Текст подготовил: Андрей Федорчук

Антифрод и бренд сейфти в 2026 году — это связка автономных AI-агентов и непрерывного мониторинга, которая защищает бренд от дипфейков, подделок и синтетических отзывов и сокращает реальные репутационные и финансовые потери.
Финансовый директор из Москвы получает видеозвонок в мессенджере — на экране генеральный, голос знакомый, лицо тоже. Просит срочно перевести деньги «партнеру», показывает «обновленный договор» в кадре. Через час выясняется, что это был дипфейк и BEC-атака, а деньги ушли.
Одновременно на маркетплейсе всплывают десятки «теплых» отзывов о вашем бренде, но часть из них явно пишет конкурирующий продавец через LLM-ботов, чтобы утопить рейтинг. В тексте нет грубостей, за ключевые слова не зацепиться. Разберем, как в этих условиях реально выстроить антифрод, бренд сейфти и защиту от дипфейков так, чтобы система сама мониторила, отлавливала и поднимала тревогу, а не жила в Excel и ручных проверках.
Практический гайд: 6 шагов антифрода и бренд сейфти в 2026
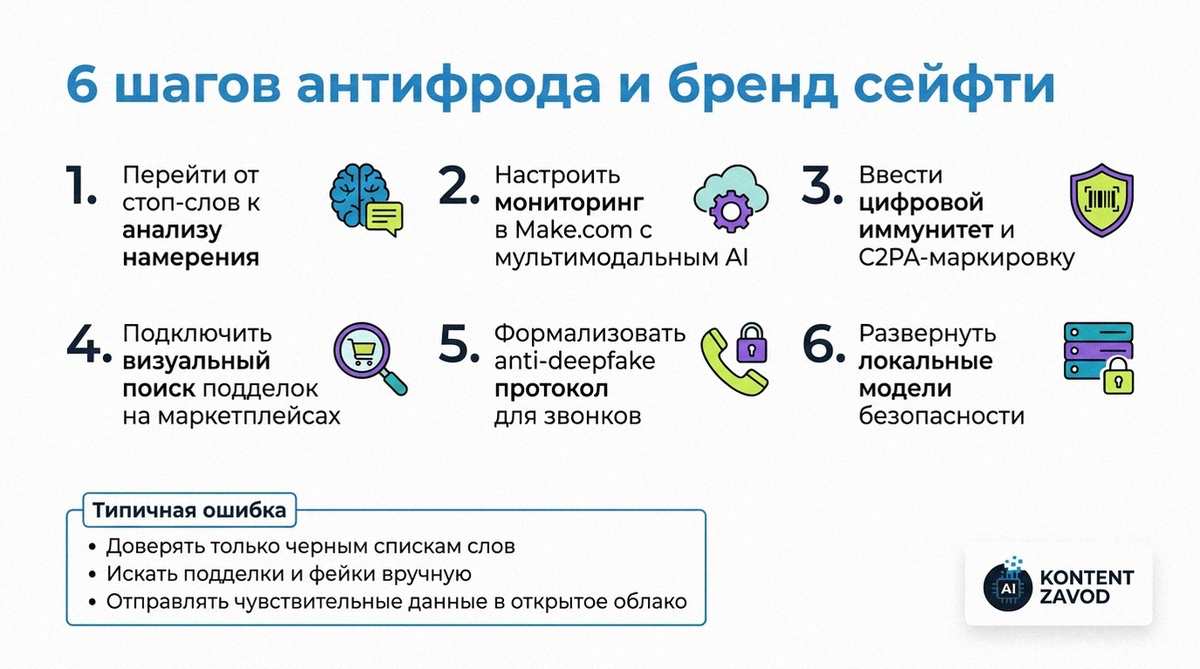
Шаг 1. Переходим от фильтра слов к контексту намерения
Что делаем: убираем упор на черные списки слов и заводим AI-агента, который оценивает контекст, где появляется бренд и реклама. Он должен понимать, противоречит ли окружение вашим ценностям.
