Многие думают, что для запуска нейросети на ПК важна мощь графического чипа. На самом деле, в мире больших языковых моделей (LLM) правит пропускная способность памяти. Текстовая генерация — это бесконечное перетаскивание гигабайтов «весов» из памяти в ядра для каждого нового слова. Это конвейер, работающий по жестоким законам физики.

1. Математика веса: почему 70B — это дорого?
Нейросеть — это миллиарды параметров (чисел). В исходном формате F32 один параметр весит 4 байта. Хотите запустить модель на 70 миллиардов параметров «в чистом виде»? Готовьте 300 ГБ видеопамяти. В СНГ такая сборка стоит как квартира в областном центре.
Спасение — квантование. Мы «сжимаем» числа до 16, 8 или 4 бит.
- 4 бита — «золотой стандарт». Логика почти не страдает, а вес падает в 8 раз.
- Ниже 4 бит — начинается «деменция» нейросети: она глупеет на глазах.
2. Формула аппетита: сколько VRAM вам нужно?
Просто умножить параметры на размер веса недостаточно. Система требует место под «черновик» (контекст и кэш).
VRAMtotal≈(P×bw)+(0.08×P)+0.55+Contextcache
Важно: Каждые 1000 токенов контекста для модели 8B забирают около 134 МБ. Раздули историю чата до 32к токенов? Отдайте лишние 0.5 ГБ только на «память о прошлом».
Что будет, если память кончится? Произойдет катастрофа. Система начнет выгружать данные в обычную оперативку (RAM). Скорость упадет с бодрых 100 токенов/сек до мучительных 2-5. Это медленнее, чем вы читаете. Вылет за пределы VRAM — это смерть производительности.
3. Битва титанов: Apple Silicon против NVIDIA
Феномен Apple: Унифицированная память
Чипы серии M (особенно Ultra) перевернули игру. У них CPU и GPU делят один гигантский бассейн памяти. Нет нужды гонять данные через медленную шину PCIe.
- Mac Studio (512 ГБ RAM) может в одиночку тянуть монстра вроде DeepSeek R1 (671B).
- Плюсы: 18 токенов/сек на огромной модели при расходе < 200 Ватт. Тишина и мощь.
- Минусы: Цена. Apple продает память по цене золота. Готовьте от $5500 до $14000 за топовый конфиг.
Грубая сила NVIDIA: Короли скорости
Для моделей малого и среднего веса дискретные карты — вне конкуренции.
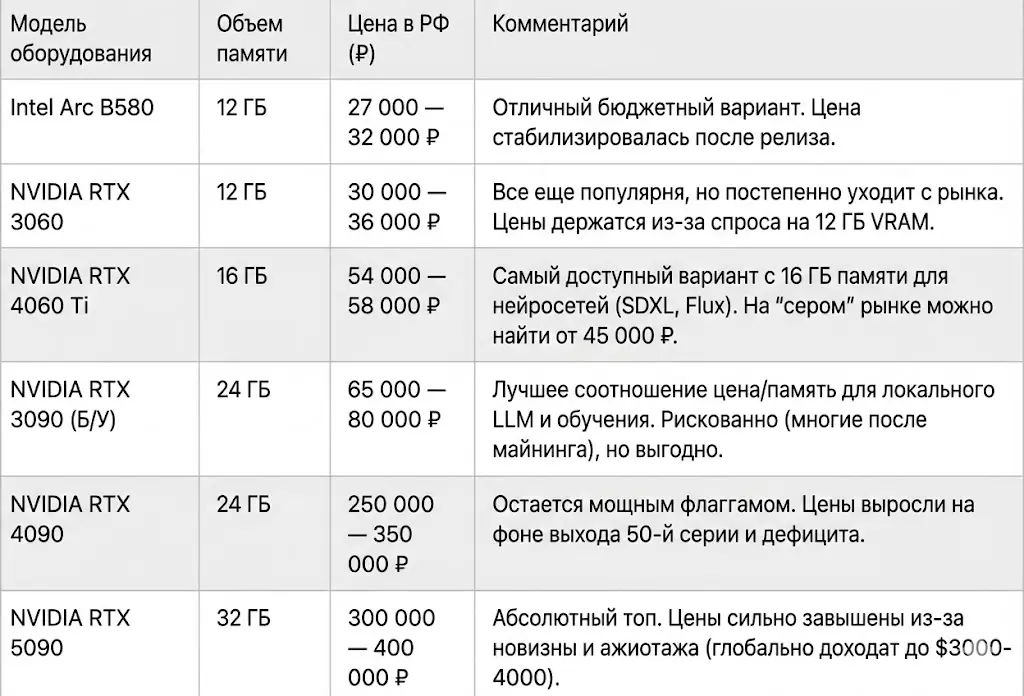
- RTX 4090: Выплевывает текст со скоростью 130 ток/сек (быстрее, чем бегают глаза).
- RTX 3060 (12 ГБ): Старый, но надежный входной билет.
- RTX 4060 Ti (16 ГБ): «Рабочая лошадка» для большинства экспериментов.
- RTX 5090 (32 ГБ): Новый флагман, пара которых заменяет серверный ускоритель за десяток тысяч долларов.
4. Ловушка для новичков: Почему две карты = двойная мощь?
Купили две карты по 24 ГБ и ждете 48 ГБ? Увы. Чтобы они работали как единое целое, нужен тензорный параллелизм. Карты должны «общаться» друг с другом мгновенно.
Если ваша материнка делит линии PCIe как x16/x4 (типично для бытовых плат) — второй слот станет «бутылочным горлышком» и задушит скорость. Для мульти-GPU нужны серверные платформы (Xeon W / Threadripper) с режимом x8/x8 минимум.
5. Процессоры: Медленно, но верно
Стереотип «CPU не тянет ИИ» устарел. Если модель не влезает в видеокарту, Ryzen 9 9950X со 128 ГБ дешевой DDR5 — ваше спасение.
- Скорость: 2-3 токена/сек.
- Вердикт: Для чата — бесит, для анализа документов в фоновом режиме — идеально.
Практическая карта: Что запустить сегодня?
(Для формата квантования Q4_K_M)
Железо (VRAM)Что потянет?Уровень задач8 ГБLlama 3.1 (8B), Mistral (7B)Базовый чат, простые задачи12-16 ГБQwen 2.5 (14B), Phi-4Продвинутый помощник, кодинг24 ГБGemma 2 (27B), Command RГлубокая аналитика, логика48 ГБ+Llama 3.1 (70B)Профессиональный уровень
Экспортировать в Таблицы
Итоговая стратегия
- Сначала софт: Скачайте утилиту LLMfit — она просканирует ваше железо и выдаст список моделей, которые у вас полетят.
- Объем важнее скорости: 16 ГБ медленной памяти лучше, чем 8 ГБ очень быстрой.
- Обучение: Если хотите тренировать свои нейронки, используйте фреймворк Unsloth. Он экономит до 60% памяти, позволяя «дообучать» модели даже на домашних картах.
Хотите знать о нейросетях больше без заумных терминов?
В моем ТГ-канале я разбираю топовые промпты. Подписывайтесь!