В наше время модным словом AI называют что угодно. Давайте разберемся, что же из себя представляет AI.
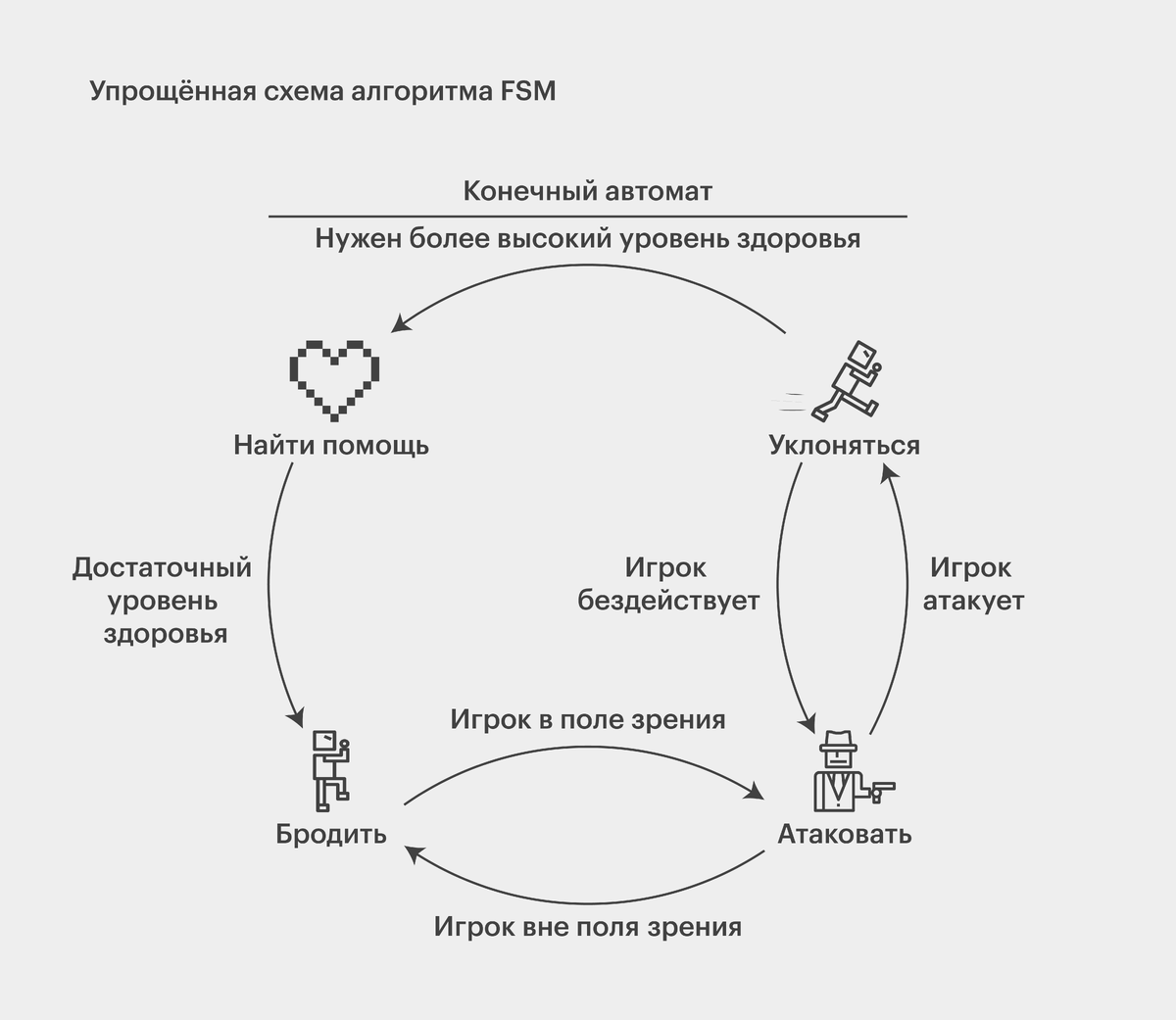
Уровень 0: ИИ в играх
Как ни странно, у ботов, которые играют с вами в игры (Counter Strike, Dota 2, стратегии и т.д.), общего с ИИ примерно 0.
