
Многие до сих пор думают, что ChatGPT или Claude - это просто эдакий супер-Google, огромная база знаний, где лежат готовые ответы на все вопросы. Спойлер: это совершенно не так.
Сегодня мы заглянем под капот искусственного интеллекта. Я расскажу, как на самом деле «думают» большие языковые модели (LLM). Вы узнаете, почему ИИ так быстро расходует лимиты, особенно если вы пишете промпты на русском языке, генерируя контент для Telegram-канала или собирая структуру для ИИ-презентации.
🤖 Искусственный интеллект - это предсказатель, а не энциклопедия
Современная нейросеть (LLM) - это высокопроизводительный вероятностный движок предсказания следующего токена.
Представьте, что вы играете в игру «Угадай слово». Ведущий говорит начало фразы, а вы автоматически подставляете окончание. Нейросеть делает абсолютно то же самое миллиарды раз в секунду. Она не знает фактов, она математически вычисляет вероятность того, какой элемент текста должен идти следующим.
🧩 Токенизация: атомы смысла и «налог на кириллицу»
Люди читают по буквам и словам. Нейросети оперируют не текстом, а токенами - числовыми идентификаторами фрагментов слов. Модель не видит само слово, она видит лишь его цифровой код.
(Здесь отлично подойдет картинка с примером перевода текста в цифры. Рекомендуемый Alt-тег: Процесс токенизации текста в языковых моделях)
И тут кроется главная ловушка для бюджета. Поскольку обучающие датасеты ИИ преимущественно англоцентричны, русский текст дробится на гораздо более мелкие фрагменты.
- В английском языке 1 слово - это чаще всего 1 токен.
- В русском языке 1 слово дробится на 2-3 мелких токена.
Что это значит на практике?
Коэффициент токенизации для кириллицы составляет 1.5-2x относительно английского. Например, контекстное окно в 128 тысяч токенов вмещает ~250 страниц английского текста, а для русского - всего около 120.
Все популярные API (OpenAI, Anthropic) тарифицируют именно токены. Неэффективная токенизация напрямую увеличивает TCO (Total Cost of Ownership) вашей системы. Если вы описываете сложную сцену для генерации 3D-логотипа на русском, вы платите в полтора-два раза больше вычислительных ресурсов, чем за тот же запрос на английском.
🔍 Как нейросеть понимает суть? Магия механизма «Внимание»
Как машина понимает контекст? Механизм Self-attention (самовнимание) позволяет языковой модели вычислять веса связей между токенами.
Давайте на примере фразы:
«Сеньор-разработчик посмотрел на код, он сломался».
Кто сломался? Разработчик от дедлайнов или код от бага? Вычисляя веса слов, модель понимает, что «он» - это именно «код».
В современных архитектурах используется Multi-head attention - параллельный анализ данных. Это похоже на процесс проверки кода (Code Review):
- Одна «голова» проверяет синтаксические связи.
- Вторая - анализирует логику и типы данных.
- Третья - следит за условиями задачи.
Результаты склеиваются, формируя глубокое понимание вашего промпта.
⏱ Генерация текста: почему ИИ иногда отвечает медленно
Процесс обработки запроса (Inference) делится на два этапа. Они радикально отличаются по архитектуре вычислений:
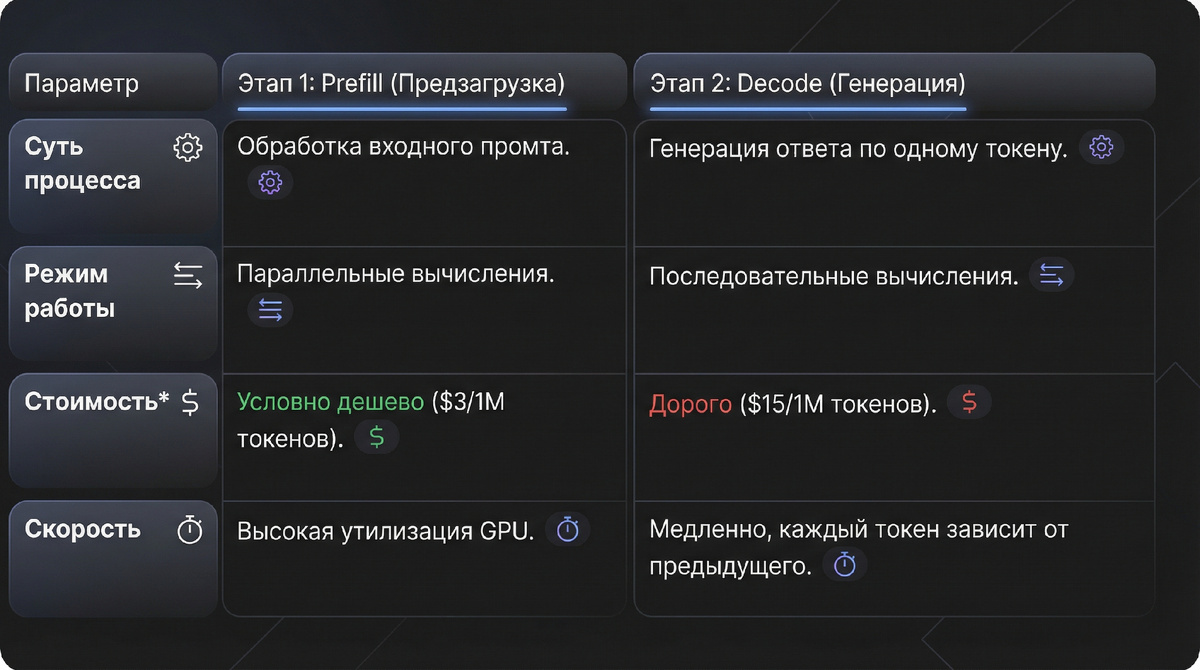
Именно поэтому вы видите, как текст печатается на экране по буквам. Нейросеть физически не может выдать весь ответ за одну секунду - каждый следующий токен должен быть сгенерирован с опорой на предыдущий.
🤖 Хотите заставить нейросети работать на вас, а не просто играться с запросами? Больше прикладных разборов, скрытых механик и готовых промптов - в моем Telegram-канале [PRO AI]. Там регулярно учу внедрять ИИ в реальные задачи, автоматизировать рутину и перестать сливать бюджет на неэффективные подписки.
Подписывайтесь прямо сейчас, чтобы не пропустить следующий пост из рубрики «Анатомия нейросетей» про инженерию контекста! 👇