RAG не работает так, как ожидалось
В топе выдачи странные документы, а действительно релевантные находятся где-то на 10–15 месте
Часто проблема не в данных и не в эмбеддингах. Проблема в ранжировании.
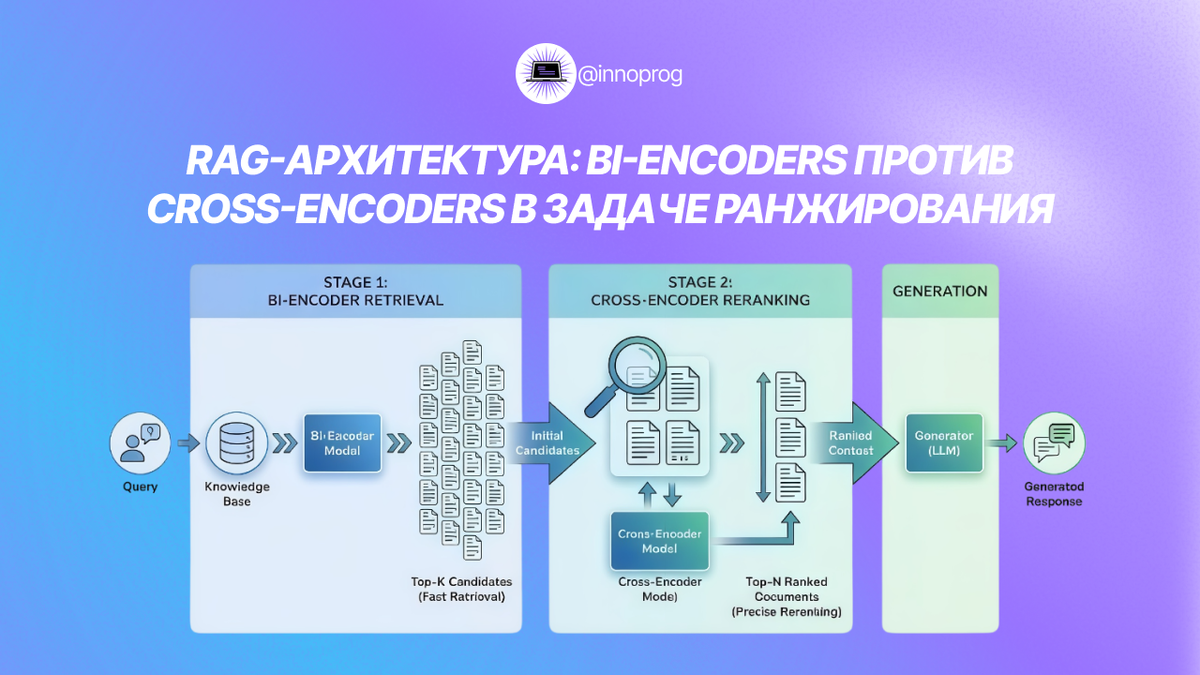
Большинство RAG-систем используют bi-encoder. Он кодирует запрос и документы отдельно и сравнивает их по косинусному сходству. Это быстро и масштабируется на миллионы документов. Но модель не видит запрос и документ вместе, поэтому путается в нюансах.
✅Похожие слова не равны похожему смыслу
Ошибка 404 != ошибка 500.
Java backend != JavaScript frontend.
Увеличить продажи != рост выручки.
Bi-encoder отлично находит тексты «про то же самое», но часто не понимает контекст.
Когда важна точность, добавляют cross-encoder. Он получает запрос и документ одновременно и оценивает их связку. Качество растёт заметно. По бенчмаркам разница может достигать 15–20% в точности топ-10.
Минус в том, что это медленнее. Поэтому в продакшене чаще используют гибридный подход. Сначала bi-encoder находит кандидатов. Затем cross-encoder переранжирует только их. Баланс скорости и качества.
📌Подробный разбор с примерами, моделями и практическими рекомендациями по настройке в полной версии статьи по ссылке: https://colab.research.google.com/drive/1FImu7HXSeNsMNfJQyrFr72X2Vn1vcF8J?usp=sharing