Как известно, недавно был развернут кластер Proxmox VE из 5 узлов с хранилищем Ceph. Это позволило изучить работу с PVE более детально. Также ранее публиковалась статья о том, как выполнять последовательные обновления без простоев (zero-downtime rolling updates) в кластере из 5 узлов и о применяемом для этого процессе. Он включал проверку Ceph, подтверждение кворума, переход в режим обслуживания, миграцию рабочих нагрузок, установку патчей, перезагрузку, проверку и т. д. Примерно в то же время был анонсирован новый проект с открытым исходным кодом от Gyptazy — разработчика ProxLB и других инструментов. Он называется ProxPatch и предназначен для оркестрации последовательной установки патчей в кластерах Proxmox VE.
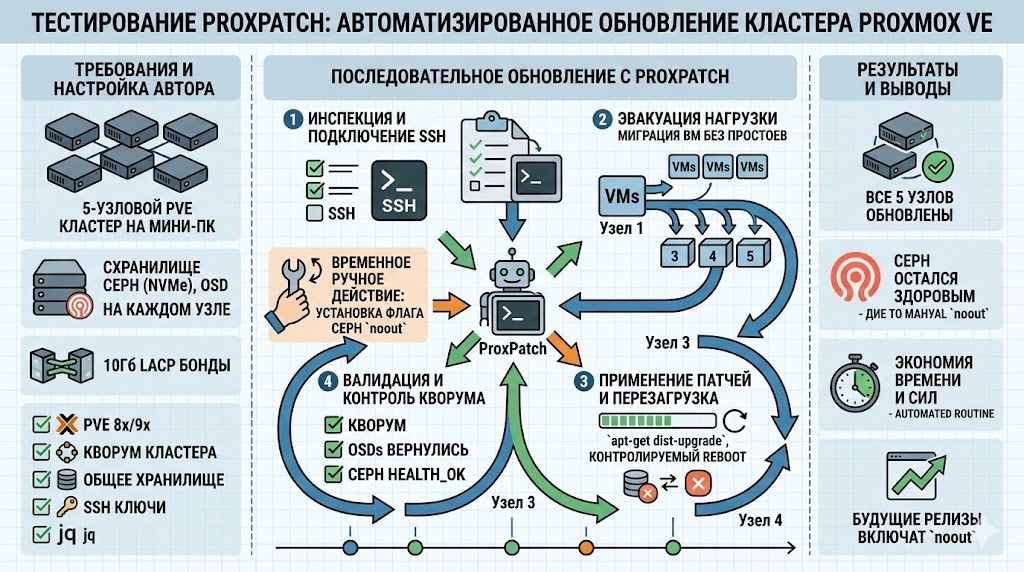
Давайте разберем, что он делает, как он работает на практике и стоит ли ему доверять.
Текущая конфигурация кластера
Вся лаборатория на базе мини-ПК размещена в 10-дюймовой стойке и имеет следующую конфигурацию:
- 5 узлов Proxmox
- Хранилище Ceph на базе NVMe
- На каждом узле запущено по два OSD
- Объединение Dual 10Gb LACP
- Использование vPro для внеполосного управления (out of band management)
- Сегментация VLAN для трафика кластера, хранилища и виртуальных машин
- Реальные рабочие нагрузки (production)

Каждый узел участвует в хранилище Ceph с двумя OSD. Это означает, что при перезагрузке хоста OSD временно отключаются. Ceph переносит это достаточно хорошо, но все же необходимо соблюдать осторожность и отключать только один узел за раз — или то количество узлов, которое кластер Proxmox/Ceph может выдержать для сохранения кворума.
Также стоит отметить, что первый официальный релиз Proxpatch не заявляет о поддержке Ceph. Ожидается, что эта функция появится в следующем релизе. Тем не менее, было решено протестировать функциональность в любом случае, просто вручную управляя флагом noout.
Что такое ProxPatch и что он делает?
