В данной статье мы рассмотрим несколько известных (и не только) методов градиентной оптимизации.
Данные методы применяются в машинном и глубоком обучении.
Пару слов про функции потерь
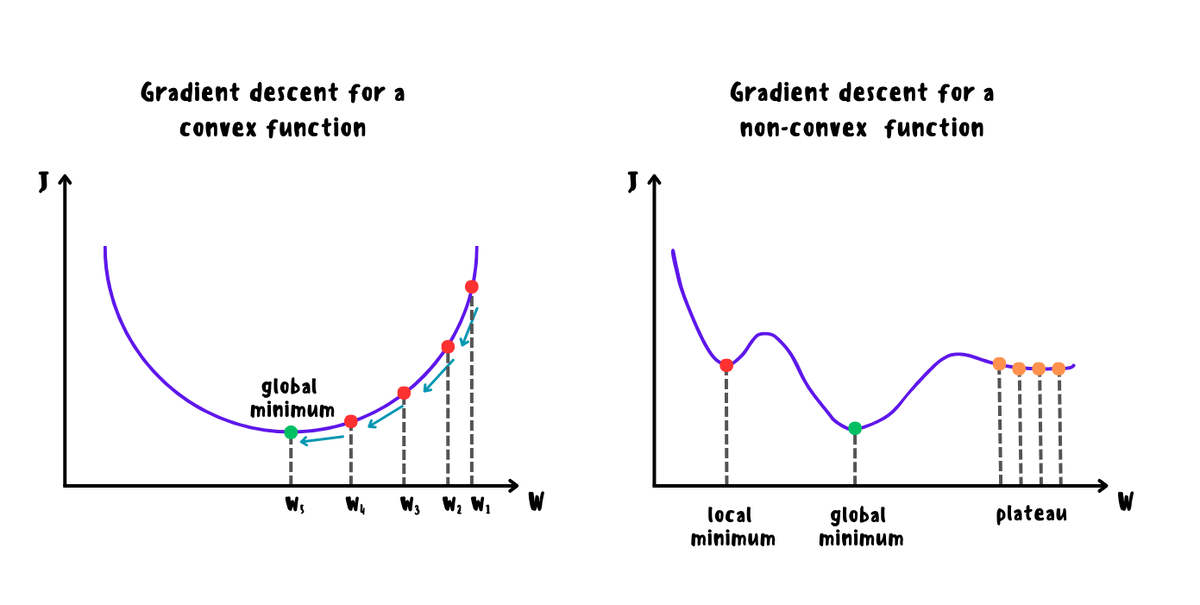
Функции потерь можно разделить на выпуклые и невыпуклые. Первый вариант чаще всего встречается в классическом машинном обучении из-за относительной простоты моделей, а также из-за того, что у выпуклых функций локальный минимум по определению является и глобальным (но не обязательно единственным). Невыпуклые функции, в свою очередь, чаще всего встречаются в нейронных сетях из-за их высокой сложности и в данном случае поиск глобального минимума является трудной задачей, поэтому на практике здесь также используются методы из случая с выпуклыми функциями из-за их способности хорошо аппроксимировать стационарные точки в невыпуклом случае. Проще говоря, методы для выпуклого случая могут хорошо сходиться в локальном оптимуме для невыпуклого случая за приемлемое время, значение которого близко к глобальному.
Классический градиентный спуск
Начнём с того, что если градиент — это вектор наибыстрейшего возрастания функции, то антиградиент — вектор наибыстрейшего убывания, и именно при движении в данную сторону будет расположена минимальная ошибка модели. Тогда градиентный спуск можно определить как численный метод итеративной оптимизации для нахождения весов (коэффициентов) модели путём минимизации её ошибки, представленной в виде функции потерь.
Алгоритм строится следующим образом:
- изначально происходит инициализация весов с нулевыми значениями;
- далее на основе установленных весов модель делает прогноз;
- на основе полученного прогноза рассчитывается градиент ошибки, после чего происходит обновление весов в сторону антиградиента функции потерь;
- шаги 2-3 повторяются до тех пор, пока градиент не станет нулевым, то есть пока алгоритм не сойдётся в минимуме (как правило, в данном случае используется критерий останова, например, пока разность градиентов на текущей и предыдущей итерациях не станет меньше заранее установленного порогового значения).