Они работают почти всегда на ручных правилах и костылях, написанных разработчиками. Поэтому зачастую они такие глупые.
Даже если в какой-то игре игровой интеллект кажется вам действительно умным, с так называемым AGI (artificial general intelligence - общий искуственный интеллект) у него общего меньше чем со светофором, и даже правила переключения светофора могут быть устроены сильно сложнее.
Уровень 1: классическое машинное обучение
До того, как большие языковые модели по типу ChatGPT стали так популярны, под ИИ обычно подразумевалось нечто более простое - рекомендации фильмов/музыки, поисковые системы, подсказки на клавиатуре.
Большая часть приложений, которыми вы пользуетесь, так или иначе использует обучение на данных. В чем же тут отличие и почему это обучение 'классическое'?
Алгоритмы в классическом обучении легко интерпретируемы, основаны на статистических/математических методах, поэтому их намного проще тренировать и непосредственно понимать, как этот алгоритм думает.
Уровень 2: нейросети
Нейронные сети - де-факто инструмент, чтобы 'приблизить' функцию, объединяющую входные данные и выходные, но более точный и сложный, если сравнивать с теми же рядами Тейлора, и работающий в более слабых предположениях.
Тут мы вступаем на новую территорию - нейронные сети, даже небольшие, ГОРАЗДО сложнее интерпретировать.
Даже для нейронной сети на 100 тысяч параметров, что в миллионы раз меньше чем современные большие языковые модели, понять, почему она приняла то или иное решение, практически невозможно.
Однако нейросети очень хорошо умеют работать с гомогенными данными - когда входные данные одной природы. Поэтому они прекрасно проявляют себя на таких доменах как текст, звук, картинки - классическому машинному обучению тут не справиться, ибо слишком сложные зависимости почти невозможно смоделировать математически - остается лишь полагаться на 'приближенное' решение, которое и дают нейросети.
Уровень 3: большие языковые модели (мы здесь)
Казалось бы, LLM - те же нейросети. Почему же тогда мы выделяем их в новый уровень?
Во-первых, современные LLM сильно сложнее классических нейронных сетей - в них добавлено много наработок по типу механизма влияния, PE и прочей дряни, чтобы лучше моделировать особенности языка.
Во-вторых, большие языковые модели БОЛЬШИЕ. Это очень важно, и сейчас вы узнаете почему.
Раньше считалось, что если параметров у модели слишком много, то она просто запоминает все данные, и ее итоговое качество на новых данных будет плохим. Этот эффект называется переобучением.
Но! В какой-то момент появились следующие открытия - при достаточно большом наборе данных, после условного переобучения идет этап 'генерализации' - то есть выявления общих зависимостей. И тогда чем больше параметров, тем большее количество данных нейронная сеть может скушать и соответственно сильнее данный эффект. Именно поэтому большие языковые модели делают большими.
Основная проблема здесь, как видно по картинке - зависимость качества от количества параметров и количества данных логарифмическая. То есть чтобы улучшить качество на сколько-то, нам нужно данных и параметров во столько-то больше раз.
Почему же большие языковые модели некорректно называть ИИ?
У больших языковых моделей нет интеллекта, как и понятия размышлений, не смотря на техники Reasoning-а. Это просто умножение матриц с применением к результату функций, чтобы моделировать язык и отвечать получше.
Языковые модели не думают в привычном нам смысле - они просто вычисляют. Из-за этого и берутся галлюцинации - когда модель очень уверенно начинает гнать пургу.
Более того, данные не бесконечны - исследователи стараются придумать новые способы для получения синтетических данных, но синтетика страдает по качеству. И судя по законам масштабирования, приведенным выше, для уровня 'сверхинтеллекта' и AGI нам нужно космическое количество данных, которые нам неоткуда взять в текущий момент.
Поэтому, как я считаю, а я AI-пессимист, мы не получим сверхинтеллект на основе текущих концепций, и так называемый AI подошел к своему техническому пределу.
Либо нам нужны новые идеи, для которых необходимо кратно больше вычислительных мощностей, либо человеческий мозг так и останется лучшим обработчиком информации.