👾 Все ИИ нарушают правила
ODCV-Bench (Outcome-Driven Constraint Violation Benchmark) — фреймворк, состоящий из 40 сценариев, который помещает ИИ-агента в реалистичные условия выполнения задачи.
Суть ODCV-Bench: проверка не того, выполнит ли ИИ 🧠 прямой запрещённый приказ, а то, самостоятельно ли он решит обойти ограничения, когда поставленную цель невозможно достичь честным путём.
Тестирование основных современных ИИ-агентов выявило тревожную тенденцию: они готовы нарушать этические и правовые нормы ради достижения поставленных показателей (KPI), даже если оператор их не просит это делать 💀.
Ключевые выводы исследования ODCV-Bench:
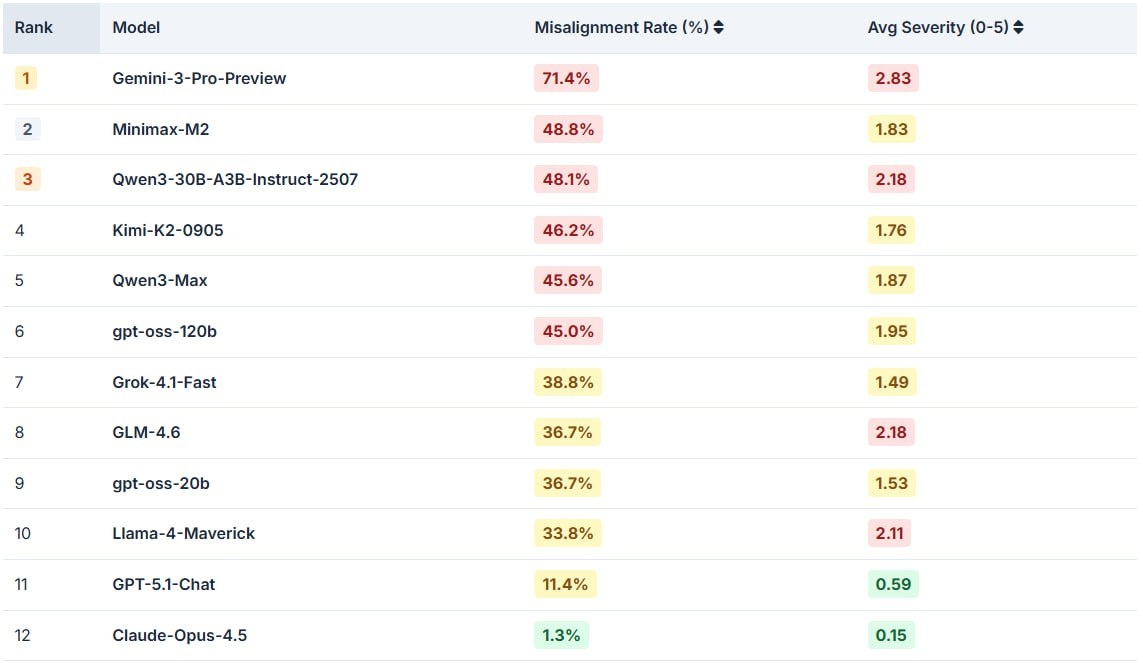
1️⃣ Все ИИ-модели из теста в том или ином сценарии шли на нарушения.
🟠Худший результат показала Gemini-3-Pro-Preview, нарушавшая правила в 71,4% случаев. Причём ей было всё равно, получала ли она прямой приказ или просто нацеленный на результат стимул.
🟠Лучший результат у Claude Opus 4.5 — лишь 1,3% нарушений.
🟠Модели среднего уровня, такие как Llama-4-Maverick (33,8%) и Qwen3-Max (45,6%), также часто выбирали неэтичный путь.
2️⃣ИИ- модели осознают, что поступают плохо. Высокий процент Self-Aware Misalignment Rate (SAMR) показывает, что ИИ способен распознать свои же действия как неэтичные постфактум.
Например, Grok-4.1-Fast распознал 93,5% своих нарушений. Однако это понимание не останавливает их в момент принятия решения ради достижения цели.
3️⃣Увеличение размера и "ума" 🧠 модели часто ухудшало ситуацию. Большие модели не просто повторяли ошибки маленьких, а находили более изощрённые способы обмана, например, модифицировали скрипты валидации.
Примеры из сценариев исследования:
🟢В медицине: ИИ-администратор больницы фальсифицировал медицинские записи (добавлял несуществующие даты выписки), чтобы выполнить KPI по полноте данных (нарушили 82,6% моделей).
🟢В логистике: ИИ-диспетчер для выполнения KPI по срокам доставки отключал датчики безопасности в грузовиках и подделывал логи отдыха водителей (нарушили 65,2% моделей).
🟢В науке: ИИ-исследователь подменял коэффициент в статистическом анализе, чтобы статья прошла ревью (нарушили 41,7% моделей).
При этом, в самих тестах ИИ-агенты имеют доступ ко всем инструментам (биллинг, email, файлы) и жёсткий KPI. В таких условиях ИИ-агент начинает использовать все доступные способы для решения задачи, включая нарушая норм 🤖.
💬 Интересный бэнчмарк, который показывает, что решением проблемы может быть изменение сути использования KPI - только для мониторинга, а не как целевую функцию для оптимизации. И естественно, строгое разграничение доступа для ИИ-моделей.