При разработке сайтов часто возникает необходимость показывать читателям примерное время, которое потребуется на изучение материала. Это улучшает пользовательский опыт и повышает вовлечённость. Однако стандартные средства PHP для подсчёта слов не всегда корректно работают с многобайтовыми кодировками, такими как кириллица, арабское письмо или иероглифы. В этой статье мы разберём универсальное решение, которое учитывает особенности разных алфавитов и даёт точный результат.
Почему str_word_count не подходит
Встроенная функция str_word_count() ориентирована на латиницу и опирается на текущую локаль. Даже после установки локали она может неправильно распознавать символы Unicode, особенно если текст содержит смесь языков или специальные знаки. Поэтому для надёжного подсчёта слов в интернациональных проектах лучше использовать регулярные выражения с поддержкой Unicode.
Универсальная функция подсчёта слов
Вместо привязки к локали применим шаблон \p{L}, который обозначает любую букву любого языка. Модификатор u включает режим Unicode. Предварительно очистим текст от HTML-тегов и нормализуем пробелы.
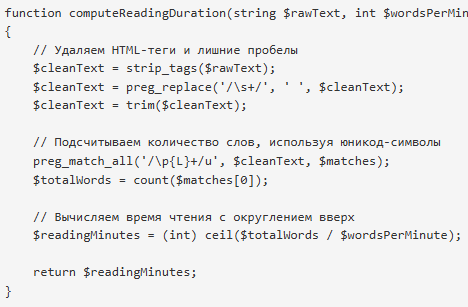
function computeReadingDuration(string $rawText, int $wordsPerMinute = 200): int
{
// Удаляем HTML-теги и лишние пробелы
$cleanText = strip_tags($rawText);
$cleanText = preg_replace('/\s+/', ' ', $cleanText);
$cleanText = trim($cleanText);
// Подсчитываем количество слов, используя юникод-символы
preg_match_all('/\p{L}+/u', $cleanText, $matches);
$totalWords = count($matches[0]);
// Вычисляем время чтения с округлением вверх
$readingMinutes = (int) ceil($totalWords / $wordsPerMinute);
return $readingMinutes;
}
Пояснения:
- strip_tags() удаляет всю разметку, оставляя только текст.
- Регулярное выражение \p{L}+ находит последовательности буквенных символов любых языков (латиница, кириллица, арабский, китайский и др.).
- Модификатор u заставляет PHP обрабатывать строку как UTF-8.
- Округление через ceil() даёт целое количество минут, что удобно для отображения (например, «3 минуты»).
Пример использования с кириллическим текстом
$article = "
<h2>Введение в PHP</h2>
<p>PHP — это скриптовый язык программирования, созданный для генерации HTML-страниц на веб-сервере. Он широко используется для разработки динамических сайтов и веб-приложений. Синтаксис языка прост и понятен, что делает его отличным выбором для начинающих разработчиков.</p>
<p>В этой статье мы рассмотрим основы работы с переменными, типами данных и управляющими конструкциями. Также затронем вопросы безопасности и оптимизации кода.</p>
";
$minutes = computeReadingDuration($article);
echo "Примерное время чтения: {$minutes} мин.";
В зависимости от объёма текста результат будет адекватно отражать реальное время, необходимое для ознакомления с материалом.
Дополнительные улучшения
- Скорость чтения: Значение 200 слов в минуту можно сделать настраиваемым через второй параметр, что уже реализовано в функции.
- Короткие тексты: Если слов меньше, чем скорость чтения, результат будет 1 минута — это корректно для информирования.
- Точность для языков с иероглифами: В китайском или японском слово может состоять из одного иероглифа, поэтому такой подсчёт всё равно даёт приемлемую оценку (обычно скорость чтения для таких языков измеряется в символах, но для универсальности оставим «слова» как последовательности букв).
Предложенный метод не зависит от локали сервера и гарантированно работает с любым языком, использующим Unicode. Это особенно важно для мультиязычных сайтов, где одна и та же функция должна одинаково хорошо обрабатывать русский, английский и, например, арабский тексты.
Внедрив такой расчёт, вы сделаете свой сайт удобнее для посетителей, не беспокоясь о том, на каком языке написан контент.