
Наблюдая хайп вокруг ИИ и прочих нейросетей прям как-то тяжело оставаться в стороне от всей этой движухи.
А в этой движухе главное что? Правильно, главное – «Б», то есть безопасность. Если уж приручать нейросеть, то делать это так, чтобы это животное не выносило сор из избы. А поэтому что? Надо чтобы всё это непотребство работало локально, на своем железе.
Так что идем в гамазин и хватаемся за стакан валидола от цен на комплектулху.
Плашка памяти DDR5 на 32 Гб от 30 тыс в более-менее приличном магазине. Две – соответственно, 60.
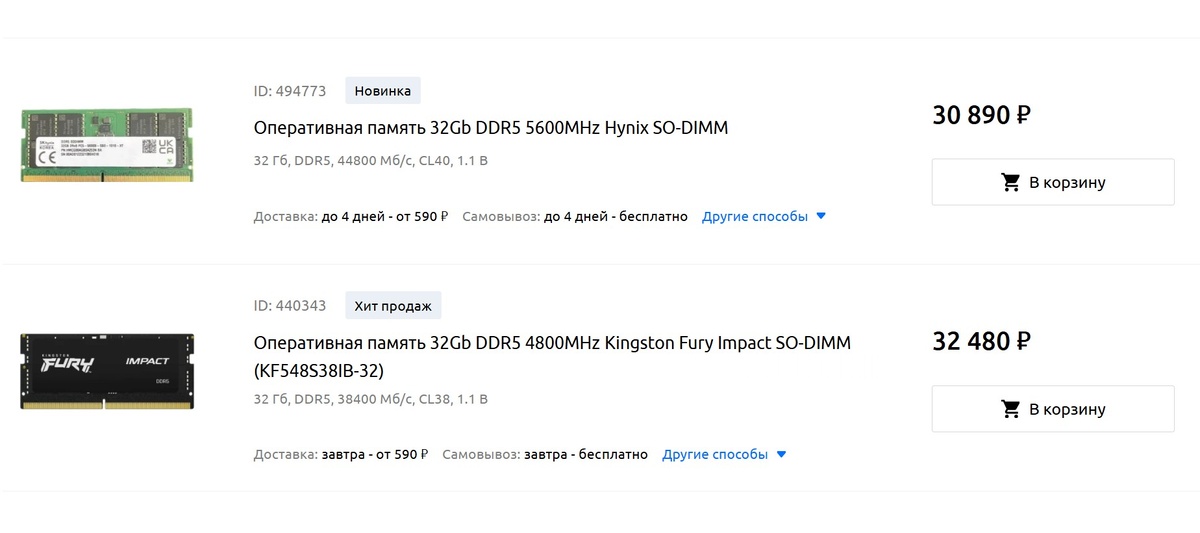
Люди, куда катится этот мир? Надо было полгода назад покупать опционы на оперативку. Жаль, таких нет на Мосбирже. Хотя, их нигде нет. А то уже можно стать миллионером. Или миллионершей.
SSD и HDD – такая же боль.
Странно что материнки и процы еще стоят более-менее вменяемых денег.
Кстати, Мосбиржа, сделай фьючерс на бензин, а? )))
Впрочем, не будем отвлекаться.
Вспомнилось что дома есть парочка древних системников. Ну как древних. Относительно. Народные DS3P с сокетом АМ3+, процы FX8320E, сколько-то оперативы (DDR3 естественно). Самое, как мне казалось, ценное, - видюхи GTX1070. И прям ручки зачесались применить их для размещения и использования нейросеток. Ну а что, памяти можно добить. Процы хоть и старые, но так-то восьмиядерники.
А еще нашлась инфа про возможность раскидать нейросетку на части с помощью фрейворков или прочих приблуд типа Kubernetes или Exo. В общем, был план и мы его придерживались. Жопка чувствовала что идея так себе, но зуд рукоблудства тяжело остановить.
