
Выбор правильной базы данных — одно из ключевых архитектурных решений при разработке любого приложения. В этом ответе я детально разберу существующие технологии проектирования баз данных, классифицируя их по моделям данных, предоставлю подробную таблицу сравнения и дам рекомендации по выбору для различных задач.
Понимание типов баз данных выходит за рамки простого выбора между SQL и NoSQL. Современные системы классифицируются по нескольким независимым измерениям: модели данных (как данные логически структурированы), характеру нагрузки (транзакционная или аналитическая), формату хранения (строки или колонки) и архитектуре развертывания (централизованная, распределенная, встроенная) .
Детальный обзор технологий проектирования баз данных
Ниже представлен подробный обзор основных типов баз данных, сгруппированных по их моделям данных и целевому назначению.
1. Реляционные базы данных (SQL, RDBMS)
Это наиболее зрелая и распространенная технология. Данные организуются в виде таблиц (строк и столбцов) с жестко определенной схемой (схема "на записи"). Связи между таблицами устанавливаются с помощью первичных и внешних ключей. Они обеспечивают поддержку ACID (атомарность, согласованность, изоляция, долговечность) и используют язык SQL .
- Когда использовать: Для систем, где критически важны целостность данных и сложные запросы с объединениями (JOIN). Это основа для финансовых систем, ERP, CRM, интернет-магазинов с четкой структурой заказов и товаров .
- Примеры: PostgreSQL, MySQL, Oracle Database, SQL Server.
2. Документо-ориентированные базы данных
Это тип NoSQL баз, где данные хранятся в виде документов (обычно JSON, BSON). Схема данных гибкая ("схема на чтении") — документы в одной коллекции могут иметь разный набор полей. Данные, которые в реляционной БД потребовали бы нескольких таблиц, часто хранятся в одном документе в виде вложенной структуры .
- Когда использовать: Для систем с часто меняющейся структурой данных, каталогов товаров (где у разных товаров разные характеристики), систем управления контентом (CMS), профилей пользователей, когда важна скорость разработки и высокая масштабируемость .
- Примеры: MongoDB, CouchDB.
3. Ключ-значение (Key-Value Stores)
Простейшая форма NoSQL. Данные представляют собой коллекцию пар "ключ-значение". Доступ к значению возможен только по ключу, что обеспечивает экстремально высокую скорость чтения и записи. Значение для базы данных "непрозрачно" .
- Когда использовать: Для кэширования (чтобы снизить нагрузку на основную БД), управления пользовательскими сессиями, хранения настроек и фич-флагов, систем реального времени (например, таблицы лидеров в играх) .
- Примеры: Redis, Amazon DynamoDB, Memcached.
4. Колоночные базы данных (Wide-Column Stores)
Данные хранятся не по строкам, а по колонкам. Это позволяет эффективно сжимать однотипные данные и очень быстро выполнять агрегатные функции (SUM, AVG, COUNT) над огромными объемами информации. Строки могут содержать разные наборы колонок .
- Когда использовать: Для аналитических нагрузок (OLAP), бизнес-аналитики (BI), хранения данных сенсоров (IoT), логов и событий, где требуется запись и сканирование огромных массивов данных .
- Примеры: Apache Cassandra, HBase, ClickHouse.
5. Графовые базы данных
Данные хранятся в виде узлов (сущности) и ребер (связи между ними). Такой подход оптимизирован для обхода связей любой глубины, что в реляционных БД требует сложных и медленных рекурсивных JOIN-запросов .
- Когда использовать: Для социальных сетей (друзья друзей), систем рекомендаций (товары, которые также покупают), механизмов выявления мошенничества (fraud detection), построения графов знаний .
- Примеры: Neo4j, JanusGraph, ArangoDB.
6. Базы данных временных рядов (Time Series Databases — TSDB)
Оптимизированы для данных, которые меняются во времени. Ключевая особенность — высокая скорость записи потоковых данных и эффективное хранение с политиками автоматического удаления устаревших данных (retention policies) и их агрегации .