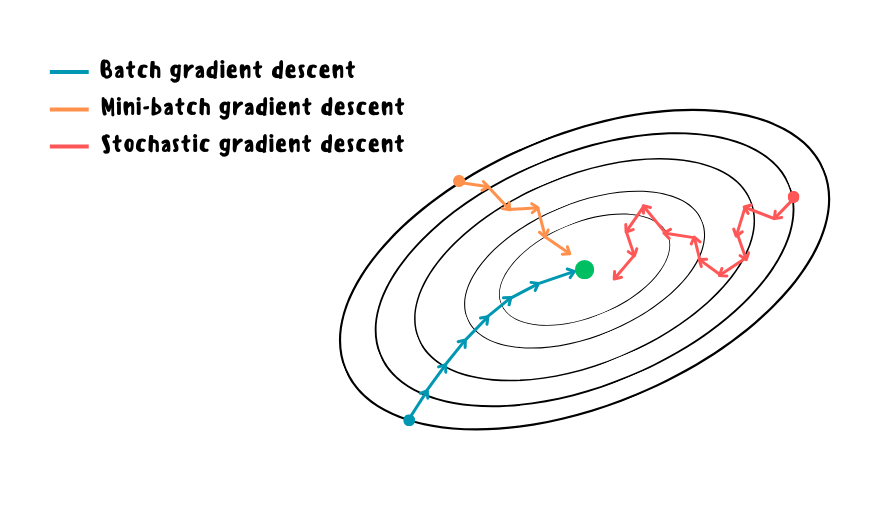
Если для вычисления градиентов функции потерь используется полный обучающий набор, то такой градиентный спуск называется пакетным. Не смотря на то, что пакетный градиентный спуск (batch gradient descent) практически всегда хорошо масштабируется в отношении количества признаков, данный алгоритм работает очень медленно на больших наборах данных и требует значительных затрат в виде дополнительной памяти для хранения всех градиентов.
Для увеличения производительности на больших датасетах применяются 2 подхода:
- Мини-пакетный градиентный спуск (mini-batch gradient descent), когда на каждом шаге вычисление градиентов происходит на небольших случайных поднаборах (мини-пакетах). Обычно размер мини-пакета берётся в виде 2^n и может достигать нескольких десятков тысяч образцов: выбор размера зависит от особенностей задачи и применяемой модели.
- Стохастический градиентный спуск (stochastic gradient descent), когда на каждом шаге из обучающего набора берётся лишь один образец. Очевидно, что такой вариант должен работать гораздо быстрее предыдущего, но с другой стороны, из-за ещё более стохастический природы данный алгоритм менее стабилен и может потребоваться больше итераций для сходимости, а также mini-batch дает прирост в производительности из-за аппаратной оптимизации матричных вычислений на GPU. Стоит также отметить, что на данный момент под стохастическим градиентный спуском очень часто подразумевается mini-batch.
В отличие от пакетного градиентного спуска, в данных случаях функция потерь будет снижаться скачками вверх-вниз, приближаясь к минимуму, но так и не достигнув его. В случае с мини-пакетным градиентным спуском функция потерь будет расположена чуть ближе к минимуму за счёт меньшего размера скачков. С другой стороны, в отличие от стохастического градиентного спуска, ему может быть труднее пройти локальные минимумы в невыпуклом случае.
Более быстрые и точные оптимизаторы
Помимо того, что градиентный спуск в своём классическом представлении плохо подходит для невыпуклых случаев из-за вышеописанных проблем, может также возникнуть проблема с "седловыми точками", когда на поверхности функции потерь в виде седла имеются точки, в которых значение функции максимально по одним направлениям и минимально по другим, то есть в данных точках будет практически нулевое снижение градиентов и они ошибочно могут быть приняты моделью за оптимум. Поэтому для быстрого поиска оптимального решения используются более интересные стохастические (mini-batch) оптимизации, про самые популярные из которых сейчас и пойдёт речь.
