
1. Введение
Цель проекта – создание масштабируемой, отказоустойчивой платформы дистанционного банковского обслуживания (ДБО), интегрированной с AI-сервисами (чат-бот, голосовой помощник, рекомендательная система, фрод-мониторинг). Система должна обеспечивать работу мобильного приложения, веб-версии и поддерживать интеграцию с внутренними системами банка.
2. Функциональные требования
- Аутентификация и управление доступом
Вход по логину/паролю, биометрии (лицо/голос), двухфакторная аутентификация (SMS/Push).
Управление сессиями и устройствами. - Управление счетами и продуктами
Просмотр баланса, выписок, истории операций.
Открытие вкладов, оформление кредитов (через интеграцию с CRM). - Платежи и переводы
Внутрибанковские и межбанковские переводы (СБП, SWIFT).
Регулярные автоплатежи, шаблоны.
Оплата услуг (ЖКХ, мобильная связь и т.д.). - Уведомления и коммуникации
Push-уведомления, SMS, email о событиях.
Чат с поддержкой (чат-бот + оператор). - AI-функции
Чат-бот с NLP для консультаций и выполнения операций.
Голосовой помощник для навигации и платежей.
Персональные рекомендации (продукты, кешбэк).
Фрод-мониторинг в реальном времени. - Документооборот
Загрузка/просмотр документов, электронная подпись. - Интеграция с внешними системами
Core Banking, CRM, платежные шлюзы, бюро кредитных историй.
3. Нефункциональные требования
- Доступность: 99.99% (включая AI-сервисы).
- Производительность:
Среднее время ответа API – <100 мс (95-й перцентиль).
AI-запросы (чат-бот) – <2 с. - Безопасность:
End-to-end шифрование (TLS), шифрование данных в покое (AES-256).
Соответствие PCI DSS, 152-ФЗ, GDPR.
Защита от DDoS, WAF. - Масштабируемость:
Горизонтальное масштабирование микросервисов.
Автоматическое масштабирование под нагрузку до 24 000 RPS. - Надежность:
Резервирование компонентов, мультизональное развертывание.
Автоматическое восстановление после сбоев. - Наблюдаемость:
Централизованный сбор логов, метрик, трассировка.
Мониторинг бизнес-метрик в реальном времени.
4. Продуктовые метрики
- Бизнес-метрики:
DAU/MAU (ежедневная/месячная аудитория).
Конверсия в целевые действия (платежи, оформление продуктов).
Доля обработанных запросов через AI (без перехода на оператора).
NPS (индекс лояльности). - Технические метрики:
Uptime системы.
Средняя и максимальная задержка.
Процент успешных запросов (HTTP 200).
Точность фрод-моделей (FPR, TPR).
5. Стек технологий
КомпонентТехнологииFrontend (Mobile/Web)React Native (iOS/Android), React (Web), Redux, TypeScriptAPI GatewayKong / Spring Cloud Gateway + Kubernetes IngressBackend (микросервисы)Java (Spring Boot), Go (для высоконагруженных сервисов), KotlinAI/MLPython (FastAPI), TensorFlow/PyTorch, Transformers, MLflow, KafkaБазы данныхPostgreSQL (ACID), Oracle (Core), Redis (кэш/сессии), ClickHouse (аналитика)Поиск и логиElasticsearch + Kibana (ELK)Очереди и стримингApache Kafka, Debezium (CDC)ОркестрацияKubernetes, Docker, HelmService MeshIstioМониторингPrometheus, Grafana, Jaeger (трассировка)CI/CDGitLab CI, ArgoCDХранилищеS3-совместимое (MinIO / Yandex Object Storage)
6. Архитектура системы (C4)
Контекстная диаграмма
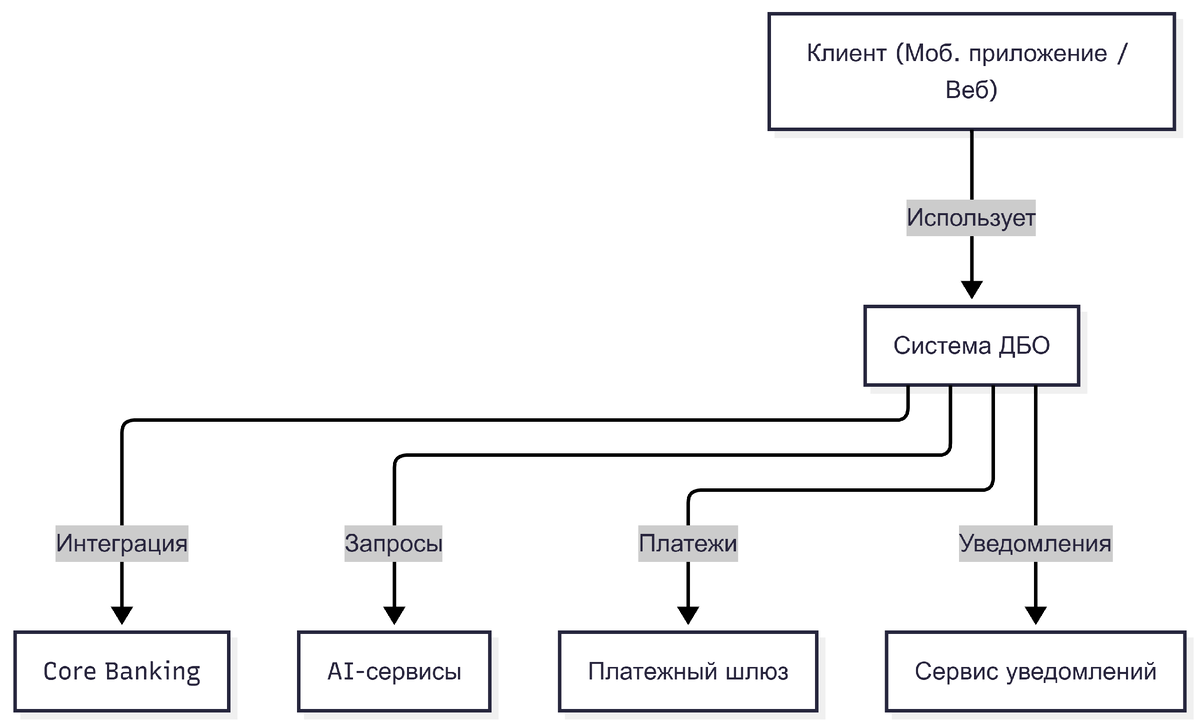
Контейнерная диаграмма
7. Описание инфраструктуры
- ЦОД: Два географически распределенных дата-центра (Active-Active) с возможностью работы в режиме Disaster Recovery.
