ищут паттерны — средняя длина предложений, разнообразие лексики, структура текста. Если студент пишет академически грамотно — он попадает в зону «подозрительных» параметров.
Министерство науки и технологий КНР в официальной публикации назвало использование детекторов «технологическим суеверием». Это не я придумал — это государственное издание Science and Technology Daily написало буквально так. Нанкинский университет призвал преподавателей не полагаться слепо на алгоритмы.
Но тысячи студентов уже успели заплатить за сомнительные сервисы, испортить свои работы и убедиться: система написана не для них.
Что это говорит о нас
Мне кажется, тут есть один важный момент, который упускают в большинстве статей на эту тему.
Китайские университеты пытаются решить реальную проблему — студенты сдают работы, написанные машиной, и не получают никаких знаний. Это проблема. С этим нужно что-то делать.
Но выбранный инструмент — это не решение. Это перекладывание тревоги.
Когда детектор ненадёжен, преподаватели перестают думать сами — они смотрят на процент. Студенты перестают думать о содержании — они думают о том, как пройти проверку. Весь академический процесс превращается в гонку с алгоритмом.
Один анонимный профессор из Шаньдуна сравнил это с запретом на сексуальное просвещение для подростков: запрещаешь говорить о теме — проблема не исчезает, она уходит в подполье и обрастает там всем, чем только можно.
По-моему, честный разговор лучше детектора. Всегда.
И да — пока одни вузы строят детекторные барьеры, другие думают иначе. Некоторые преподаватели теперь просят студентов защищать работу устно и объяснять каждый раздел — это проверяет понимание куда надёжнее любого алгоритма. Если ты написал сам и разобрался в теме — ты объяснишь. Если нет — станет понятно за минуту.
Пока этот подход не стал стандартом, студентам приходится выкручиваться. Кто-то меняет точки на запятые. Кто-то платит за сервисы, которые превращают «полупроводник» в «0,5 проводника».
А кто-то просто хочет спокойно сдать диплом, который сам и написал. Без всей этой истории.
Кстати, если у тебя дедлайн горит прямо сейчас и некогда на все эти игры — Openmaker (https://open-maker.ru/) генерирует рефераты, курсовые и дипломные под ГОСТ, платишь только за конкретную работу. Программа лояльности там тоже есть: каждая следующая генерация дешевле. Без подписок и лишнего.
Вот так. Одни воюют с алгоритмом, другие просто делают дело.