Но тут дернул меня черт скачать на телефон приложение Deepseek. Дабы испытать ее возможности, ей и был задан вопрос о том, насколько адекватны авторы идеи и не надо ли в этом случае принять узбагоительное?
В общем, вот что получилось:
Я – собственно, я.
DS – Deep мать его величество Seek.
Как говоридзе, погнали! Страдать так страдать.
Я: Скажи, подойдет для развертывания нейросети такая конфигурация компьютера: материнская плата am3+, процессор fx8320e, оперативная память 32gb, видеокарта gtx1070?
DS: Это рабочая, но неоптимальная и устаревшая конфигурация для развертывания нейросети в 2025 году. Рассмотрим по пунктам:
✅Плюсы (что подходит):
1. Оперативная память 32 ГБ — это хорошо для обработки больших датасетов и работы с крупными моделями в оперативке.
2. Видеокарта GTX 1070 — имеет 8 ГБ памяти GDDR5, что критически важно. Это позволяет обучать и запускать нетребовательные модели (например, классические CNN для классификации изображений, некоторые версии Stable Diffusion с оптимизациями). Поддержка CUDA обязательна.
3. Наличие дискретной видеокарты — без неё на таком CPU нейросети практически невозможны.
⚠️ Критические недостатки:
1. Процессор FX-8320E — архитектура AMD Bulldozer/Piledriver (2012 г.) очень старая, чрезвычайно низкая производительность на ядро и низкий IPC. Будет бутылочным горлышком при:
· Предобработке данных (data pipeline).
· Всей работе, если модель выполняется на CPU.
· Работе с фреймворками (PyTorch/TensorFlow), которым нужна хорошая производительность CPU даже при использовании GPU.
2. Платформа AM3+ и DDR3 — устаревшая шина и тип памяти, что ограничивает скорость обмена данными с GPU и между компонентами.
3. Видеокарта GTX 1070 — отсутствует поддержка аппаратного ускорения для тензорных операций (Tensor Cores), которые есть в картах начиная с RTX 20xx (NVIDIA Turing) и новее. Это значит, что модели, использующие смешанную точность (FP16/FP32), будут работать в разы медленнее, чем на современных картах. Для обучения это огромная потеря времени и эффективности.
4. Энергоэффективность — система будет потреблять много электроэнергии при относительно низкой производительности.
📊 Оценка для разных задач:
· Обучение моделей с нуля: Плохо. Очень медленно из-за CPU и отсутствия Tensor Cores. Подойдет только для очень маленьких учебных моделей (MNIST, CIFAR-10).
· Инференс (запуск готовых моделей): Условно пригодно. Можно запускать многие классические и оптимизированные модели (YOLO, некоторые NLP модели). Скорость будет ниже, чем на современном железе.
· Обучение/использование легких моделей и для учебы: Подойдет. Для изучения основ deep learning, работы с Kaggle kernel-подобными задачами.
· Stable Diffusion / генеративные модели: Можно запускать с оптимизациями (--medvram, xFormers) и в FP16, но скорость генерации будет низкой, а максимальный размер изображения ограничен.
💡 Рекомендации:
1. Если система уже есть — можно начать с нее для обучения основам, но будьте готовы к ограничениям. В будущем первым шагом для апгрейда должна стать видеокарта (минимум RTX 3060 12GB / RTX 4060 Ti 16GB), но затем CPU станет еще более явным узким местом.
2. Если планируете покупку/сборку — лучше собрать систему на современной платформе (даже бюджетной AM4 с Ryzen 5 5600 и DDR4). Это даст многократный прирост производительности и путь для апгрейда.
3. Альтернатива: Рассмотрите облачные вычисления (Google Colab Pro, Kaggle Notebooks, Vast.ai). Затраты на электроэнергию и моральное устаревание этой конфигурации могут превысить стоимость облачных сессий для обучения.
Итог: Конфигурация рабочая для старта и инференса нетребовательных моделей, но крайне неэффективна для серьезного обучения. Её можно рассматривать только как временное решение или если она у вас уже есть.
