
Как работает Elasticsearch: основные принципы
Чтобы понимать возможности Elasticsearch, нужно разобраться с его внутренним устройством. В его основе лежат четыре ключевые идеи:
- Распределенная архитектура и отказоустойчивость: Elasticsearch — это система, которая строится вокруг кластера — группы серверов (узлов), работающих как единое целое . Данные хранятся в индексах (аналог базы данных в реляционном мире) . Каждый индекс разбивается на куски — шарды (primary shards). Это позволяет распределить данные по всем узлам кластера, чтобы обрабатывать их параллельно . Для надежности у каждого основного шарда создаются копии — реплики (replica shards). Если один сервер выйдет из строя, данные не пропадут, так как их копии есть на других узлах . Сам кластер постоянно следит за своим состоянием: если узел покидает кластер, "главный" узел (Master Node) перераспределяет его шарды на оставшиеся машины, используя реплики .
- Как происходит поиск (инвертированный индекс): Секрет мгновенного поиска Elasticsearch — в особом способе организации данных, называемом инвертированным индексом . Процесс можно представить так:
При добавлении документа в индекс, его текст разбивается на отдельные слова (токены) с помощью анализатора (например, стандартный для английского или ik для китайского) .
Затем строится таблица (инвертированный индекс), где для каждого уникального слова хранится список документов, в которых оно встречается . Когда вы ищете слово "смартфон", системе не нужно сканировать все документы — она просто заглядывает в эту таблицу и моментально получает список подходящих документов. - Балансировка нагрузки и координация запросов: В Elasticsearch есть специальный тип узлов — координаторы (Coordinating Nodes) . Когда вы отправляете поисковый запрос, он попадает именно на такой узел. Координатор анализирует запрос, определяет, в каких шардах хранятся нужные данные, и отправляет подзапросы на все эти шарды параллельно. Затем он собирает результаты, сортирует их (если нужно) и возвращает вам единый ответ. Это позволяет равномерно распределять нагрузку и не перегружать отдельные узлы кластера .
- "Почти реальное время" (Near Real-Time): Elasticsearch не гарантирует, что данные станут доступны для поиска мгновенно после отправки. По умолчанию новые данные появляются в поиске через 1 секунду . Это достигается за счет механизма refresh, который периодически сбрасывает данные из оперативной памяти на диск в сегменты, делая их доступными для поиска .
Основные функции Elasticsearch
Возможности Elasticsearch выходят далеко за рамки простого поиска по тексту. Это полноценная платформа для работы с данными.
- Поисковые возможности: Поддерживает сложные запросы: нечеткий поиск с опечатками (fuzzy), автодополнение (search-as-you-type), поиск по смыслу (семантический поиск через вектора), подсветку найденных слов (highlighting) и ранжирование результатов по релевантности с помощью алгоритма BM25 .
- Анализ данных (Aggregations): Elasticsearch умеет не только искать, но и анализировать данные "на лету". С помощью агрегаций можно строить аналитические отчеты прямо в момент поиска: считать средний чек (metric), группировать товары по категориям (bucket), строить временные ряды (date_histogram) и даже накладывать сложные конвейеры обработки данных (pipeline) .
- Обеспечение надежности (Resilience): Для промышленной эксплуатации критически важны встроенные механизмы обеспечения отказоустойчивости:
Управление жизненным циклом индексов (ILM): Позволяет автоматически перемещать старые данные с быстрых и дорогих SSD на более дешевые жесткие диски или в объектное хранилище, а когда данные становятся совсем неактуальны — удалять их .
Резервное копирование (Snapshot and Restore): Elasticsearch умеет создавать "снимки" данных и сохранять их в надежное внешнее хранилище (например, Amazon S3 или файловую систему) для восстановления в случае катастрофы .
Кросс-кластерная репликация (CCR): Позволяет синхронизировать данные между кластерами, находящимися в разных дата-центрах или даже географических регионах. Это нужно для организации аварийного восстановления (disaster recovery) или для того, чтобы приблизить данные к пользователям в разных частях света . - Безопасность и управление доступом: Начиная с определенных версий, Elasticsearch предоставляет мощные средства безопасности (X-Pack) :
Шифрование трафика (SSL/TLS) между узлами и клиентами для защиты от перехвата данных .
Ролевое управление доступом (RBAC), позволяющее гибко настраивать, кто и к каким индексам, документам и даже отдельным полям имеет доступ .
Аутентификация через интеграцию с LDAP, Active Directory или SAML для Single Sign-On (SSO) .
Сравнительная таблица: Elasticsearch и другие решения
Чтобы понять место Elasticsearch в экосистеме, полезно сравнить его с другими популярными инструментами, которые часто решают схожие задачи.
