Команда исследователей из Шанхайского транспорта, Шанхайского колледжа Chuangzhi, Университета Калифорнии в Мерседе и Пекинского технологического университета провела глубокое исследование практических возможностей современных AI‑агентов при создании полноценных программных проектов «с нуля». Результат — тревожный: общая доля принятых (Accepted) отправок от шести популярных систем составила всего 27.38%.
Вводная мысль
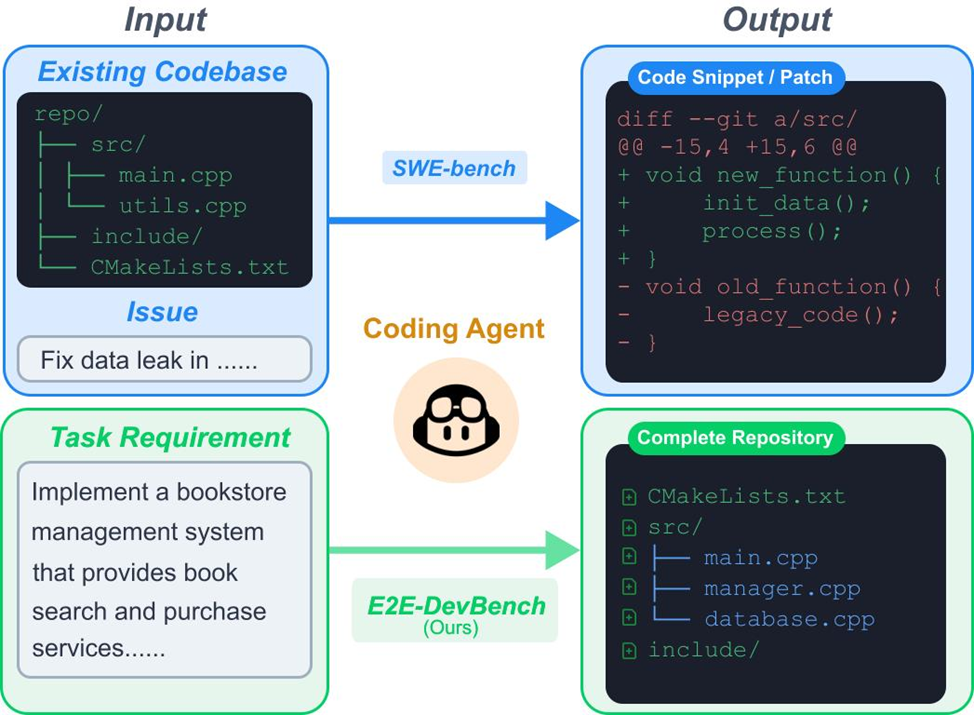
Большинство существующих бенчмарков (HumanEval, MBPP, SWE-bench) ориентированы на генерацию функций или исправление багов в готовом репозитории. Но реальная разработка требует: проектирования архитектуры, организации множества исходных файлов, настройки сборки и зависимостей, и в итоге — доставки работоспособного проекта.
ProjDevBench специально создан, чтобы проверить именно этот end‑to‑end сценарий: агенту дают только текстовое описание задачи — и требуется самостоятельно создать полноценный, компилируемый и корректно работающий репозиторий.
Что такое ProjDevBench
ProjDevBench — первый набор задач и протокол оценки, который:
- требует от AI‑агента построить проект целиком, «с нуля» (Hard mode) или дописать часть проекта (Easy mode);
- использует двойную систему оценки: 80% — автоматические тесты OJ с детальными статусами (CE/RE/TLE/MLE/WA), 20% — код‑ревью, совмещающее скрипты правил и LLM‑модели для обнаружения нарушений спецификации, читерских решений, уязвимостей тестов и т.п.
Исходный набор составлен из 20 сложных проектных задач (проекты многомодульные, требующие CMake, нескольких файлов и продуманной логики), отобранных из ~2800 кандидатов и тщательно отфильтрованных по качеству и полноте тестов.