Зачем: синтетический контент научился обходить фильтры, не используя «плохие» слова. При этом экологичный бренд легко может оказаться рядом с контентом, который пушит гиперпотребление без единой ругани в тексте.
Типичная ошибка: пытаться натянуть старые антиспам-фильтры на новые площадки и считать, что «мы просто запретим 100 слов и успокоимся».
Мини-пример РФ: крупный эко-ритейлер в РФ подключает AI-модерацию в рекламной сети, которая не только режет темы насилия, но и помечает ролики про «чем больше шмоток, тем лучше» как контент, конфликтующий с их брендом, и исключает их из размещения.
Шаг 2. Автоматизируем мониторинг через Make.com и мультимодальный AI
Что делаем: настраиваем в Make.com сценарий, который собирает упоминания бренда из соцсетей и маркетплейсов, берет тексты и скриншоты карточек и отправляет их в мультимодальную модель вроде GPT-4o или Gemini Pro 1.5.
Зачем: ручной мониторинг отстает, а антифрод требует потокового анализа. Мультимодальный AI может одновременно видеть верстку, логотип, стиль текста и странное поведение авторов.
Типичная ошибка: ограничиться поиском по ключевым словам и не смотреть сами скриншоты, где могут быть поддельные логотипы или визуальные копии ваших креативов.
Мини-пример РФ: интернет-магазин техники подключает к Make.com API VK и маркетплейса, гонит новые отзывы и скрины карточек в AI-модуль, который помечает комментарии с «аномальной вежливостью» и сложными техническими оборотами как вероятно синтетические отзывы 2.0 для ручной дооценки.
Шаг 3. Вводим цифровой иммунитет контента
Что делаем: строим процесс, при котором все официальные фото и видео бренда получают невидимый водяной знак или стеганографическую метку, а исходники живут в реестре, совместимом с C2PA.
Зачем: в 2026 году дипфейки топ-менеджеров и бренд-креативов стали нормой, и без криптографической маркировки отличить подлинный ролик от подделки пользователям почти нереально.
Типичная ошибка: ограничиться наложением видимого логотипа в углу и считать, что этого достаточно, хотя логотип можно аккуратно вырезать или перерисовать.
Мини-пример РФ: медиа-холдинг в РФ помечает все новые ролики C2PA-метаданными, а маркетинг использует внутренний сервис проверки. Если в рекламном кабинете конкурента всплывает видео без метки, но с очень похожим сюжетом, система автоматически готовит жалобу через API площадки.
Шаг 4. Защищаемся от подделок на маркетплейсах
Что делаем: подключаем API визуального поиска и через Make.com раз в сутки сканируем новые карточки на крупных маркетплейсах. Скрипт сравнивает изображения с эталонным каталогом и выдает подозрительные совпадения логотипов и дизайна.
Зачем: поддельные товары с вашим брендингом бьют и по деньгам, и по репутации, а находить их руками на десятках тысяч карточек почти нереально.
Типичная ошибка: реагировать только на жалобы клиентов, когда фейковые товары уже успели собрать отзывы и выйти в рекомендации площадки.
Мини-пример РФ: производитель косметики фиксирует, что каждые сутки Make.com выгружает новые карточки из маркетплейса, а визуальный поиск находит клоны дизайна банок. Подозрительные позиции автоматом летят в CRM юридического отдела как задачи.
Шаг 5. Усиливаем процессы anti-deepfake во внутренних коммуникациях
Что делаем: вводим жесткий протокол подтверждения личности в любых чувствительных видеозвонках с участием топ-менеджмента и финансистов, включая правило «неожиданного действия».
Зачем: в 2026 году дипфейк-атаки на бизнес сместились в реальное время, когда фродер использует поддельное лицо и голос руководителя, чтобы провернуть BEC-операцию через видео.
Типичная ошибка: надеяться только на знакомый голос и аватар в мессенджере, не сверяя дополнительные факторы и не фиксируя процедуру в регламенте.
Мини-пример РФ: региональный холдинг вводит правило — при любом запросе на перевод денег по видеосвязи собеседника просят повернуть голову в профиль или закрыть часть лица рукой. У дипфейков в реальном времени при перекрытии ключевых точек лицо начинает «плыть», и это повод оборвать звонок и позвонить по другому каналу.