Momentum
Предположим, что со склона с кочками катится мяч, который сначала будет двигаться медленно, но по мере накопления кинетической энергии его скорость будет расти, что ему поможет преодолеть небольшие кочки и остановить своё движение в более глубокой. Именно данный принцип лежит в основе моментной оптимизации.
Momentum способен решить сразу две проблемы: плохую обусловленность матрицы Гессе и дисперсию стохастического градиента. С другой стороны, из-за вычисления градиента функции потерь в локальной позиции, модель может колебаться вокруг локальных минимумов, что в свою очередь увеличивает время схождения.
Nesterov momentum
Для решения вышеописанной проблемы применяется небольшая оптимизация, суть которой заключается в вычислении градиентов не в локальной позиции, а чуть дальше в направлении момента. Другими словами, функция потерь будет снижаться не в текущей позиции, а в которой якобы должна оказаться в будущем, следуя направлению импульса.
Алгоритм обновления параметров моментной оптимизации Нестерова
Такой подход позволяет сойтись гораздо быстрее и чуть ближе к оптимуму, однако он всё ещё может быть чувствительным в отношении одних направлений пространства параметров и нечувствительным в других из-за трудностей подбора оптимальной скорости обучения. Ниже будут представлены оптимизации градиентного спуска с адаптивной скоростью обучения.
AdaGrad
Adaptive Gradient является одной из первых оптимизаций градиентного спуска с адаптивным шагом, в которой снижается градиент вдоль самых крутых направлений. Проще говоря, на каждом шаге происходит обновление параметров модели с учётом значений как предыдущих градиентов, так и их квадратов.
Алгоритм обновления параметров AdaGrad
Такой простой подход позволяет алгоритму быстро начать обучение, а затем замедлить его, когда градиент становится меньше или меняет знак. Однако на практике AdaGrad хорошо справляется с выпуклыми случаями, а вот при обучении нейронных сетей нередко останавливается слишком рано из-за быстрого снижения скорости обучения, так и не достигнув глобального оптимума.
RMSProp
RMSProp (Root Mean Square Propagation) — модификация AdaGrad, адаптированная для лучшей работы в невыпуклом случае. Основная идея заключается в изменении способа агрегирования градиента на экспоненциально взвешенное скользящее среднее. Другими словами, вместо накопления всех квадратов градиента с начала обучения, накапливаются квадраты градиента только из самых последних итераций.
Алгоритм обновления параметров RMSProp
В целом, RMSProp является крайне эффективной оптимизацией, но не самой лучшей. Например, могут возникнуть трудности обучения в многомерных пространствах из-за проблем с масштабированием градиентов в разных направлениях.
Adam и его модификации
Adam (Adaptive Moment Estimation) объединяет в себе концепции Momentum и RMSProp, практически являясь серебряной пулей в задачах стохастической оптимизации. Как можно заметить, расчёт моментов в Adam очень схож с Momentum и RMSProp за исключением того, что к ним применяется поправка на смещение. В целом, благодаря таким улучшениям Adam сходится быстрее и лучше предшественников, а также более устойчив к подбору гиперпараметров, что делает его более стабильным решением в большинстве случаев.
Поправка на смещение:
Именно эти скорректированные величины используются далее для вычисления шага оптимизации.
С другой стороны, данный алгоритм более сложен в анализе и может быть чувствителен к шуму, что может привести к проблемам со сходимостью, а также он требует больших объемов памяти, поскольку хранит не только параметры модели, но а также информацию о градиентах и накопленном импульсе. Помимо этого, у Adam и всех предыдущих алгоритмов есть ещё один неприятный недостаток: если продолжить обучение модели после прерывания в некоторой точке, придётся восстанавливать не только веса модели из данной точки, но а также и всю информацию о накопленных параметрах.
Однако время не стоит на месте и были разработаны модификации Adam, призванные устранить в той или иной степени недостатки, описанные выше. К наиболее популярным и интересным модификациям можно отнести следующие:
- AdaMax использует экспоненциально взвешенную норму бесконечности для обновления вектора второго момента, то есть скорость обучения изменяется, основываясь на максимальной величине градиента в истории:
Nadam (Nesterov-accelerated Adaptive Moment Estimation) использует другую поправку на смещение для вектора первого момента: