
Есть фраза, которая звучит успокаивающе почти в любой компании:
“Бэкапы есть. Всё хорошо.”
И вот где подвох: эта фраза отвечает только на один вопрос — что-то где-то сохраняется.
Она не отвечает на главный вопрос бизнеса:
“Если завтра всё ляжет — как мы вернём работу?”
План возврата в работу — это как раз про вторую часть вопроса, о которой многие забывают. Это не про “ещё один бэкап”, не про “ещё один отчёт”, и уж точно не про бюрократию.
Это про порядок действий, роли и критерии, которые превращают бэкапы из абстрактной надежды в управляемую способность вернуть 1С и ключевые сервисы.
ПОЧЕМУ БЭКАПЫ БЕЗ ПЛАНА — “НАБОР ФАЙЛОВ”
Представь простую ситуацию: 1С не открывается, часть сервисов не отвечает, пользователи ждут решения, бизнес считает простой.
В этот момент “бэкапы есть” превращается в череду вопросов, на которые надо отвечать не теорией, а фактами:
- Что поднимаем первым, чтобы компания хоть как-то начала работать?
- Откуда именно будем восстанавливать — и почему эта точка переживёт инцидент?
- Кто делает первые шаги, а кто принимает решения, если вариантов несколько?
- Где лежат доступы/ключи/учётки, которые нужны для восстановления?
- Сколько это займёт, хотя бы в грубом, но честном диапазоне?
- Как поймём, что “всё поднялось”: что считается восстановлением — “сервер включился” или “1С открывается и данные корректные”?
Если на эти вопросы нет подготовленных ответов, бэкапы в аварии становятся тем, чем они и были до аварии: файлами, из которых “когда-нибудь” можно “что-нибудь” достать. Иногда получается. Иногда нет. Почти всегда — дольше, чем ожидалось.
ПЛАН ВОЗВРАТА В РАБОТУ — ЭТО НЕ “ТОЛСТЫЙ ДОКУМЕНТ”
У многих слово “план” вызывает аллергию: сразу представляется папка, которая устаревает в день создания.
Поэтому договоримся о норме:
План возврата в работу — это короткий, обновляемый “операционный скелет”, который отвечает на вопросы аварии.
Ему не нужно быть идеальным. Ему нужно быть применимым.
Лучший формат для старта — одна страница. Если у вас будет одна страница, по которой реально можно действовать, вы уже впереди большинства компаний, где “бэкапы есть”, а порядка нет.
МИНИ-ТАБЛИЦА: “КАК ЕСТЬ” VS “КАК ДОЛЖНО БЫТЬ”
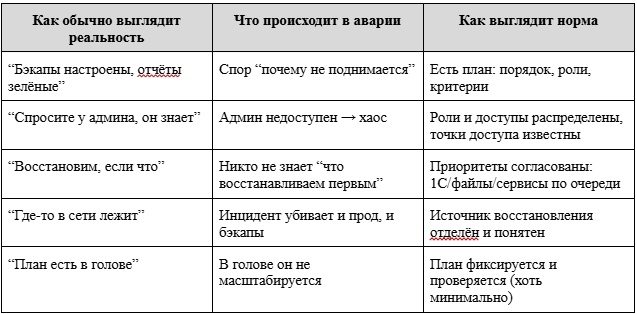
“ПЛАН НА ОДНУ СТРАНИЦУ”: МИНИМАЛЬНАЯ СТРУКТУРА, КОТОРАЯ РАБОТАЕТ
Ниже — семь блоков. Если заполнить их честно, у вас появится не “бумага”, а управляемость.
1) Цель возврата в работу (что считаем “успехом”)
Не “сервер поднялся”, а бизнес-результат:
- “1С открывается, документы доступны, проводки корректны, пользователи входят”
- “Файловая шара доступна на чтение/запись, критичные папки на месте”
Зачем: чтобы в аварии не спорить, “мы уже восстановились или ещё нет”.
2) Приоритеты: что поднимаем первым, чтобы бизнес ожил
Обычно это 3–5 пунктов, например:
- 1С (или её критичная часть)
- Файлы отдела продаж/бухгалтерии
- Почта/доступы (если без них никто не войдёт)
- Остальные сервисы
Зачем: без приоритетов восстановление превращается в “поднимем всё сразу”, а это всегда дольше и конфликтнее.