- Kubernetes кластеры: Несколько кластеров (prod, staging, dev) с поддержкой мультизональности. Используется Istio для управления трафиком и безопасности.
- Базы данных:
PostgreSQL – managed кластер с репликацией (мастер-реплика) и автоматическим фейловером.
Oracle – используется для Core Banking, репликация через Data Guard.
Redis – кластер Sentinel для высокой доступности.
ClickHouse – шардированный кластер для аналитики. - Хранилище: S3-совместимое объектное хранилище для документов и файлов.
- Сеть: Выделенные VLAN, балансировщики нагрузки (Hardware + Software), защита DDoS на уровне провайдера.
- Мониторинг и логирование: Prometheus собирает метрики со всех сервисов, Grafana – дашборды, Loki – логи, Jaeger – трассировка.
8. Количество микросервисов
Ориентировочный состав (~20 микросервисов):
- Auth Service (аутентификация/авторизация)
- User Profile Service
- Account Service (счета)
- Payment Service (платежи)
- Transfer Service (переводы)
- Card Service (карты)
- Credit Service (кредиты)
- Deposit Service (вклады)
- Notification Service
- Document Service
- Chatbot Service (AI)
- Voice Assistant Service (AI)
- Recommender Service (AI)
- Fraud Detection Service (AI)
- Audit Service (аудит)
- Report Service (отчеты)
- Integration Gateway (адаптеры к внешним системам)
- Admin Service (администрирование)
- Analytics Service (сбор метрик)
- Config Service (управление конфигами)
Каждый сервис владеет своей схемой данных и общается через синхронные API (gRPC/REST) и асинхронные события (Kafka).
9. Масштабирование системы
- Горизонтальное масштабирование: Каждый микросервис масштабируется независимо (Kubernetes HPA) по CPU, памяти или пользовательским метрикам (например, длина очереди).
- Базы данных:
PostgreSQL: шардирование по ключу (например, ID клиента) или использование Citus для распределенных таблиц.
Redis: кластеризация.
ClickHouse: распределенные таблицы с шардами. - Кэширование: Интенсивное использование Redis для сессий, кэша профилей, тарифов.
- Асинхронность: Тяжелые операции (выписки, массовые рассылки) выносятся в очереди (Kafka) с обработкой в Consumer'ах.
- CDN: Статика (иконки, шрифты, часть HTML) раздается через CDN для снижения нагрузки на бэкенд.
- API Gateway: Масштабируется горизонтально, использует балансировку на уровне L4.
10. Обеспечение нагрузки 24 000 RPS
Пиковая нагрузка в 24 000 запросов в секунду требует особого подхода:
- Распределение нагрузки:
API Gateway кластер из нескольких инстансов (например, 12 нод по 2000 RPS каждый).
Балансировка на уровне DNS (GeoDNS) и L4-балансировщиков. - Оптимизация запросов:
Агрегация данных на стороне BFF (Backend for Frontend) для уменьшения числа вызовов.
Использование GraphQL для сложных экранов (но осторожно, может увеличить нагрузку). - Кэширование на всех уровнях:
Кэш ответов API в Redis (например, для часто запрашиваемых справочников).
HTTP-кэширование (Cache-Control) для публичных данных. - Шардирование данных:
Пользователи распределены по шардам БД. Запросы от конкретного клиента идут в конкретный шард. - Автомасштабирование:
HPA настроено на упреждение: при достижении 60% CPU добавляются новые поды.
Использование Cluster Autoscaler для добавления узлов в кластер. - Rate Limiting и Throttling:
На уровне API Gateway ограничение по клиентам, чтобы избежать перегрузки от одного источника. - AI-сервисы:
Для моделей машинного обучения используются GPU-инстансы с автоскейлингом.
Асинхронная обработка для фрода и рекомендаций (Kafka streams). - Тестирование:
Регулярные нагрузочные тесты (например, с помощью Gatling или Locust) для проверки пропускной способности.
Chaos Engineering для проверки отказоустойчивости.
Примерный расчёт:
- Средний размер запроса ~2 КБ, входящий трафик ~48 МБ/с, исходящий – в несколько раз больше (ответы).
- Сеть должна поддерживать 10 Гбит/с на каждый шлюз.
- База данных: 24k RPS означает 24k транзакций в секунду (с учётом чтения/записи). Postgres в кластере может обрабатывать до 10k write TPS, поэтому требуется шардирование и реплики чтения.
- Использование очередей (Kafka) позволяет буферизировать пиковые нагрузки для асинхронных операций.
Таким образом, система проектируется с расчётом на линейное масштабирование и резервирование, что позволяет достичь целевых 24 000 RPS.
Страховка на собеседовании
Знание есть, но стресс мешает?
Бесплатное сообщество для прокачки карьеры в IT
Подпишись на https://t.me/IT_Interview_Partner_Bot
Подпишись на https://t.me/LyakhovEugene