
Представьте, что вы детектив. У вас есть доска, на которую вы прикалываете фотографии подозреваемых и соединяете их ниточками: «знаком», «был на месте преступления», «имеет мотив». Именно так вы видите картину преступления — не как список фактов, а как паутину отношений.
Обычные базы данных (SQL и даже многие NoSQL) плохо справляются с такими «ниточками». Они могут хранить связи, но чем их больше, тем медленнее работают запросы. А если нужно пройти по цепочке связей («друзья друзей друзей»), производительность падает катастрофически.
Графовые базы данных созданы именно для этого. В них связи между данными так же важны, как и сами данные, и хранятся они наравне с записями. Это позволяет проходить по цепочкам связей за миллисекунды, независимо от их длины.
В 2026 году графы перестали быть экзотикой. Они используются в соцсетях, рекомендательных системах, борьбе с мошенничеством, управлении сетями и даже в науке. Давайте разберёмся, какие графовые базы существуют и как выбрать подходящую.
Часть 1: Когда данные — это связи?
Прежде чем погружаться в технологии, давайте поймём, где графы незаменимы.
Задача 1: Социальные сети и рекомендации
- Пример: Показать друзей друга, рекомендовать новых знакомых, найти общие интересы.
- Почему граф: Здесь всё — связи между людьми, группами, контентом. SQL-запросы с множеством JOIN становятся неподъёмными.
Задача 2: Борьба с мошенничеством (Fraud detection)
- Пример: Выявить мошенническую сеть: один паспорт, много сим-карт, переводы между подозрительными счетами.
- Почему граф: Мошенничество часто выглядит как паттерн связей, который легко найти графовым алгоритмом (например, поиск колец или кластеров).
Задача 3: Управление сетями и зависимостями
- Пример: IT-инфраструктура: серверы, приложения, базы данных, их зависимости. При падении одного узла нужно понять, кого это затронет.
- Почему граф: Это естественная модель для любых сетей.
Задача 4: Рекомендательные системы
- Пример: Amazon рекомендует товары: «те, кто купил это, также купили то».
- Почему граф: Связи «пользователь-товар», «товар-товар» легко обходятся.
Задача 5: Биоинформатика и наука
- Пример: Белковые взаимодействия, генные сети, цитирования статей.
- Почему граф: Сложные взаимосвязи в данных.
Часть 2: Основные понятия графовых БД (для новичков)
Чтобы понимать дальше, нужно освоить три термина:
- Узел (Node/Vertex): Сущность. Например, человек, компания, товар, страница.
- Ребро (Edge/Relationship): Связь между узлами. Например, «ДРУЖИТ», «КУПИЛ», «ПЕРЕВЁЛ».
- Свойства (Properties): Атрибуты узлов и рёбер. У человека — имя, возраст; у связи «КУПИЛ» — дата покупки, сумма.
Главное отличие от SQL: связи не вычисляются на лету через JOIN, а хранятся как указатели. Пройти от узла к узлу по рёбрам — операция константной сложности.
Часть 3: Навигатор по графовым БД 2026
Рассмотрим основных игроков на рынке.
Решение 1: Neo4j — «Король графов»
- Тип: Нативная графовая БД (хранит данные как граф с самого начала).
- Язык запросов: Cypher (декларативный, похож на SQL, но для графов).
- Плюсы:
- Самая зрелая и популярная графовая БД. Огромное комьюнити, много обучающих материалов.
- Мощный язык запросов Cypher, который легко учить.
- Есть облачная версия (AuraDB), enterprise-функции (кластеризация, безопасность).
- Поддержка ACID-транзакций.
- Богатая экосистема инструментов (Neo4j Browser, Bloom для визуализации).
- Минусы:
- Тяжеловата для распределённых сценариев (шардинг не нативный, требует ручной настройки).
- Не всегда эффективна при очень больших объёмах данных (терабайты+).
- Лицензирование: Community Edition бесплатна, но Enterprise платная.
