
1. Функциональные требования
Система должна обеспечивать автоматизированный контроль соблюдения регуляторных требований и выявление рисков с использованием ИИ.
- Сбор данных: интеграция с АБС (автоматизированная банковская система), системами ДБО, карточным процессингом для получения транзакций, данных клиентов, счетов.
- Мониторинг транзакций:
в реальном времени (потоковая обработка) и пакетный режим (post-factum);
применение правил (rule-based) и ML-моделей для выявления подозрительных операций (AML, мошенничество). - KYC (Know Your Customer):
верификация документов (OCR + NLP);
распознавание лиц, сверка с фотографиями;
проверка клиентов по санкционным спискам, спискам PEP (политически значимые лица), неблагонадежным контрагентам. - Скрининг:
проверка сделок и клиентов по международным и национальным санкционным спискам (OFAC, ЕС, РФ) в реальном времени;
обновление списков из внешних источников. - Оценка риска:
расчёт скоринга клиента/транзакции на основе ML;
динамическое профилирование рисков. - Case Management:
создание кейсов при срабатывании правил/моделей;
назначение ответственных, workflow расследования;
хранение всей переписки, документов, принятых решений. - Отчётность:
автоматическое формирование отчётов для ЦБ РФ (ФЭС, ОЭС), Росфинмониторинга;
предоставление данных по запросам регулятора. - Управление моделями ML:
версионирование, A/B тестирование, мониторинг качества (дрифт данных, точность);
возможность онлайн-обучения на новых данных. - Аудит и логирование:
фиксация всех действий пользователей и системы;
неизменяемость логов для расследований. - Интеграция с внешними источниками: бюро кредитных историй, государственные реестры, медиа-мониторинг (для выявления негативной информации).
2. Нефункциональные требования
- Производительность: пиковая нагрузка – 24 000 RPS (запросов на мониторинг транзакций) с временем отклика <100 мс для синхронных вызовов.
- Доступность: 99.99% (четыре девятки) для критических сервисов (мониторинг, скрининг); плановые простои – не более 1 часа в год.
- Масштабируемость: горизонтальное масштабирование микросервисов, автоматическое масштабирование под нагрузку (HPA в Kubernetes).
- Надёжность: отказоустойчивость за счёт репликации данных, кластеризации Kafka и БД, резервного копирования с RPO <15 мин, RTO <1 час.
- Безопасность:
шифрование данных при передаче (TLS) и хранении (AES-256);
ролевая модель доступа (RBAC), двухфакторная аутентификация;
защита от DDoS, инъекций, утечек. - Соответствие регуляторам: 115-ФЗ, GDPR (при работе с данными граждан ЕС), локальные нормативы.
- Наблюдаемость: сбор метрик (Prometheus), логов (ELK), трассировка (Jaeger) для диагностики и SLA.
- Асинхронность: длительные операции (обучение моделей, массовые проверки) через очереди.
- Интероперабельность: поддержка JSON, Avro, Protobuf для обмена данными.
3. Продуктовые метрики
- Операционные:
Количество проверенных транзакций (в сутки / пик RPS).
Среднее время обработки одной транзакции (latency).
Процент успешных ответов (availability). - Качество ML:
Precision, Recall, F1-мера моделей.
False Positive Rate (количество ложных срабатываний).
Время детекции новых паттернов мошенничества. - Эффективность комплаенса:
Количество выявленных подозрительных операций (SAR).
Доля кейсов, подтвердившихся после ручной проверки.
Время расследования одного кейса (среднее).
Отсутствие штрафов от регулятора. - Бизнес-метрики:
Снижение операционных затрат на комплаенс за счёт автоматизации.
Уменьшение false positive, сокращающих ручной труд.
Доля клиентов, прошедших KYC менее чем за 5 минут.