Решение с открытым исходным кодом ProxPatch — это инструмент оркестрации последовательной установки патчей. Он позволяет автоматизировать обновление кластеров Proxmox VE без прерывания запущенных рабочих нагрузок. Вместо ручного освобождения узлов (drain) можно использовать ProxPatch для оркестрации этих шагов и задач.
Он выполняет следующее:
- Анализирует состояние кластера
- Обновляет узлы с использованием SSH-соединения
- Определяет, требуется ли перезагрузка
- Переносит запущенные виртуальные машины с затрагиваемых узлов
- Выполняет контролируемые перезагрузки, сохраняя кластер в рабочем состоянии
Одно из преимуществ подхода, применяемого в этом проекте, заключается в использовании нативных инструментов, которые уже включены в Proxmox. Таким образом, не требуется устанавливать ничего лишнего. Что именно используется?
На высоком уровне процесс выглядит так:
- Подключение к узлам по SSH
- Проверка наличия обновлений
- Эвакуация рабочих нагрузок
- Установка обновлений
- Перезагрузка при необходимости
- Переход к следующему узлу
Требования для использования в кластере
Есть несколько требований и деталей, которые стоит учесть. Необходимо следующее:
- PVE 8x или 9x
- Кворум кластера
- Общее хранилище для возможности переноса виртуальных машин между узлами
- Доступ по SSH ко всем узлам кластера (рекомендуется использовать SSH-ключ)
- Утилита jq на машине, где запущен ProxPatch, для парсинга JSON
Установка ProxPatch
Установка проходит просто. ProxPatch очень легковесный и не требует ничего особенного для запуска.
ВНИМАНИЕ: Дзен некорректно отображает коды и команды консоли. Для корректного копирования и использования рекомендуем смотреть оригинал статьи на сайте:
Разработчик разместил установочные файлы в своем репозитории, который можно добавить, а затем выполнить установку с помощью стандартной команды apt-get:
Default
# Добавление официального репозитория gyptazy.com
curl https://git.gyptazy.com/api/packages/gyptazy/debian/repository.key -o /etc/apt/keyrings/gyptazy.asc
echo "deb [signed-by=/etc/apt/keyrings/gyptazy.asc] https://packages.gyptazy.com/api/packages/gyptazy/debian trixie main" | sudo tee -a /etc/apt/sources.list.d/gyptazy.list
apt-get update
# Установка ProxPatch
apt-get install -y proxpatch
Установка связки ключей (keyring):
Ниже показана установка пакета:
Наконец, после установки решения необходимо просто включить службу и запустить ее:
Default
systemctl enable proxpatch
systemctl start proxpatch
Судя по инструкциям на странице Github, конфигурационный файл, расположенный по пути /etc/proxpatch/proxpatch.yaml, является необязательным. Однако на практике при запуске службы возникала ошибка из-за отсутствия конфигурационного файла:
Эта проблема была легко решена путем создания простого конфигурационного файла proxpatch.yaml в директории /etc/proxpatch со следующим содержимым:
Default
ssh_user: root
deactivate_proxlb: false
Перед запуском ProxPatch
Перед запуском ProxPatch в кластере необходимо провести несколько быстрых проверок работоспособности. Во-первых, следует убедиться, что хранилище Ceph находится в исправном состоянии. Это можно сделать, выполнив следующую команду. Стоит отметить, что, по словам разработчика, в следующем релизе ProxPatch появится поддержка кластеров Proxmox с Ceph путем установки флага noout для кластера Ceph.
Default
ceph -s
Были проверены следующие параметры:
- HEALTH_OK
- Все OSD находятся в состоянии up и in
- Отсутствуют процессы восстановления (recovery) или заполнения (backfill)
- Все PG находятся в состоянии active+clean
Затем был проверен кворум для кластера Proxmox в целом:
Default
pvecm status
Все узлы находились в кворуме и работали стабильно.
Обновление первого узла
Когда ProxPatch начал свою работу, контроль за процессом осуществлялся путем проверки статуса службы, что позволяет видеть текущие выполняемые задачи.