- Идеален для: Большинства классических графовых задач, особенно в корпоративной среде, где нужна надёжность и поддержка.
Решение 2: Dgraph — «Граф для облака и горизонтального масштабирования»
- Тип: Распределённая графовая БД, спроектированная для горизонтального масштабирования с рождения.
- Язык запросов: GraphQL+- (диалект GraphQL).
- Плюсы:
- Отличная масштабируемость: данные автоматически шардируются, можно добавлять узлы кластера без простоя.
- Высокая производительность на запросах.
- Поддержка ACID-транзакций (на уровне одного узла, распределённые транзакции ограничены).
- Нативный API через GraphQL, что удобно для современных веб-приложений.
- Open source (Apache 2.0).
- Минусы:
- Меньше комьюнити и обучающих материалов, чем у Neo4j.
- Язык запросов GraphQL+- специфичен, не так интуитивен, как Cypher.
- Визуализация и инструменты слабее.
- Идеален для: Проектов, где нужна горизонтальная масштабируемость с самого начала, и команда уже использует GraphQL.
Решение 3: Amazon Neptune — «Управляемый граф от AWS»
- Тип: Полностью управляемый сервис графовых БД в облаке AWS.
- Языки запросов: Поддерживает два стандарта: Gremlin (Apache TinkerPop) и SPARQL (для RDF-графов).
- Плюсы:
- Полностью managed: не нужно администрировать серверы, резервное копирование, patching.
- Высокая доступность и надёжность (как у всех сервисов AWS).
- Поддержка ACID-транзакций.
- Интеграция с другими сервисами AWS (IAM, CloudWatch, KMS).
- Можно использовать Gremlin (популярный в Java-мире) или SPARQL (для семантических графов).
- Минусы:
- Привязанность к AWS (vendor lock-in).
- Может быть дороже self-hosted решений при больших объёмах.
- Ограниченная гибкость конфигурации (что типично для managed-сервисов).
- Нет собственного языка запросов, приходится учить Gremlin/SPARQL.
- Идеален для: Команд, уже использующих AWS, которые хотят получить графовую БД без головной боли с администрированием.
Решение 4: Другие игроки (ArangoDB, OrientDB, JanusGraph)
- ArangoDB: Мультимодельная БД (документы + графы + ключ-значение). Удобна, если нужна гибкость. Есть собственный язык запросов AQL.
- OrientDB: Тоже мультимодельная, с поддержкой графов и документов. Была популярна, но сейчас уступает Neo4j.
- JanusGraph: Распределённая графовая БД, построенная поверх Cassandra/HBase и индексатора (Elasticsearch/Solr). Сложна в настройке, но масштабируется. Используется в крупных проектах (например, в некоторых компонентах Uber).
Часть 4: Сравнение по ключевым критериям
Критерий: Модель данных и зрелость
- Neo4j: Нативный граф, самая зрелая.
- Dgraph: Нативный граф, но моложе.
- Amazon Neptune: Нативный граф, зрелая инфраструктура AWS.
- ArangoDB: Мультимодельная, зрелая.
Критерий: Язык запросов
- Neo4j: Cypher (простой, декларативный).
- Dgraph: GraphQL+- (удобен для GraphQL-разработчиков).
- Amazon Neptune: Gremlin (императивный/функциональный) или SPARQL.
- ArangoDB: AQL (свой, похож на SQL + JSON).
Критерий: Масштабирование
- Neo4j: Вертикальное (один большой сервер) или кластер с репликацией чтения. Шардинг сложный.
- Dgraph: Горизонтальное, автоматическое шардирование.
- Amazon Neptune: Горизонтальное, но управляется AWS.
- JanusGraph: Горизонтальное, но сложно в настройке.
Критерий: Облачные managed-сервисы
- Neo4j: AuraDB (Neo4j as a Service).
- Dgraph: Есть Dgraph Cloud (beta/early access).
- Amazon Neptune: Полноценный managed-сервис AWS.