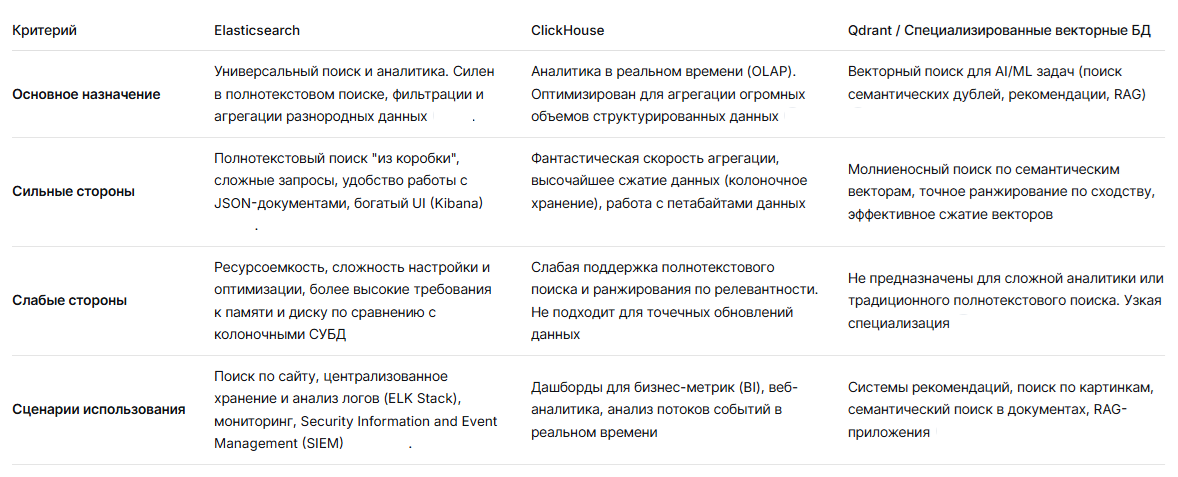
Применение в System Design
При проектировании архитектуры приложений Elasticsearch может играть разные роли.
- Роль в архитектуре: Чаще всего Elasticsearch выступает в качестве вторичного индекса (secondary index) и поискового движка поверх основной базы данных (например, PostgreSQL или MySQL) . Основная база (source of truth) хранит все данные и отвечает за транзакции (создание заказа, обновление профиля). Elasticsearch используется для задач, с которыми реляционные базы справляются плохо: быстрый полнотекстовый поиск, фасетная навигация (фильтры по категориям, ценам), аналитические срезы данных . Такое разделение ответственности позволяет эффективно масштабировать каждую часть системы независимо.
- Как обеспечить синхронизацию данных: Данные из основной БД должны попадать в Elasticsearch. Типовой паттерн — использование Change Data Capture (CDC). Инструменты вроде Debezium или Canal читают журнал транзакций основной базы данных (binlog в MySQL) и публикуют все изменения (вставки, обновления, удаления) в очередь сообщений, например, Apache Kafka . Отдельный микросервис-потребитель забирает эти события из Kafka и обновляет индекс в Elasticsearch . Это гарантирует, что данные в поиске будут актуальными с минимальной задержкой, не нагружая основную базу.
- Интеграция с ELK Stack для Observability: Классический пример использования — построение системы observability (наблюдаемости). Легковесные агенты (Filebeat, Metricbeat) собирают логи и метрики с серверов и приложений, передают их в Logstash . Logstash может обогащать, парсить и фильтровать эти данные (например, извлекать IP-адрес или уровень ошибки из строчки лога с помощью grok-шаблонов) . Очищенные данные отправляются в Elasticsearch для хранения. Разработчики и администраторы могут просматривать, искать и визуализировать эти данные через веб-интерфейс Kibana, строить графики и дашборды для мониторинга состояния системы .
Как развернуть и настроить Elasticsearch
Развертывание и настройка — это, пожалуй, самая сложная часть работы с Elasticsearch. Ошибки на этом этапе могут привести к нестабильной работе или потере данных.
- Варианты развертывания: Есть три основных способа:
Напрямую из бинарных пакетов: Подходит для разработки или если нужен полный контроль над средой. Скачиваете архив с сайта Elastic, распаковываете и запускаете bin/elasticsearch .
Через пакетный менеджер (apt/yum): Удобно для управления на серверах с Linux, так как Elasticsearch автоматически регистрируется как системный сервис .
С помощью Docker: Самый популярный способ для контейнеризированных сред и оркестрации (Kubernetes). Запускается одной командой docker run, но требует правильного проброса портов и настройки томов для хранения данных . - Ключевые параметры конфигурации (elasticsearch.yml): Основной файл настройки. Здесь задаются критически важные параметры:
cluster.name: Имя кластера. Все узлы с одинаковым именем объединяются в один кластер .
node.name: Уникальное имя узла в кластере .
network.host: Сетевой интерфейс, на котором Elasticsearch будет слушать запросы. Для продакшена нельзя оставлять localhost .
discovery.seed_hosts: Список узлов в кластере, которые будут использоваться для обнаружения других узлов .
cluster.initial_master_nodes: Список узлов, которые участвуют в начальных выборах "главного" узла при первом запуске кластера . - Как настроить безопасность: Для production-среды критически важно включить безопасность. Это делается в том же elasticsearch.yml:
Включается xpack.security.enabled: true и шифрование транспорта .
Генерируются сертификаты для узлов, чтобы они могли общаться по SSL.
С помощью утилиты elasticsearch-setup-passwords задаются пароли для встроенных пользователей (например, elastic и kibana) .
Далее создаются роли и пользователи через API или Kibana . - Основы оптимизации (JVM Heap, шарды):
Память (JVM Heap): Это самый важный параметр. Размер кучи Java (Heap) задается в файле jvm.options параметрами -Xms и -Xmx . Золотое правило: не ставьте больше 32 ГБ. Оптимально — 50% от всей оперативной памяти сервера, но не более 32 ГБ . Остальная память нужна операционной системе для кэширования файлов (Filesystem Cache), что критически важно для производительности поиска .
Шарды (Shards): Размер одного шарда не должен быть слишком большим. Рекомендуется держать его в пределах 10-50 ГБ . Слишком много мелких шардов тоже плохо — это создает нагрузку на кластер. Количество шардов задается при создании индекса и не может быть легко изменено в будущем, поэтому к этому вопросу нужно подходить продуманно .
Страховка на собеседовании
Знание есть, но стресс мешает?
Бесплатное сообщество для прокачки карьеры в IT
Подпишись на https://t.me/IT_Interview_Partner_Bot
Подпишись на https://t.me/LyakhovEugene