3) Временные ориентиры (без “идеальных цифр”)
Тут не нужно обещать космос. Нужно зафиксировать ожидания хотя бы диапазоном:
- “1С — не более X часов/суток”
- “Файлы — доступ в режиме ‘хотя бы чтение’ за Y часов”
Зачем: чтобы в момент Ч не выяснилось, что бизнес ожидал “за час”, а реальность “за три дня”.
4) Источник восстановления: откуда берём бэкапы и почему они выживут
Прямо простыми словами:
- где лежат бэкапы;
- почему инцидент “внутри сети” их не уничтожит;
- кто имеет доступ.
Зачем: потому что самый частый сценарий провала — когда бэкапы умирают вместе с инфраструктурой. (Эту тему мы специально разовьём в следующих статьях.)
5) Роли и доступы: кто что делает в первые часы
Минимально:
- Ответственный за восстановление (дежурный/ведущий)
- Ответственный за инфраструктуру/хранилище
- Контакт со стороны бизнеса (кто подтверждает приоритеты)
- Где лежат ключи/пароли/учётки (и кто может их получить)
Зачем: чтобы не зависеть от одного человека и не терять время на “кто знает пароль”.
6) Сценарий первых 120 минут (коротко, но реально)
Это не полная инструкция на 50 страниц. Это “что мы делаем сразу”:
- изоляция/остановка распространения (если нужно);
- фиксация состояния (что умерло, что живо);
- решение: восстанавливаем 1С или поднимаем временный режим;
- старт восстановления из выбранного источника.
Зачем: первые 2 часа задают весь темп аварии. Без сценария первые 2 часа уходят на разговоры.
7) Проверка и репетиция: как подтверждаем, что план не фантазия
Минимальная норма:
- раз в квартал — короткая репетиция (пусть на одном компоненте);
- после репетиции — 5 строк протокола: что поднимали, сколько заняло, что сломалось, что исправить.
Зачем: потому что план без проверки превращается в красивый текст.
САМЫЙ ВАЖНЫЙ ЭФФЕКТ: ПЛАН ЗАЩИЩАЕТ ИТ-ОТДЕЛ
Парадоксально, но “план возврата в работу” — это не только про устойчивость бизнеса. Это ещё и способ, чтобы ИТ не оказались крайними.
Потому что план фиксирует:
- ожидания бизнеса (что и за сколько возвращаем);
- факты проверки (что реально проверяли);
- границы ответственности (где нужен ресурс/решение от руководства).
И это переводит разговор из “почему вы не спасли” в “что у нас устроено и что нужно улучшить”.
МЯГКИЙ ШАГ ПРЯМО СЕЙЧАС: 10 МИНУТ, ЧТОБЫ ПОНЯТЬ РЕАЛЬНОСТЬ
Если хочется не “читать и вдохновляться”, а быстро понять, где вы находитесь:
- Запишите топ-3 систем, без которых бизнес “не живёт”.
- Напишите рядом: что поднимаем первым.
- Ответьте на один вопрос: откуда берём бэкапы и почему их нельзя убить тем же событием.
Если на третьем пункте начинается “ну… в целом… где-то…” — это нормально. Это просто значит, что следующий шаг очевиден.
КУДА ДАЛЬШЕ
План возврата в работу отвечает на вопрос “как мы вернём бизнес в работу”.
Но есть второе, не менее важное: а выживут ли сами бэкапы, когда “прилетит” — шифрование, удаление, доступы, человеческая ошибка или физическое изъятие.
Следующая статья будет как раз про это: “Бэкапы, которые нельзя “убить”: как защитить их от шифрования, человеческой ошибки, удаления и физического изъятия.”
Там разберём практические паттерны, как устроить хранение и доступ так, чтобы в "день Х" план возврата в работу не упёрся в фразу: “бэкапы тоже умерли”.
Мини-чек-лист (чтобы план не остался идеей)
- Есть определение “что значит восстановились” (по 1С и файлам).
- Есть список приоритетов (что первым/вторым).
- Есть понятный источник, откуда берём бэкапы, и почему он выживет.
- Есть роли и доступы на аварийный случай (не в голове одного человека).
- Есть короткий сценарий первых 120 минут.
- Есть правило репетиции и протокол результата.
Если закрыли хотя бы половину — вы уже превращаете “бэкапы” из набора файлов в управляемый возврат в работу.
А если руки не доходят и совет нужен уже сейчас, переходи по ссылке и записывайся на 1 бесплатную проверку бизнеса на восстановление.
Всё-таки лучше 1 раз проверить, чем разгребать последствия.