- ArangoDB: ArangoDB Cloud (Oasis).
Критерий: Open Source
- Neo4j: Community Edition (GPLv3), Enterprise (коммерческая).
- Dgraph: Полностью open source (Apache 2.0).
- Amazon Neptune: Проприетарный.
- ArangoDB: Community (Apache 2.0), Enterprise (коммерческая).
Часть 5: Карта выбора: какая графовая БД подходит вам?
Задайте себе несколько вопросов:
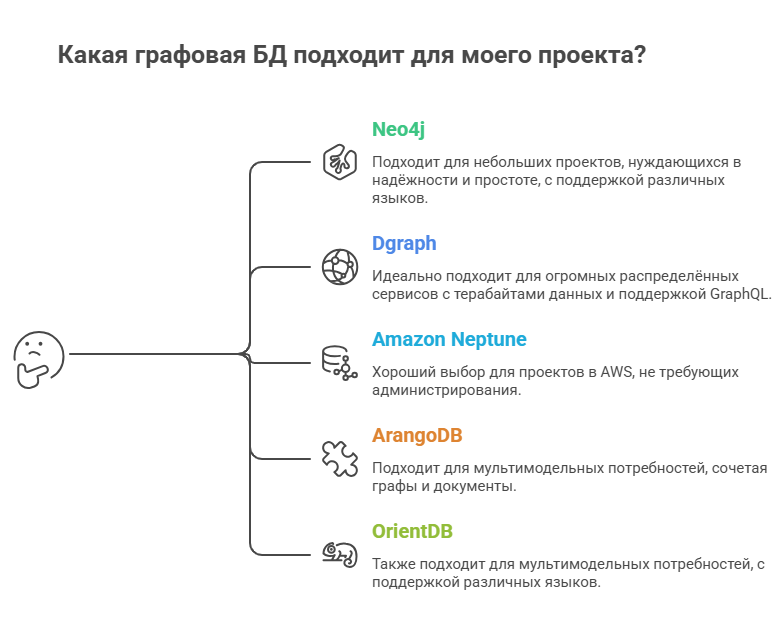
Часть 6: Тренды 2026 в мире графовых БД
- Графы становятся стандартом для аналитики связей. Всё больше компаний осознают ценность связей и внедряют графовые БД рядом с основными хранилищами.
- SQL-поддержка графов (SQL/PGQ). Стандарт SQL:2023 включил Property Graph Queries. Это значит, что реляционные БД (Oracle, PostgreSQL) начинают нативно поддерживать графовые запросы. Пока сыро, но тренд задан.
- Графовые ML-алгоритмы. TensorFlow, PyTorch и другие интегрируются с графовыми БД для обучения на связях (Graph Neural Networks).
- Визуализация становится ключевой. Инструменты типа Neo4j Bloom, Keylines, Linkurious помогают бизнес-пользователям видеть данные, а не просто запрашивать.
Итог: Графы — это не замена SQL, а дополнение
Графовые базы данных не вытесняют реляционные. Они закрывают те задачи, где связи — это главное. В сложных системах они часто работают в связке: транзакции в PostgreSQL, аналитика связей в Neo4j, масштабируемые графы в Dgraph.
Если ваши данные похожи на паутину — смело смотрите в сторону графов. Если же они хорошо ложатся в таблицы и связи неглубокие — оставайтесь в SQL.
А вы работали с графами?
Поделитесь опытом в комментариях:
- В каких проектах вы использовали графовые БД? Что это дало?
- С какими проблемами столкнулись при внедрении?
- Какую БД выбрали и почему?
Обсудим реальные кейсы — это поможет новичкам не наступать на те же грабли.
**P.S. Подписывайтесь на «Навигатор по миру IT». В следующем выпуске разберём NewSQL 2026: базы данных, которые хотят быть одновременно и SQL, и NoSQL. CockroachDB, YugabyteDB, TiDB — что выбрать для глобальных приложений?