Текст подготовил: Андрей Федорчук

Мультимодальные модели в маркетинге — это нейросети, которые одновременно работают с текстом, картинками и видео и завязаны в одну продакшн-цепочку. Их польза в том, что они сокращают время создания контента на 60-80% и позволяют строить сквозные воронки от анализа ролика до готовых креативов.
Типичная картина в российском маркетинге: команда неделями рожает один курс или вебинар, потом еще неделю делает лендинг, креативы, серию писем. Видео отдельно, тексты отдельно, баннеры отдельно — всё держится на людях, а не на системе.
В 2024-2025 годах у тех, кто уже перевел это на мультимодальные модели, продакшн работает иначе: записали один вебинар, ИИ разобрал видео, превратил его в статью, выжал тезисы для соцсетей, сгенерировал обложки и даже видео-аватары для рассылок. Ниже разберем, как собрать такую связку на базе GPT-4o, Gemini, Claude и Make.com, какие варианты есть под РФ и где бренды сейчас теряют деньги.
6 шагов внедрения мультимодального ИИ в маркетинг
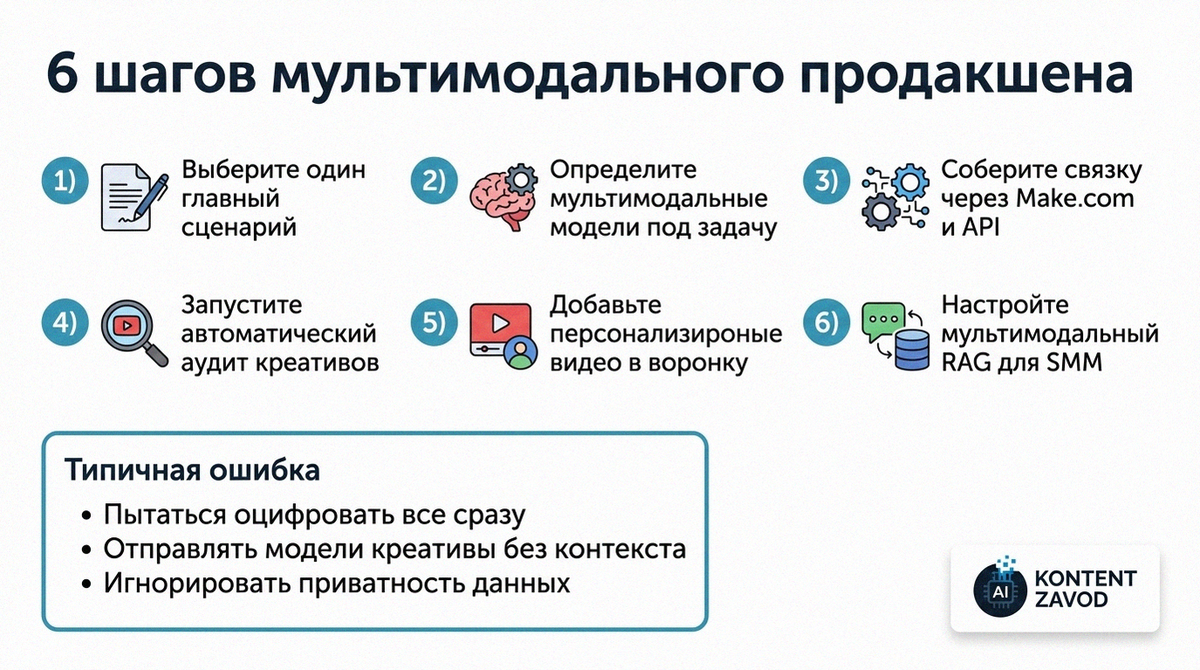
Шаг 1. Определяем один главный мультимодальный сценарий
Что делаем: выбираем не абстрактный «маркетинг с ИИ», а один конкретный поток, который реально болит. Чаще всего это реперпозинг: видео — текст — визуал или автоматический аудит креативов.
Зачем: чтобы не собрать зоопарк нейросетей без эффекта на выручку и сразу увидеть экономию по времени и продакшн-бюджету.
Типичная ошибка: пытаться покрыть всё сразу — и SMM, и блог, и рассылки, и рекламу. В итоге сценарии не доводятся до продакшна, всё остается на уровне «поигрались».