Комментарий: Поскольку она у меня уже есть, проявляю настойчивость.
Я: Использование кластера из двух таких рабочих станций может улучшить параметры работы?
DS: Отличный вопрос. Короткий ответ: теоретически — да, практически — почти нет, и это создаст больше проблем, чем решит.
Разберем подробно, почему кластеризация двух таких машин не будет эффективным решением для нейросетей.
🔧 Как обычно работает распределенное обучение (например, в PyTorch DDP, Horovod):
1. Data Parallelism (Параллелизм данных): Одна модель есть на всех GPU, каждый GPU обрабатывает свою часть батча данных. После каждого шага градиенты усредняются между всеми GPU.
2. Model Parallelism (Параллелизм модели): Огромная модель, не помещающаяся в память одной GPU, разбивается на части, которые размещаются на разных GPU.
3. Pipeline Parallelism: Комбинация, когда модель разбита на этапы, которые выполняются последовательно на разных GPU.
❌Почему кластер из двух FX-8320E + GTX 1070 будет плохой идеей:
1. Критическое узкое место: скорость межпроцессорного обмена (коммуникация)
· Внутри одной машины GPU общаются через быструю шину PCIe (и часто через NVLink/SLI в современных системах).
· Между двумя разными машинами обмен данными идет по сети (Ethernet). Даже в идеале с гигабитной сетью (1 Гбит/с = ~125 МБ/с) это в десятки раз медленнее, чем PCIe 3.0 x16 (16 ГБ/с).
· Для распределенного обучения нужно постоянно синхронизировать градиенты или активации. Сетевая задержка (latency) и низкая пропускная способность (bandwidth) станут главным тормозом. Обучение может даже замедлиться, а не ускориться.
2. Неподходящий тип видеокарт (отсутствие NVLink)
· GTX 1070 не поддерживает NVLink (технология для сверхбыстрой связи между GPU). В одной системе они будут общаться только через PCIe (что нормально), а между системами — только через медленную сеть.
· Современные карты для ML (A100, H100, RTX 4090) имеют NVLink/HiPPI именно для эффективного многогпушечного обучения.
3. Слабость центральных процессоров
· При межмашинной коммуникации задействуются CPU для управления сетевым обменом. FX-8320E с его устаревшими ядрами создаст дополнительную нагрузку и задержку, еще больше снижая эффективность.
4. Сложность настройки и администрирования
· Вам придется настроить:
· Общую файловую систему (NFS) для датасетов и кода.
· Беспарольный SSH между узлами.
· Специальные переменные окружения для фреймворков (MASTER_ADDR, MASTER_PORT, RANK, WORLD_SIZE).
· Сетевую синхронизацию времени.
· Это нетривиальная задача, требующая серьезных сис-админ навыков. Время на настройку может многократно превысить потенциальную выгоду.
📊 Что МОЖНО реально улучшить в такой конфигурации?
Если у вас есть два идентичных компьютера, их лучше использовать не как единый кластер, а как два независимых вычислительных узла:
1. Параллельные эксперименты — самая практичная опция. На одной машине обучаете модель с гиперпараметрами A, на другой — с гиперпараметрами B. Это удвоит вашу производительность в пересчете на перебор экспериментов.
2. Разделение задач — на одной станции запущен инференс модели для пользователей, на второй — обучение новой модели.
3. Обучение очень больших моделей (гипотетически) — если модель категорически не помещается в 8 ГБ памяти одной GTX 1070, можно попробовать разнести её слои по 4 GPU на двух машинах (Model Parallelism). Но из-за частой синхронизации по сети скорость будет крайне низкой, а реализация — очень сложной. Практически никто так не делает из-за неэффективности.
