Путь к повсеместному ИИ
Стартап Taalas представили свой новый способ развертывания нейронок, они пихнули иишку в свой чип
Их первый продукт аппаратная версия Llama 3.1 8B, работает в 10 раз быстрее, стоит в 20 раз дешевле и потребляет в 10 раз меньше энергии, чем существующие решения
Массовое внедрение ии сдерживается двумя барьерами:
- Высокая задержка (модели отвечают медленнее, чем работает человеческое мышление)
- Затраты (развёртывание требует огромных дата-центров, жидкостного охлаждения и мегаватт энергии)
Решение Taalas
Компания разработала платформу, превращающую любую ии-модель в специализированный чип за 2 месяца
Они делают отдельный чип под каждую модель, устраняют разрыв между DRAM и процессором (объединяют память и вычисления) и отказываются от HBM, продвинутой упаковки, 3D-стекирования и жидкостного охлаждения соответственно переход к полному упрощению
За счет того, что они придерживаются своим этим трем принципам, думаю еще удивят нас
🔘Результаты
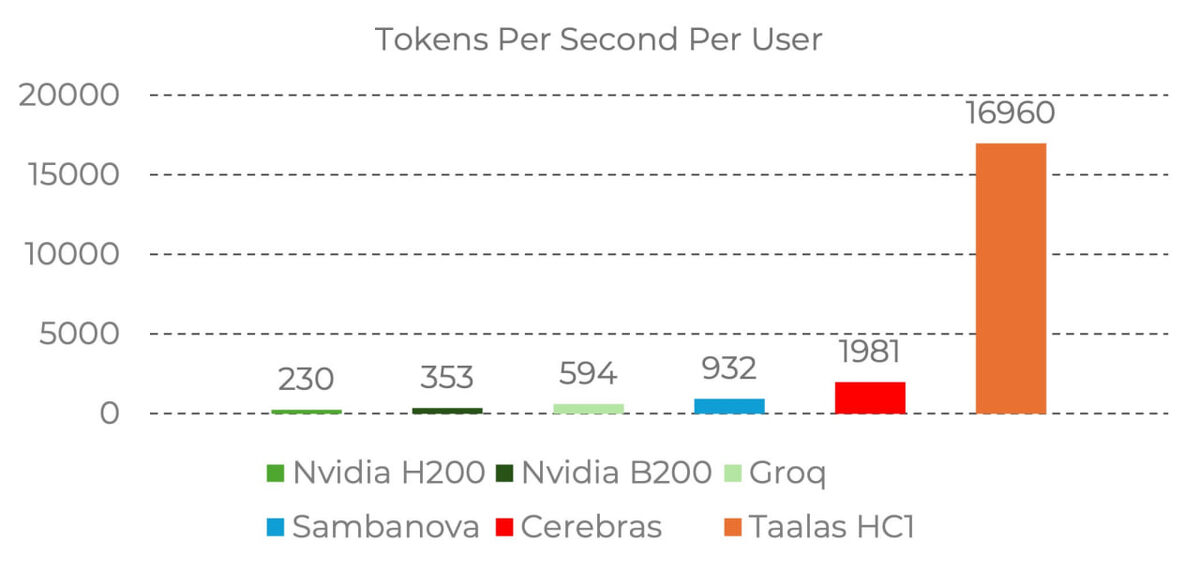
Кремниевая Llama 3.1 8B:
- 17 000 токенов/сек на пользователя
- Доступна как чат-бот и api-сервис
- Поддержка fine-tuning через LoRA
- Настраиваемый размер контекстного окна
Весной планируют среднеразмерную reasoning llm, а зимой frontier LLM на платформе второго поколения (HC2)
Скорость ответов у них в чате реально впечатлила, но как будто модель туповата😏 на api нужно подавать заявку