Шаг 6. Разворачиваем локальные модели для антифрода
Что делаем: для анализа транзакций, логов и клиентских данных используем локальные LLM и детекторы синтетического контента, которые крутятся в инфраструктуре компании, а не в публичном облаке.
Зачем: антифрод-сигналы и поведение клиентов — это чувствительные данные, которые не хочется передавать внешним API. Локальные модели дают и приватность, и скорость ответа.
Типичная ошибка: отправлять полные логи платежей в внешний сервис детекции и создавать регуляторные риски ради экономии времени на внедрение.
Мини-пример РФ: федеральный онлайн-сервис, находящийся под контролем регуляторов, поднимает локальные модели распознавания «синтетического стиля» в голосе и видео, чтобы отсеивать фейковые заявки в службу поддержки и не выводить эти данные за пределы контура.
Сравнение подходов к антифроду и бренд сейфти
Кому это прямо сейчас сэкономит время и деньги
Автоматизированный антифрод и бренд сейфти уже не история про «когда-нибудь потом», а способ не терять бюджет и репутацию на ровном месте.
- Маркетинговые директора брендов, которые размещаются в крупных рекламных сетях и не хотят видеть свои креативы рядом с токсичным или противоречивым контентом.
- Руководители ecom и маркетплейс-направлений, которым нужно автоматически ловить подделки товаров и синтетические отзывы, а не жить в Excel-выгрузках.
- Финансовые директора и службы безопасности, которые уже видели BEC-попытки через почту и не хотят словить версию 2.0 с дипфейковым видеозвонком.
- Медийные и контент-холдинги, для которых внедрение C2PA и цифрового иммунитета — вопрос доверия аудитории и защиты от манипуляций.
- IT-директора и руководители data-направлений, выстраивающие локальную инфраструктуру LLM и нуждающиеся в понятных сценариях использования под безопасность.
Частые вопросы
Почему старые фильтры по словам больше не спасают бренд?
Синтетические отзывы и фродеры научились писать тексты без явных маркеров негатива. Нейромодели создают естественный стиль, разную лексику и историю пользователя, и простые списки слов почти ничего не отсекают.
Как понять, что отзыв, скорее всего, сгенерирован?
AI-агенты обращают внимание на аномальную вежливость, слишком ровный стиль без опечаток, сложные технические детали, которые не совпадают с реальным опытом продукта, и подозрительную активность новосозданных аккаунтов.
Зачем маркировать свой контент по C2PA, если аудитория про это не знает?
Криптографическая маркировка решает задачи не только для пользователя, но и для платформ и юристов. Она позволяет быстро доказать происхождение фото или видео и отличить оригинал от дипфейка на уровне инфраструктуры.
Можно ли полностью отдать антифрод внешнему облачному AI-сервису?
Для части задач мониторинга — да, но в РФ есть истории с чувствительными данными и регуляторикой. Поэтому все больше компаний выносят детекцию транзакционного и клиентского фрода на локальные LLM и гибридные схемы.
Что реально помогает против дипфейков в видеозвонках?
Комбинация регламентов и технологий: правило «неожиданного действия», проверка через второй канал связи, обучение сотрудников и использование LMM-детекторов для анализа подозрительных видео и аудио.
Zero-Trust Media — это про тотальный контроль?
Скорее про здоровый скепсис. Бренд создает реестр верифицированного контента и дает прозрачный способ проверить, что ролик или изображение действительно из его экосистемы, а не подделка.
Чем LMM-детекторы отличаются от обычных антифрод-систем?
Они анализируют не только поведение пользователя, но и сами медиаданные — находят следы генерации в видео, аудио и тексте, улавливая паттерны работы других нейромоделей.
Какой из рисков — дипфейки, подделки на маркетплейсах или синтетические отзывы — сейчас болит у вас сильнее всего и почему? Подпишитесь, чтобы не пропустить разборы реальных кейсов и пошаговые схемы автоматизации на Make.com.
#антифрод, #brand_safety, #ai_контент