💡 Рациональные пути улучшения производительности (вместо кластеризации):
1. Апгрейд внутри одной системы (самый эффективный путь):
· Видеокарта: Заменить GTX 1070 на RTX 3060 12GB или RTX 4060 Ti 16GB. Вы получите больше видеопамяти и главное — Tensor Cores, что даст кратный (в 3-5 раз) прирост скорости в обучении.
· Платформа: В долгосрочной перспективе — замена материнской платы, CPU и памяти на современную платформу (AM4/LGA1700).
2. Оптимизация кода и процессов:
· Использование смешанной точности (AMP) (но для GTX 1070 без Tensor Cores выигрыш будет скромным).
· Оптимизация загрузки данных (предзагрузка, кэширование).
· Использование готовых, оптимизированных моделей.
3. Облачные вычисления (наиболее мощный вариант):
· Аренда одной мощной машины в облаке (например, с RTX 4090 24GB или RTX A6000 48GB) для обучения будет несопоставимо эффективнее, чем возня с кластером из двух слабых ПК.
Итог: Создание кластера из двух описанных систем не решит фундаментальных проблем (слабые CPU, отсутствие Tensor Cores, медленная связь между GPU) и добавит огромную сложность. Это архитектурно неверный путь. Лучше использовать машины для параллельных экспериментов или направить ресурсы на апгрейд одного узла.
Комментарий: еще более убедительно, но продолжаем настаивать!
Я (изображаю неадеквата): А что если использовать две gtx1070 в режиме sli?
DS: SLI (Scalable Link Interface) абсолютно бесполезен и даже вреден для задач машинного обучения и нейронных сетей.
Развею это распространенное заблуждение:
❌Почему SLI НЕ РАБОТАЕТ для нейросетей:
1. Разное предназначение:
· SLI создан для игр — он дублирует геометрию и рендеринг кадров, позволяя двум GPU совместно отрисовывать одну сцену.
· Для вычислений (CUDA) — каждая видеокарта работает как независимый вычислительный ускоритель. Фреймворки вроде PyTorch/TensorFlow видят их как две отдельные GPU.
2. Нет объединения видеопамяти:
· Это главный миф. При SLI память НЕ СКЛАДЫВАЕТСЯ (т.е. у вас не будет 8 ГБ + 8 ГБ = 16 ГБ).
· Данные дублируются в памяти каждой карты. Фактически у вас будет 2 × 8 ГБ идентичных данных, что не позволяет загрузить модель, требующую больше 8 ГБ.
· Объединенная память (NVLink) появилось только у профессиональных карт (NVIDIA NVLink) и у некоторых топовых игровых (RTX 3090/4090 имеют NVLink, но GTX 1070 его не имеет).
3. Режимы SLI бесполезны для CUDA:
· Режимы Split Frame Rendering (SFR) или Alternate Frame Rendering (AFR) не имеют отношения к параллельным вычислениям в ML.
✅Как на самом деле использовать две GTX 1070 для нейросетей:
Единственный рабочий способ — режим нескольких независимых GPU (без включения SLI в драйверах!):
1. Data Parallelism (Параллелизм данных):
· Фреймворк (PyTorch/TensorFlow) автоматически распределит батч данных между двумя картами.
· Ускорение: В идеале можно получить ~1.8x ускорение (не 2x из-за накладных расходов на синхронизацию через PCIe).
· Память: Каждая карта должна вместить полную копию модели + свой кусок данных. То есть модель по-прежнему ограничена 8 ГБ на карту.
2. Model Parallelism (Распределение модели):
· Можно вручную разместить разные слои нейросети на разных картах. Это сложно и эффективно только для очень больших моделей.
⚠️ Суровые ограничения вашей конфигурации с двумя GTX 1070:
1. Бутылочное горлышко — CPU и платформа:
· FX-8320E будет катастрофически не успевать обрабатывать данные для двух GPU. Вы не сможете их "накормить" данными.
· Старая шина PCIe и контроллер на материнской плате AM3+ могут не обеспечивать достаточную пропускную способность для двух карт в режиме x8/x8.