- Когда использовать: Для мониторинга инфраструктуры (метрики работы серверов), сбора данных с устройств Интернета вещей (IoT), анализа финансовых тикеров, отслеживания изменений показателей в реальном времени .
- Примеры: InfluxDB, Prometheus, TimescaleDB.
7. Модели для аналитики и хранения данных (Data Warehousing)
Сюда входят два ключевых понятия:
- Транзакционные системы (OLTP): Оптимизированы на большое количество мелких, атомарных транзакций в реальном времени (онлайн-покупка, бронирование билета) .
- Аналитические системы (OLAP): Оптимизированы для сложных, ресурсоемких запросов, сканирования миллионов строк для построения отчетов и дашбордов. Часто используют многомерное моделирование (схема "звезда" или "снежинка" с таблицами фактов и измерений) .
8. Встраиваемые базы данных
Это библиотеки, которые работают внутри приложения, не требуя установки отдельного серверного ПО. Они идеальны для локального хранения данных .
- Когда использовать: В мобильных приложениях, настольном ПО, в браузерах, на граничных устройствах (edge computing), где нет постоянного подключения к сети.
- Примеры: SQLite, DuckDB.
9. Мультимодельные базы данных
Современные базы данных, которые поддерживают несколько моделей данных в рамках одного движка. Например, могут работать как документное хранилище, графовая БД и key-value store одновременно .
- Когда использовать: Для упрощения архитектуры, когда приложению требуются разные модели, но не хочется поддерживать несколько разнородных систем.
- Примеры: ArangoDB, PostgreSQL (с поддержкой JSONB и расширений), Azure Cosmos DB.
Сравнительная таблица технологий баз данных
В этой таблице сведены ключевые параметры для сравнения описанных выше технологий .
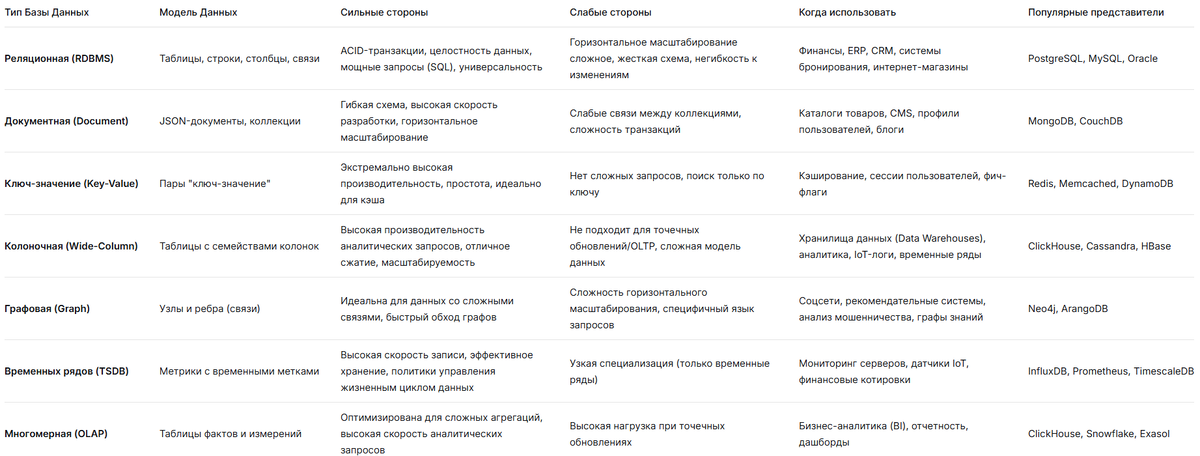
Руководство по выбору: какая база данных лучше для каких задач?
Выбор базы данных должен начинаться не с моды на технологию, а с анализа требований вашего проекта . Используйте следующий алгоритм принятия решения:
1. Для транзакционных систем (OLTP) с критически важной целостностью данных
- Сценарий: Банковские переводы, оформление заказов, управление складскими остатками.
- Потребность: Гарантия, что транзакция либо полностью выполнится, либо не выполнится вовсе (ACID). Сложные связи между сущностями (заказ-товары-платеж-доставка).