Пример РФ: онлайн-школа по маркетингу в Москве берет главный актив — еженедельные YouTube-вебинары — и ставит задачу: из каждого выпуска автоматически получать статью в блог, 5 постов для VK/Telegram и обложки.
Шаг 2. Выбираем мультимодальные модели под задачу
Что делаем: решаем, кто у нас будет «мозгом» для текста и анализа визуала. Для сложных сценариев это связки GPT-4o, Gemini 1.5 Pro или Claude 3.5 Sonnet, для приватных данных — локальные Llava или Qwen-VL на своих серверах.
Зачем: чтобы модель могла и прочитать видео/картинку, и выдать внятный текст под маркетинговые цели, а не просто описать картинку в стиле «на изображении сидит человек».
Типичная ошибка: брать одну модель «по совету друга» и пытаться через неё решать всё, от юридических текстов до видео-рекламы, не тестируя качество именно на своих форматах.
Пример РФ: e-commerce в Санкт-Петербурге держит бренд-буки и каталоги только on-premise, поэтому часть воронки (аудит баннеров) делает через локальный Qwen-VL, а генерацию текстов и идей для креативов — через Claude 3.5 в облаке.
Шаг 3. Собираем связку в Make.com через API
Что делаем: строим сценарий в Make.com, который реагирует на событие и протаскивает данные через мультимодальные модели. Классический поток: новое видео на YouTube — транскрибация через Whisper — обработка текста в Claude 3.5 — генерация обложек в Midjourney или DALL-E 3.
Зачем: чтобы всё происходило без ручного копипаста между сервисами и файлами. Один триггер — несколько выходов: статья, соцсети, обложки.
Типичная ошибка: делать слишком монолитный сценарий, куда впихнуты все ветки, вместо нескольких простых сценариев по одному результату.
Пример РФ: региональное агентство из Казани настраивает в Make.com сценарий «новое видео на YouTube бренда бытовой техники» — дальше Whisper снимает речь, Claude 3.5 пишет инструкцию в блог и 5 коротких подсказок для Telegram-канала, а DALL-E 3 генерирует серию визуалов по ключевым тезисам.
Шаг 4. Настраиваем автоматический аудит креативов
Что делаем: подключаем к Make.com папку в Google Drive или Dropbox, куда дизайнеры складывают баннеры. Каждый новый файл уходит в GPT-4o Vision с промптом на оценку по гайдлайнам бренда и генерацию 3 заголовков для A/B-теста.
Зачем: чтобы быстро отбраковывать визуалы, которые не бьют по тону бренда или плохо читаются в ленте, не гоняя всё через арт-директора вручную.
Типичная ошибка: отправлять в модель баннер без контекста — без описания целевой аудитории, оффера и площадки. В ответ приходит абстрактная оценка, а не реальный разбор под задачу.
Пример РФ: fintech-сервис из Новосибирска подключает GPT-4o Vision к папке с баннерами для Яндекс Директ. Модель проверяет цвет, читаемость оффера и запрашиваемое действие и сразу предлагает 3 варианта заголовка под A/B-тест.
Шаг 5. Включаем персонализированные видео в воронку
Что делаем: интегрируем CRM (например, HubSpot) с HeyGen или Tavus через Make.com. При появлении нового лида триггер создает персональное видео, где ИИ-аватар обращается по имени и упоминает компанию клиента.
Зачем: чтобы повышать конверсию в первом касании и экономить на студийных съемках. Такой формат особенно полезен для B2B-продаж и дорогих услуг.
Типичная ошибка: генерировать одинаковые скрипты для всех сегментов, меняя только имя. Итог — ощущение «массовой рассылки» и выгорание базы.
Пример РФ: SaaS-сервис для застройщиков в Екатеринбурге шлет новым лидам видео, где ИИ-аватар на русском языке приветствует по имени, называет город и тип компании (девелопер, агентство), а затем предлагает демо.
Шаг 6. Добавляем мультимодальный RAG под SMM и аналитику
Что делаем: собираем в векторную базу описания прошлых успешных постов, роликов и картинок. При подготовке нового контента ИИ сначала ищет, что уже приносило результат, и подсказывает идеи по визуалу и структуре.
Зачем: чтобы не придумывать темы и стили с нуля и опираться не на вкусы команды, а на фактическую историю кампаний.