При ручном подходе узел явно переводится в режим обслуживания с помощью команды:
Default
ha-manager crm-command node-maintenance enable
Это гарантирует контролируемый перенос рабочих нагрузок.
ProxPatch корректно справился с эвакуацией. Виртуальные машины начали мигрировать с первого узла до применения обновлений. Поведение при миграции было аналогично тому, что наблюдается при ручном переходе в режим обслуживания.
Если посмотреть статус службы с помощью systemctl, можно увидеть завершенные задачи или те, над которыми ведется работа:
Default
systemctl status proxpatch
После обновления всех узлов в сообщениях о статусе появится соответствующая информация. Служба снова проверяет наличие обновлений каждые 6 часов:
Поведение Ceph при автоматизации
Это самая важная часть. Следует помнить, что разработчик планирует выпустить будущую версию инструмента с «поддержкой» Ceph, чтобы он корректно устанавливал флаг noout. В кластере на базе Ceph автоматизация может быть опасной, если процессы происходят слишком быстро.
Вот несколько моментов в Ceph, на которые необходимо обращать внимание и которые следует отслеживать при любом процессе, будь то ручной или автоматизированный:
- Переходы состояний OSD (up/down)
- Состояния PG
- Поведение заполнения (backfill)
- Штормы восстановления (recovery storms)
- Задержки записи (write latency)
ProxPatch соблюдает последовательное выполнение. Он не пытался обрабатывать несколько узлов одновременно. Это один из критических аспектов в среде Ceph. В ходе тестирования Ceph оставался работоспособным на протяжении всего процесса и не наблюдалось никаких проблем.
В каких случаях целесообразно использовать ProxPatch
У данного протестированного релиза ProxPatch есть несколько сильных сценариев использования. Ожидается появление новых функций и возможностей, включая полноценную поддержку Ceph, поэтому данные выводы основаны на текущей версии. Использование этого инструмента имеет большой смысл для:
- Небольших кластеров без Ceph (в текущей версии)
- Кластеров, где операционная стабильность важнее ручного вмешательства
- Сред, где установка патчей часто откладывается из-за своей утомительности
Автоматизация снижает вероятность того, что обновления будут отложены на недели, или что будет пропущен важный шаг, который необходимо выполнить перед применением обновлений. Это также уменьшает риск забыть эвакуировать рабочие нагрузки перед установкой патчей. Для пользователей домашних лабораторий, которые только осваивают последовательные обновления (rolling updates), ProxPatch значительно снижает порог входа.
Действительно ли использование ProxPatch экономит время?
Да, экономит. Инструмент берет на себя все планирование и тяжелую работу, позволяя использовать подход «настроил и забыл» (set it and forget it), особенно в условиях домашней лаборатории. При типичном кластере из 5 узлов в домашней лаборатории на полное обновление, проверку, перезагрузку и прочее уходит около 30 минут и более.
С ProxPatch можно запустить процесс и наблюдать за ним со стороны, занимаясь своими делами. Выполнение по-прежнему требует времени, но предполагает гораздо меньше ручного вмешательства. С точки зрения рабочего процесса это очень ценно.
Заключение
ProxPatch — это отличный инструмент от сообщества, созданный разработчиком Gyptazy, который хорошо известен по другим проектам для Proxmox. Этот проект не стал исключением, и его определенно стоит добавить в список задач для тестирования в Proxmox на выходных. Тестирование ProxPatch в кластере Proxmox из 5 узлов оставило положительные впечатления. Инструмент соблюдал последовательное выполнение задач, корректно справлялся с эвакуацией виртуальных машин и не дестабилизировал работу Ceph, несмотря на то, что данная версия еще не имеет полноценной поддержки (потребовалось предпринять ручные меры предосторожности). Последовательные обновления были завершены без простоев. Как вы в настоящее время управляете обновлениями Proxmox? Является ли это для вас ручным процессом?