Мир вычислительных мощностей для ИИ переживает системный сдвиг: эпоха абсолютного доминирования GPU уступает место мультиархитектурной реальности, где ключевыми становятся энергоэффективность, низкая задержка и детерминированность вычислений.
За этим стоит не столько разовая мода, сколько цепочка серьёзных сигналов — коммерциализация Google TPU, крупные заказы от ведущих игроков, массовое внедрение «нетрадиционных» чипов (Cerebras, Groq и др.) и дорогостоящие стратегические сделки вроде покупки разработок Groq компанией NVIDIA. Ниже — что изменилось и почему это важно.
По утекшей в начале 2026 года информации, Google планирует развернуть 6–7 миллионов TPU к 2027 году и коммерчески поставлять часть этих мощностей внешним клиентам (Anthropic, OpenAI, Meta, Apple и др.).
Anthropic, по сообщениям, оформила заказ на инфраструктуру на базе TPU примерно на $21 млрд; Meta — тоже ведёт многомиллиардные закупки у Google.
OpenAI начал использовать в продакшне не‑GPU решения: в одной из недавних развёрток (GPT-5.3-Codex-Spark) задействованы кластеры Cerebras — wafer‑scale чипы с высокой пропускной способностью и низкой задержкой.
Прогнозы аналитиков: доля серверов на не‑GPU архитектурах вырастет — по Goldman Sachs доля таких поставок в AI‑сервисах вырастет с ~36% (2024) до ~45% (2027); IDC прогнозирует, что к 2028 году в Китае доля non‑GPU серверов приблизится к 50%.
Эти факты указывают, что индустрия начинает активно диверсифицировать аппаратную базу.
Ключевой драйвер — фундаментальная проблема архитектуры GPU: частые перемещения данных между вычислительными блоками и внешней памятью создают высокий overhead по энергии и задержкам. Для задач больших моделей именно затраты на перенос данных и коммуникацию становятся узким местом, а не одна лишь плотность операций.
Новые или «альтернативные» архитектуры (TPU‑класс и wafer‑scale) решают эту проблему несколькими путями:
- уменьшением объёма внешних передвижений данных (большее локальное хранение — SRAM/DRAM рядом с вычислением),
- оптимизацией сетевой топологии кластеров (низколатентные interconnect / OCS),
- программно‑аппаратной интеграцией (software‑defined hardware, статическая/детерминированная расписанная обработка тензорных потоков).
Вместе это даёт значительный выигрыш по энергоэффективности, стоимости на токен и времени первого отклика (latency) — параметры, критичные для интерактивных сценариев (онлайн‑кодогенерация, real‑time inference).
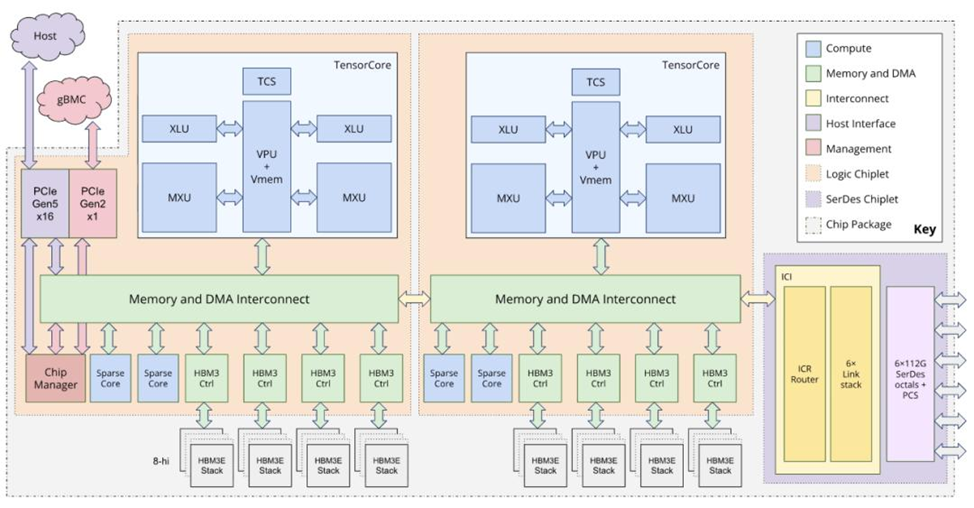
Google TPU долгое время оставались преимущественно внутренним ресурсом. Но выпуск v7 и коммерческая стратегия меняют правила:
TPU v7 заявлен с пиковым FP8‑производительностью ~4614 TFLOPS на чип и возможностью масштабирования до тысяч чипов (в статических бенчмарках — десятки EFLOPS на кластер), при этом энергопотребление на единицу работы значительно ниже чем у флагманских GPU.