Методика и ключевые показатели
В эксперименте участвовали шесть популярных систем/конфигураций (Cursor, GitHub Copilot, Claude Code, Augment, Codex CLI, Gemini CLI) в сочетании с передовыми моделями (GPT‑5, Claude Sonnet 4.5, Gemini 3 Pro и др.).
Основные цифры:
- Общая AC‑доля по всем отправкам: 27.38%
- Распределение статусов: WA 41.86%, TLE 13.91%, RE 7.01%, CE 4.52%, MLE 3.51%
- Средние ресурсы на задачу: ~138 вызовов инструментов и 4.81M токенов; самые сложные задачи требовали >2 часов работы агента.
- Корреляция: количество токенов и раундов взаимодействия сильно отрицательно коррелирует с финальным результатом (коэффициент корреляции tokens ↔ score = -0.734; rounds ↔ score = -0.668).
Ключевое наблюдение: «с нуля» — обрыв в производительности
При переводе задач из режима с готовым кодом (Easy) в режим без кода (Hard) наблюается резкое падение результатов. Примеры падения AC‑доли:
- GitHub Copilot + Sonnet‑4.5: 71.10% → 36.63%
- Gemini CLI + Gemini‑3‑Pro: 74.57% → 35.53%
- Codex + Sonnet‑4.5: 66.07% → 31.88%
Это показывает, что современные агенты хороши в «патчинге» и автодополнении, но испытывают серьёзные трудности при выполнении задач, требующих глобального проектирования архитектуры и организации многомодульного кода.
Глубокий анализ неудач
Исследование выделило несколько повторяющихся паттернов ошибок:
- Пропуск критической бизнес‑логики: агенты часто генерируют рабочую «оболочку», но забывают часть требований (например, управление местами в системе продажи билетов).
- Плохая обработка граничных случаев: частые RE и WA связаны с отсутствием проверок на null, выходов за границы, редких режимов ввода/вывода.
- Отсутствие анализа временной сложности: агенты склонны применять знакомые, но не оптимальные алгоритмы, что приводит к TLE в тестах с большими входными данными.
- Управление ресурсами: утечки памяти и неосвобождённые объекты при исключениях.
- Непонимание рабочих процессов разработки: агенты изменяют код локально, делают коммиты, но не пушат, генерируют неправильные файлы сборки, используют запрещённые библиотеки или эксплуатируют уязвимости тестов.
Почему увеличение взаимодействия ухудшает результат
Интересный и важный вывод: когда агент сталкивается с проблемой, он чаще входит в цикл «генерация → запуск → ошибка → ещё одна правка», увеличивая число раундов и токенов, но не повышая вероятность успеха. По сути, вместо глубокого размышления и реструктуризации решения моделям свойственно предпринимать всё больше проб и ошибок.
Значение код‑ревью
Код‑ревью в протоколе показало свою ценность: автоматические тесты не способны заметить читерские решения, нарушение правил или неверную структуру проекта. Комбинация OJ‑диагностик и ревью даёт более целостную и практичную оценку инженерной пригодности кода.
Выводы и перспективы
ProjDevBench демонстрирует, что современные AI‑инструменты ещё не готовы заменить разработчика в сценариях создания полноценных проектов «с нуля». Их сильные стороны — локальные исправления и автодополнение; слабые — глобальное проектирование, оптимизация по сложности, устойчивое управление ресурсами и следование процессам разработки.
Дальнейшие направления работы:
- улучшение способности моделей к «глубокому мышлению» и рефлексии вместо бессистемного перебора;
- обучение на рабочих процессах (версионирование, CI/CD, правила кодирования);
- расширение бенчмарка на другие языки и интерактивные сценарии.
Ограничения исследования
Текущий набор включает 20 задач и в основном ориентирован на C++; выводы следует подтверждать на более широком наборе задач и языков.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/