- Решение: Реляционная база данных (RDBMS). Лучший выбор — PostgreSQL или MySQL.
2. Для аналитических систем (OLAP) и бизнес-отчетности
- Сценарий: Построение дашбордов по продажам за несколько лет, анализ поведения миллионов пользователей.
- Потребность: Максимальная скорость чтения и агрегации огромных массивов данных.
- Решение: Колоночная база данных или OLAP-система, например ClickHouse или специализированное облачное хранилище вроде Snowflake . При построении витрин данных часто используется многомерное моделирование (схема звезды) .
3. Для проектов с быстро меняющейся структурой данных (стартапы, MVPs)
- Сценарий: Разработка нового продукта, где требования к данным постоянно меняются. Каталог товаров, где у каждой категории свой набор характеристик.
- Потребность: Гибкость схемы, возможность быстро вносить изменения без миграций и простоев.
- Решение: Документная база данных, например MongoDB. Она позволит быстро итерировать функциональность.
4. Для систем, где главное — связи между данными
- Сценарий: Социальная сеть (кто с кем дружит), рекомендательная система (какие товары похожи), антифрод-система (поиск мошеннических цепочек).
- Потребность: Эффективный обход графов связей неограниченной глубины.
- Решение: Графовая база данных, например Neo4j.
5. Для высоконагруженных систем с простыми паттернами доступа
- Сценарий: Кэширование результатов тяжелых запросов, хранение сессий пользователей для тысяч одновременных подключений, рейтинги в реальном времени.
- Потребность: Микросекундные задержки, максимальная производительность чтения/записи по ключу.
- Решение: База данных класса «ключ-значение», чаще всего in-memory (в памяти), например Redis .
6. Для потоков данных с привязкой ко времени (IoT, мониторинг)
- Сценарий: Сбор температуры с тысяч датчиков каждую секунду, метрики загрузки CPU сервера.
- Потребность: Очень высокая скорость записи, автоматическая ротация и агрегация старых данных.
- Решение: База данных временных рядов (TSDB), например InfluxDB или Prometheus .
7. Для глобально распределенных приложений с высокой доступностью
- Сценарий: Социальная платформа с миллионами пользователей по всему миру, которая должна работать без перебоев даже при отказе целого дата-центра.
- Потребность: Бесшовное горизонтальное масштабирование, репликация между регионами.
- Решение: NewSQL (например, Google Spanner) или распределенные NoSQL базы (Cassandra, DynamoDB), которые жертвуют строгой согласованностью (consistency) в пользу доступности (availability) согласно CAP-теореме .
8. Для локального хранения в приложении
- Сценарий: Мобильное приложение, работающее офлайн, десктопная программа.
- Потребность: Нулевая сложность развертывания, работа внутри процесса приложения.
- Решение: Встраиваемая база данных, например SQLite .
Критически важные факторы выбора
- CAP-теорема: Определите, что важнее для вашей распределенной системы — строгая согласованность данных (Consistency) или постоянная доступность (Availability) при возможных сбоях сети (Partition tolerance). SQL обычно выбирает Consistency, многие NoSQL — Availability .
- Стоимость поддержки: Учитывайте не только лицензии, но и сложность администрирования (DevOps-нагрузку). Иногда проще взять управляемый облачный сервис (DBaaS) .
- Навыки команды: Если ваша команда — эксперты по PostgreSQL, использование графовой БД должно быть оправдано весомыми причинами, так как это создаст кривую обучения.
Важно: В современных сложных приложениях редко используется только один тип базы данных. Распространенной практикой является полиглотное проектирование, когда для разных задач используются разные базы данных (например, PostgreSQL для основного учета, Redis для кэша, ClickHouse для аналитики, Elasticsearch для полнотекстового поиска) .
Страховка на собеседовании
Знание есть, но стресс мешает?
Бесплатное сообщество для прокачки карьеры в IT
Подпишись на https://t.me/IT_Interview_Partner_Bot
Подпишись на https://t.me/LyakhovEugene