4. Список технологий
КатегорияТехнологииЯзыки/фреймворки Java (Spring Boot), Python (FastAPI, TensorFlow/PyTorch), Go
Потоковая обработка Apache Kafka, Kafka Streams, Apache Flink
Базы данных PostgreSQL (OLTP), MongoDB (документы), ClickHouse (аналитика), Redis (кэш)
Поиск/логи Elasticsearch + Kibana (ELK)
ML платформа MLflow (управление моделями), Seldon Core / KServe (serving)
Оркестрация Kubernetes, Docker, Helm
API Gateway Kong / NGINX + custom auth
Мониторинг Prometheus, Grafana, Jaeger
CI/CD GitLab CI / Jenkins
Хранилище данных HDFS / S3-совместимое объектное хранилище (например, Cloud Storage)
Очереди Apache Kafka (основная шина), RabbitMQ (для вспомогательных задач)
Service Mesh Istio (управление трафиком, безопасность)
5. Архитектура по C4 (уровень контейнеров)
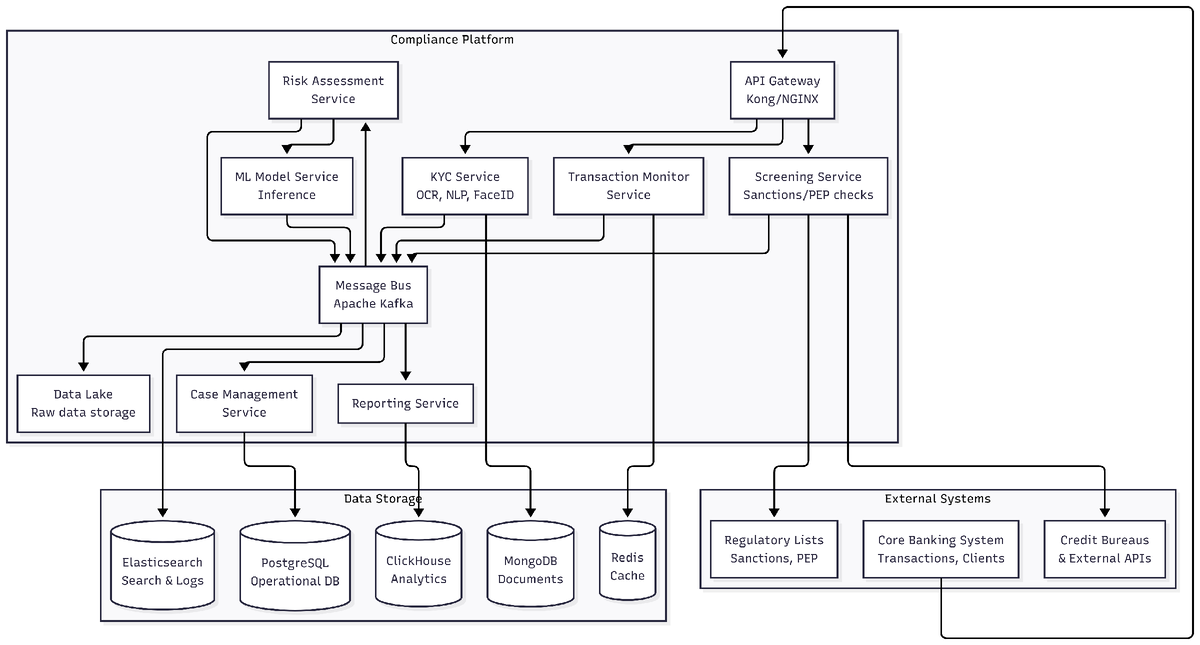
6. Описание инфраструктуры
- Кластер Kubernetes: мультизональный (3+ availability zones), набор нод для различных классов сервисов (compute-оптимизированные для ML, memory-оптимизированные для БД).
- Сеть: выделенные виртуальные сети (VPC) с сегментацией по безопасности, балансировщики нагрузки на входе (ALB/NGINX).
