🚀🔬 zembed-1 — open-weight эмбеддинг-модель на 4B параметров, обходящая OpenAI и Cohere в финтехе и праве
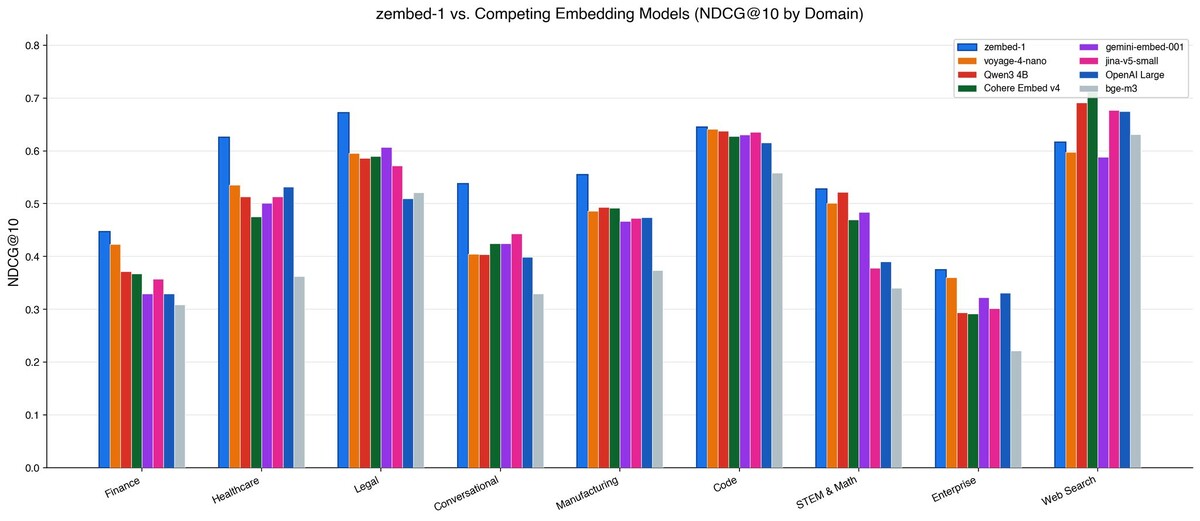
zembed-1 — это новая SOTA-модель для генерации векторных представлений текста, построенная на базе Qwen3-4B. Разработчики из ZeroEntropy применили метод zELO (моделирование релевантности как рейтинга Эло), что позволило дистиллировать знания из мощного реранкера и превзойти проприетарные решения вроде OpenAI text-embedding-large и Cohere Embed v4.
Модель специально затачивалась под сложные домены: финансы, юриспруденцию, медицину и кодинг. При контекстном окне в 32k токенов она показывает лучшие результаты в задачах поиска по специфическим документам, где общие модели часто «плывут». Это делает её идеальным кандидатом для RAG-систем (Retrieval-Augmented Generation — поиск документов для контекста LLM) в корпоративном секторе.
Гибкость — главная фишка архитектуры: поддерживаются проекции размерности от 2560 до 40 и бинарное квантование. Это позволяет сжать вектор с 8 КБ до 128 байт почти без потери точности, что КРИТИЧЕСКИ важно для скорости поиска по миллионам документов. Модель мультиязычная, и более половины обучающих данных — не английский язык.
Запустить можно через sentence-transformers всего парой строк кода. Модель доступна на Hugging Face под лицензией CC-BY-NC-4.0 (бесплатно для некоммерческого использования). Для финтех-стартапов и внутренних инструментов это возможность получить качество уровня GPT-4 на собственном железе.
#AI #RAG #OpenSource #Qwen3