
Есть один неприятный факт, который ИТ обычно понимают раньше бизнеса:
бэкапы чаще всего умирают не потому, что “плохой софт”, а потому что они умирают вместе с продом — одним и тем же событием.
Шифровальщик в сети? Он шифрует всё, куда есть запись.
Компрометация админки? Удаляют всё, что можно удалить.
Ошибся человек? Сносит “не то” и ретеншн добивает хвост.
Площадка умерла или серверы увезли? Уехали и бэкапы.
Поэтому “неубиваемые бэкапы” — это не “купить что-то большое и красивое”. Это сделать две вещи:
- сделать копии независимыми (чтобы их нельзя было убить одним событием),
- не переборщить по цене, потому что любая защита должна быть экономически адекватной:
защита не должна стоить дороже того, что она защищает.
ПРАВИЛО 3-2-1: БАЗА, КОТОРУЮ НУЖНО ЗНАТЬ, НО НЕ ОБЯЗАТЕЛЬНО КОПИРОВАТЬ “В ЛОБ”.
Про 3-2-1 слышали почти все, и из-за этого многие воспринимают его как религию: “если не 3-2-1 — значит у вас нет бэкапов”. Это ошибка.
3-2-1 — это не обязательный стандарт. Это шпаргалка здравого смысла, которая не даёт забыть главное: бэкапы должны пережить инцидент.
Что означает 3-2-1 по-человечески:
- 3 копии данных: рабочие данные + минимум две резервные версии.
- 2 разных типа хранения/носителя: чтобы не умереть от одной и той же поломки/ошибки/особенности платформы.
- 1 копия вне основной площадки/вне зоны поражения: чтобы “гибель сети”, пожар или физическое изъятие не снесли всё сразу.
Почему это важно именно для “неубиваемости”.
Потому что 3-2-1 заставляет задать правильные вопросы:
- “Сколько у нас копий реально независимы?”
- “У них разные способы умереть или один и тот же?”
- “Есть ли копия, которая переживёт ‘гибель сети’?”
- “Мы из неё поднимались или просто верим?”
Когда 3-2-1 можно не соблюдать буквально.
Иногда “2 носителя” и “3 копии” не нужны в буквальном виде, если смысл закрыт другими слоями:
- есть изоляция (прод не может писать в бэкапы),
- есть неизменяемость (нельзя быстро удалить/переписать историю),
- есть вне-зоны-поражения слой (оффлайн/вне площадки),
- есть проверяемость (восстановление реально делали).
Но даже если вы делаете схему “не по учебнику”, знать 3-2-1 нужно, потому что это самый быстрый способ поймать самообман:
“бэкапы есть” не равно “у нас есть независимые бэкапы”.
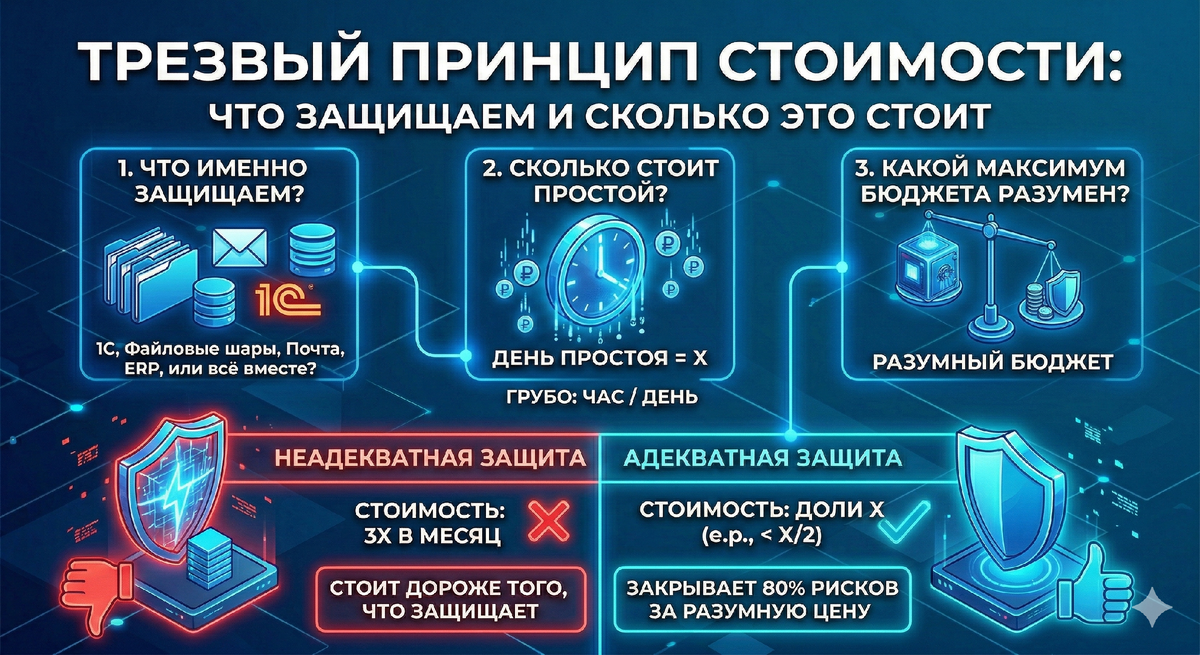
ТРЕЗВЫЙ ПРИНЦИП СТОИМОСТИ: ЧТО ЗАЩИЩАЕМ И СКОЛЬКО ЭТО СТОИТ
Перед тем как строить “неубиваемость”, полезно один раз ответить себе (и бизнесу) на три вопроса:
- Что именно защищаем? (1С? файловые шары? почта? ERP? всё вместе?)
- Сколько стоит простой? (хотя бы грубо: час/день)
- Какой максимум бюджета разумен?