- Хранение:
Управляемые БД (PostgreSQL, MongoDB, ClickHouse) с автоматическим бекапом и репликацией.
Redis Sentinel/Cluster для высокой доступности кэша.
Объектное хранилище (S3) для хранения сырых данных (логи, документы, снапшоты). - Kafka кластер: несколько брокеров с репликацией 3, разбиение на топики по типу событий (транзакции, документы, результаты).
- Мониторинг: Prometheus собирает метрики со всех подов и сервисов, Grafana дашборды для разных команд, алертинг в PagerDuty/Telegram.
- CI/CD: автоматическая сборка образов, прогон тестов, деплой через GitOps (ArgoCD).
- Безопасность: Istio для mTLS между сервисами, Vault для хранения секретов, WAF на входе.
7. Количество микросервисов
Ориентировочно 20–25 микросервисов:
- Транзакционный монитор (streaming) – 2 (real-time, batch)
- KYC (OCR, NLP, FaceID) – 3
- Скрининг по спискам – 2 (синхронный, асинхронный)
- Оценка риска – 2 (скоринг, профилирование)
- Case Management – 2 (workflow, хранилище)
- Reporting – 2 (генерация, отправка)
- ML Model Serving – 2 (онлайн, пакетный)
- Управление моделями – 1
- Интеграция с внешними источниками – 2
- Аудит и логи – 1
- API Gateway – 1
- Авторизация/аутентификация – 1
- Административная панель (UI) – 1
- Уведомления – 1
8. Масштабирование системы
- Горизонтальное масштабирование: каждый микросервис запускается в нескольких репликах; HPA на основе CPU/memory или custom метрик (длина очереди Kafka).
- Kafka:
Увеличение числа партиций для параллельной обработки.
Группы потребителей с возможностью динамического добавления инстансов. - Базы данных:
Шардинг PostgreSQL по идентификатору клиента или транзакции.
Реплики для чтения (read replicas) для аналитических запросов.
Использование NewSQL (CockroachDB) при необходимости глобального шардирования. - Кэширование:
Redis-кластер с шардингом.
Кэширование справочников (санкционные списки) в памяти сервисов с инвалидацией через Kafka. - API Gateway: масштабируется горизонтально, использует балансировщик.
- ML Serving: инференс моделей через Seldon с автоскейлингом на основе входящего потока запросов.
- Data Lake: объектное хранилище масштабируется практически неограниченно.
9. Нагрузка на расширение 24000 RPS
- Расчёт: пиковая нагрузка – 24 000 запросов/сек на мониторинг транзакций. Это порядка 2 млрд запросов в сутки.
- Обработка:
Каждая транзакция проходит через API Gateway и попадает в Kafka (топик transactions с 64+ партициями).
Consumer группы (Transaction Monitor) могут масштабироваться до числа партиций, каждый инстанс обрабатывает свою долю.
ML-инференс выполняется асинхронно (модели могут быть тяжелыми), результаты публикуются в отдельный топик.
Для синхронных проверок (скрининг по спискам) используется кэш Redis с предзагруженными данными и высокопроизводительный инференс на базе ONNX или оптимизированных моделей. - Базы данных:
Оперативные данные пишутся в PostgreSQL через batch-вставки или use Kafka Connect Sink.
ClickHouse используется для аналитики, поддерживает высокую скорость вставки. - Тестирование: обязательно нагрузочное тестирование с имитацией 24k RPS, выявление узких мест, оптимизация запросов и индексов.
- Резервирование: все критичные сервисы дублируются в разных зонах доступности, автоматическое переключение при сбоях.
Данное решение обеспечивает гибкость, надёжность и соответствие строгим требованиям комплаенс в масштабах крупнейшего банка.
Страховка на собеседовании
Знание есть, но стресс мешает?
Бесплатное сообщество для прокачки карьеры в IT
Подпишись на https://t.me/IT_Interview_Partner_Bot
Подпишись на https://t.me/LyakhovEugene