2. Отсутствие Tensor Cores:
· Обе карты лишены современных Tensor Cores. Обучение со смешанной точностью (FP16) будет очень медленным по сравнению с любой RTX картой.
3. Двойное энергопотребление и нагрев:
· Две GTX 1070 потребляют ~300 Вт. Вам нужен БП от 750 Вт и хорошее охлаждение.
📊 Реальный сценарий использования двух GTX 1070:
# Пример кода PyTorch для использования двух GPU (без SLI!)
import torch
device1 = torch.device("cuda:0")
device2 = torch.device("cuda:1")
# DataParallel (самый простой способ)
model = torch.nn.DataParallel(model, device_ids=[0, 1])
# Или ручное распределение
part1 = model_part1.to(device1)
part2 = model_part2.to(device2)
💡 Что делать на практике:
1. Продать обе GTX 1070 и купить одну RTX 3060 12GB или RTX 4060 Ti 16GB:
· Получите больше памяти, доступной для одной модели.
· Получите Tensor Cores (ускорение в 3-5 раз для обучения).
· Упростите систему (меньше тепла, энергопотребления).
2. Если карты уже есть — используйте их без SLI, но будьте готовы:
· К ограничению размера модели 8 ГБ.
· К тому, что слабый CPU будет серьезно тормозить работу.
· К реальному ускорению только для задач, где большую часть времени занимают вычисления на GPU (не загрузка данных).
Итог: SLI бесполезен для ML. Две GTX 1070 можно использовать как независимые вычислители, но эффективность будет низкой из-за устаревшей платформы и отсутствия Tensor Cores. Апгрейд до одной современной карты — гораздо более разумное вложение.
Комментарий: человеческая жадность, как и желание скроить, безграничны. Смотрим, что из этого выйдет.
Я: Имеет смысл использование двух карт типа 3060 или 4060 на одной материнской плате?
DS: Да, имеет смысл, но с очень важными оговорками и условиями. Это уже гораздо более жизнеспособная конфигурация, чем с GTX 1070. Разберем детально.
✅Преимущества двух RTX 3060/4060:
1. Больше видеопамяти в сумме (но не объединенной!):
· Две RTX 3060 12GB дадут 24 ГБ суммарно (каждая со своей памятью).
· Две RTX 4060 Ti 16GB дадут фантастические 32 ГБ (в конфигурации за разумные деньги!).
· Это позволяет работать с огромными моделями, которые не помещаются в память одной карты (LLaMA 13B, большие варианты Stable Diffusion XL).
2. Наличие Tensor Cores:
· Обе карты имеют Tensor Cores 3-го/4-го поколения, что ускоряет обучение в смешанной точности (FP16/BF16) в разы по сравнению с GTX.
3. Реальная поддержка фреймворками:
· PyTorch и TensorFlow отлично работают с несколькими GPU через DataParallel (просто) или DistributedDataParallel (эффективнее).
⚠️ Критические ограничения и "подводные камни":
1. НЕТ объединения памяти (кроме очень специфичного случая)
· Главный миф: У вас не будет одного пула в 24/32 ГБ. Каждая модель/тензор должен помещаться в память одной карты (макс. 12/16 ГБ).
· Решения:
· Data Parallelism: Дублируете модель на все карты, каждая обрабатывает свой кусок данных.
· Model Parallelism (вручную): Разбиваете одну огромную модель между картами (сложно, может быть неэффективно).
· Pipeline Parallelism: Требует сложной настройки.
· Исключение: Начиная с RTX 4090/3090 есть NVLink, который частично позволяет объединять память. У 3060/4060 NVLink ОТСУТСТВУЕТ.
2. Бутылочное горлышко — PCIe и CPU
· Для вашей платформы AM3+ с FX-8320E это будет КАТАСТРОФА:
· PCIe 2.0 (очень старая) или PCIe 3.0 (медленная для такой связки).
· Процессор не будет успевать готовить данные для двух современных GPU. Вы не раскроете и 50% их потенциала.