Если день простоя стоит условно X, то защита уровня “3X в месяц” обычно неадекватна.
А вот защита, которая стоит “доли X” и закрывает 80% рисков — адекватна.
ЧТО ИМЕННО “УБИВАЕТ” БЭКАПЫ В РЕАЛЬНОСТИ
Пять сценариев, которые чаще всего встречаются в среднем бизнесе.
- Шифровальщик шифрует хранилище бэкапов (потому что оно доступно как обычная шара/репозиторий).
- Компрометация админских прав → целенаправленное удаление/подмена (через консоль, политики, ретеншн).
- Человеческая ошибка (не та политика, удалили не то, перезаписали, “прибрались”).
- Бэкапы есть, но восстановить нельзя (нет ключей, нет доступов, нет порядка, нет навыка).
- Физическое изъятие/гибель площадки (вынесли/сгорело/умерло — ушло всё).
“НЕУБИВАЕМОСТЬ” — ЭТО 4 СВОЙСТВА. 3-2-1 ПОМОГАЕТ ПРОВЕРИТЬ, ЧТО ОНИ ЕСТЬ
Чтобы бэкапы выживали, нужны четыре свойства. Они важнее, чем конкретный продукт.
1) Изоляция: бэкапы не должны быть доступны на запись из той же среды, где живёт прод.
Проверка через 3-2-1 (по смыслу): если шифровальщик в сети и у него есть путь записи к бэкапам — “1 копия вне зоны поражения” у вас отсутствует по факту, даже если “копий три”.
2) Неизменяемость: в течение окна (например, 7–30 дней) нельзя тихо удалить/переписать историю.
Проверка: если один человек с одним набором прав может “в ноль” снести историю — ваши “3 копии” могут исчезнуть одним действием.
3) Вне зоны поражения: Хотя бы один слой должен пережить “гибель сети” или площадки.
Проверка: если все копии живут в одном контуре/одной площадке — это “1” в 3-2-1 провалено.
4) Проверяемость: если восстановление не делали — это гипотеза.
Проверка: любая схема 3-2-1 бессмысленна, если “2 носителя” и “1 вне площадки” существуют, но из них никто ни разу не поднимался.
ТАБЛИЦА: УГРОЗА → КАК “УБИВАЮТ” → ЧТО ДАЁТ МАКСИМУМ ЭФФЕКТА ЗА МИНИМУМ ДЕНЕГ
МИНИМАЛЬНЫЙ СТАНДАРТ “НЕУБИВАЕМЫХ БЭКАПОВ” ДЛЯ СРЕДНЕГО БИЗНЕСА (БЕЗ ФАНАТИЗМА)
Если бюджет ограничен, вот “минимум, который работает” и почти всегда укладывается в принцип стоимости.
Минимум A: разделить прод и бэкапы по правам и зоне
- отдельная зона/ACL,
- отдельные учётки,
- прод не имеет права записи “куда-то, где лежит история”.
Минимум B: защитить историю от мгновенного уничтожения
- окно защищённого хвоста 7–14 дней (или больше, если бизнесу надо),
- ограничение удаления/перезаписи.
Минимум C: хотя бы один слой вне зоны поражения
Здесь не обязательно строить второй дата-центр. Часто достаточно дешёвого, но правильного слоя, который не живёт в сети постоянно.
Минимум D: проверяемость
Раз в квартал поднять 1С/критичный компонент и зафиксировать:
- сколько заняло,
- что сломалось,
- что менять.
Что НЕ делать (если держим принцип “защита не дороже объекта”)
Частые перекосы бюджета с которыми мы сталкиваемся на практике:
- покупать сложные системы мониторинга/детекции, когда бэкапы лежат в той же зоне и под теми же правами;
- строить “идеальную” платформу бэкапов без базовой изоляции и защиты от удаления;
- делать дорого и сложно там, где один “вне сети” слой закрывает 80% катастрофических сценариев.
МИНИ-ЧЕК-ЛИСТ: ВЫ СЛЕДУЕТЕ СМЫСЛУ 3-2-1 И ВАШИ БЭКАПЫ ДЕЙСТВИТЕЛЬНО ЖИВУЧИЕ, ЕСЛИ…
- Есть минимум две независимые версии данных (не “в одной папке”, а реально независимые).
- Есть разные способы хранения/разные контуры, чтобы не умереть от одной ошибки/площадки.
- Есть хотя бы один слой вне зоны поражения (переживёт “гибель сети”).
- Прод и пользовательская среда не могут писать в историю бэкапов.
- Нельзя одним действием “снести всё” (есть защищённый хвост / иммутабельность).
- Восстановление проверяется и протоколируется.
Если пройтись по чек-листу честно, почти всегда “сыпется” один и тот же пункт: слой вне зоны поражения. Не потому что “никто не знает 3-2-1”, а потому что в реальности все версии живут в одном контуре: та же сеть, те же админские права, то же управление. В итоге при шифровании или компрометации учёток бэкапы погибают не “потом”, а вместе с продом — их шифруют или удаляют тем же способом.
И вот здесь появляется самая практичная развилка: можно продолжать усложнять онлайн-контур (и платить за это), а можно закрыть 80% катастрофических сценариев одним простым слоем — оффлайн-бэкапом, которого нет в сети, когда всё горит. Это то, что мы между собой называем “страховым сейфом”.
Если интересно, как сделать такой слой дёшево и правильно, смотри статью: Оффлайн-бэкап как “страховой сейф”: защита, которая стоит дёшево и выживает, когда гибнет сеть.
А если руки не доходят и совет нужен уже сейчас, переходи по ссылке и записывайся на 1 бесплатную проверку бизнеса на восстановление.
Всё-таки лучше 1 раз проверить, чем разгребать последствия.