Для крупных игроков это означает: при той же полезной черезмерной мощности можно резко снизить затраты на inference и training — и получить почти линейное ускорение в масштабируемых сетях благодаря продвинутым коммутаторам OCS.
Именно поэтому крупные заказчики массово ставят заказы на TPU‑системы — по сути голосуя кошельком за архитектурную диверсификацию.
Groq (архитектура TSP — Tensor Streaming Processor) позиционируется как «software‑defined hardware»: детерминированные потоки данных, статическое планирование, большие on‑chip буферы и низкая латентность для первых токенов.
Эти свойства дают выигрыш в интерактивных сценариях — снижение задержки первого ответа на 20–50% по сравнению с некоторыми TPU, снижение стоимости токена на 10–30% в задачах inference. Именно разработки Groq привлекли внимание и были куплены NVIDIA за значительную сумму (порядка десятков миллиардов долларов), что сигнализирует о стратегическом характере технологии.
Cerebras идёт по линии wafer‑scale: максимально высокая плотность ядер и сверхкороткие межядровые связи внутри одной пластинки даёт огромную пропускную способность и низкие задержки на межкомпонентные коммуникации. Для ряда крупных моделей CS‑кластеры демонстрируют кратный выигрыш по throughput и существенную экономию по суммарной стоимости и энергопотреблению.
Общая идея: уход от модели «много данных везутся к вычислениям» к парадигме «вычисления идут к данным» — это архитектурный сдвиг.
NVIDIA — всё ещё главный игрок, но её доминирование ставится под вопрос по нескольким направлениям:
- Сценарии с жёсткими требованиями к latency и энергопотреблению выгоднее реализовывать на специализированных TPU‑классах или wafer‑scale чипах.
- Попытки NVIDIA ускорить трансформацию (приобретение технологий Groq, развитие собственных NPU/DPUs) — признают тренд, но не гарантируют автоматическую защиту лидерства.
- Практический вывод: в ближайшие годы архитектурная диверсификация станет нормой: крупные облачные и AI‑провайдеры будут комбинировать GPU, TPU‑классы и wafer‑scale решения в зависимости от рабочей нагрузки.
Переход к «многокорневой» инфраструктуре уже идёт: модели, workflow и бизнес‑юниты будут привязываться к наиболее экономичному и подходящему стеку. Это даёт следующие преимущества:
- гибкость закупок и переговорных позиций (лучше торговаться с поставщиками мощности),
- снижение общей зависимости от единого вендора,
- оптимизация TCO (total cost of ownership) под конкретные KPI (latency, cost per token, throughput).
Anthropic — пример компании, извлекающей выгоду, комбинируя TPU и GPU для снижения затрат и усиления переговорных позиций.
Для Китайских чипмейкеров (и их экосистем) текущая трансформация — шанс и испытание одновременно:
- шанс — спрос на альтернативные архитектуры и локальные решения открывает рынок для инноваций (3D‑chiplet, near‑memory computing, специализированные interconnect);
- испытание — надо не просто клонировать чужие TPU, а придумать собственные дифференцирующие решения (интеграция вертикально, уникальные сетевые технологии, глубокая оптимизация под китайские облачные стеки и отраслевые кейсы).
Кто просто воспроизводит общие идеи — рискует остаться в роли поставщика «кусочков», а те, кто предложит настоящий архитектурный прорыв, получат место за столом глобальной конкуренции.
Выводы: новый «правитель» не объявлен, но правила изменились
- Эра «GPU‑всё» теряет монополию: решающими становятся энергоэффективность и задержка, а не только пиковый TFLOPS.
- TPU‑класс и wafer‑scale решения уже демонстрируют коммерческий смысл: крупные заказы, успешные бенчмарки и реальные кейсы в продакшне.
- Будущее за гибридными инфраструктурами: «каждая задача — под свою архитектуру», а победителями станут те, кто умеет оптимально сочетать чипы, interconnect и софт‑стек.
- Для индустрии это — шанс снизить зависимость от одного поставщика и перейти к более устойчивой, экономичной и многополярной архитектуре вычислений.
Перестановки только начали разворачиваться. Кто возьмёт инициативу — покажет следующий год: серьёзные заказы, новые архитектурные решения и стратегические сделки зададут тон следующей крупных вычислительной гонке.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/