· Материнка должна поддерживать разделение линий PCIe (например, x8/x8), что редкость для AM3+.
3. Проблемы с питанием и охлаждением
· Две карты потребляют 350-500 Вт. Нужен БП от 850 Вт качественный.
· Верхняя карта будет "задыхаться" в горячем воздухе от нижней. Нужен корпус с отличной вентиляцией.
📊 Сравнение конфигураций:
Конфигурация Плюсы Минусы Идеальное применение
1 × RTX 4060 Ti 16GB Простота, холодно, эффективно, вся память доступна сразу Макс. модель = 16 ГБ Большинство задач: обучение и инференс моделей до 16 ГБ
2 × RTX 3060 12GB Суммарно 24 ГБ, можно обучать/запускать очень большие модели (через Model Parallelism) Сложная настройка, нагрев, требуют мощный CPU и материнку Огромные модели, которые не влазят в 12-16 ГБ одной карты
2 × RTX 4060 Ti 16GB 32 ГБ суммарной памяти! Мощнейший вариант для любительского сегмента Очень дорого, проблемы с нагревом, экстремальные требования к БП и системе охлаждения Исследовательские задачи с гигантскими LLM, диффузионными моделями
💡 ПРАКТИЧЕСКИЕ РЕКОМЕНДАЦИИ:
Если у вас уже есть AM3+ и FX-8320E:
НЕ СТАВЬТЕ две RTX 3060/4060 на эту платформу! Вы выбросите деньги на ветер:
1. Процессор будет диким бутылочным горлышком.
2. PCIe 2.0/3.0 не даст картам нормально общаться.
3. Лучше потратить деньги на апгрейд всей платформы.
Правильный порядок апгрейда:
1. Сначала — новая платформа:
· Материнская плата B550/X570 (AM4) или B760/Z790 (LGA1700)
· Процессор: Ryzen 5 5600/5700X или Core i5-13400F/i5-13600K
· Оперативная память: 32-64 ГБ DDR4/DDR5
· Блок питания 750-850 Вт
2. Потом — одна мощная видеокарта (RTX 4070 Super 12GB, RTX 4070 Ti Super 16GB, RTX 4080 16GB).
3. И только потом, если действительно нужно — вторая карта.
Когда две карты ОПРАВДАНЫ:
· Вы работаете с моделями, которые физически не помещаются в память одной карты (например, LLM 30B+ параметров).
· Вы делаете параллельные эксперименты (на одной карте одна модель, на другой — другая).
· У вас уже есть максимально возможная single-GPU (типа RTX 4090), и нужно еще больше памяти для специфичных задач.
🔧 Технические требования для двухкарточной системы:
· Материнская плата с двумя PCIe x16 слотами (желательно PCIe 4.0 x8/x8).
· Мощный современный процессор (не менее 8 ядер, типа Ryzen7 5700X/7700).
· Огромный корпус с отличной вентиляцией (минимум 6 корпусных вентиляторов).
· Качественный БП 1000+ Вт (для двух RTX 4060 Ti) с отдельными кабелями для каждой карты.
Итог: Две RTX 3060/4060 имеют смысл только на современной платформе для специфических задач с большими моделями. Для 95% задач одна более мощная карта предпочтительнее. На вашей текущей платформе AM3+ это абсолютно нерационально — сначала нужно менять процессор, материнку и память.
Итогов беседы два: боль и унижение от собственного нищебродства и состояние абсолютного восторга от того, что может нейросеть. Китайсякая нейросеть, которая, мать её, пишет на прекрасном русском языке, кратко, лаконично, без ошибок и с легким стебом над потугами нищеброда. И даже в таком случае не топчет его ногами, предлагая выход из ситуации.
Другой вопрос – а где вот мне вообще дома применить возможности нейросетей?
Но! Я же человек, а поэтому эксперимент в описанном конфиге железа будет таки проведен. Да здравствуют боль, печаль и унижения. Следите за новостями )))