Типичная ошибка: складывать в базу только текст без связки с визуалом и площадкой. Тогда модель не видит, как картинка и платформа влияли на результат.
Пример РФ: SMM-отдел крупного розничного бренда в России хранит описания лучших Instagram и VK постов с ссылками на визуалы. При создании нового анонса распродажи ИИ подбирает похожие по механике кампании и предлагает формат, цвета и тип баннера.
Какие мультимодальные модели выбрать под продакшн
Кому мультимодальный ИИ реально экономит ресурсы
Мультимодальные нейросети и автоматизация через Make.com особенно полезны тем, у кого продакшн уже захлебывается в задачах, а нанимать новую команду дорого и долго.
- Онлайн-школы и продюсерские центры, которые постоянно снимают вебинары и курсы и хотят выжимать из них максимум форматов без ручной рутины.
- Бренды e-commerce и ритейла, где каждый месяц нужно обновлять сотни баннеров, видео и рассылок под акции и распродажи.
- B2B-сервисы и SaaS, которым важно персонализированное первое касание — видео-приглашения, онбординг, обучающие ролики.
- Агентства performance и SMM, которым нужно масштабировать тесты креативов, но нет ресурса держать большую команду креативщиков и медиапланеров.
- Компании с жесткими требованиями по безопасности данных, которые готовы вложиться в локальные мультимодальные модели ради полного контроля.
Частые вопросы
С чего начать, если у нас еще нет Make.com и моделей?
Начните с одного сценария: реперпозинг YouTube-видео в статью и посты. Подпишите аккаунты в одном из мультимодальных сервисов (GPT-4o, Gemini или Claude 3.5), подключите бесплатный или тестовый тариф Make.com и соберите минимальный сценарий из триггера, транскрибации и генерации текста.
Какие задачи лучше всего отдать мультимодальным моделям в маркетинге?
Анализ и переработка видео в текст, генерация статей и постов из вебинаров, автоматический аудит визуальных креативов по гайдлайнам бренда, подбор идей и заголовков для A/B-тестов, создание персонализированных видео через сервисы вроде HeyGen или Tavus.
Не убивает ли это креативность команды маркетинга?
На практике мультимодальные нейросети снимают рутину — транскрибацию, переразметку, адаптацию под площадки. Люди продолжают решать, какой месседж и позиционирование брать, а ИИ помогает быстрее прогонять гипотезы и упираться в стратегические задачи, а не в продакшн.
Как быть с юридическими рисками и данными клиентов из РФ?
Критичные данные клиентов не нужно отправлять в облачные модели. Для таких кейсов лучше использовать локальные мультимодальные решения вроде Llava или Qwen-VL на собственных серверах, а внешние сервисы подключать только к обезличенному контенту и открытым материалам.
Сколько времени занимает первое внедрение в маркетинговом отделе?
Если не пытаться оцифровать весь маркетинг сразу, а начать с одного сценария, рабочий прототип часто собирается за 1-2 недели: пара дней на выбор моделей, несколько дней на сценарии в Make.com и еще пару итераций тестов и доработок промптов.
Можно ли обойтись без видео и работать только с текстом и картинками?
Можно, но главный выигрыш мультимодальных моделей как раз в том, что они связывают видео, текст и визуал в одну воронку. Если видео уже есть или его легко снять, имеет смысл строить поток «Видео — Текст — Визуал» и масштабировать контент из одного источника.
Что делать, если команда боится автоматизации и сопротивляется ИИ?
Начните с задач, которые все и так не любят: транскрибация, верстка однотипных обложек, подготовка вариантов заголовков. Когда команда увидит, что время освобождается под более интересные проекты, сопротивление обычно быстро падает.
Какой мультимодальный сценарий в вашем маркетинге сейчас самый больной — реперпозинг видео, аудит креативов или персонализация? Напишите, что уже пробовали, и подписывайтесь, чтобы не пропустить разборы рабочих связок Make.com + ИИ под рынок РФ.
#маркетинг, #нейросети, #автоматизация
AI kontent Zavod:
Связаться с Андреем
Email
Заказать Нейро-Завод
Нейросмех YouTube
Нейроновости ТГ
Нейрозвук ТГ
Нейрохолст ТГ